数据可视化基础专题(四):Pandas基础(三) mysql导入与导出
转载(有添加、修改)
作者:但盼风雨来_jc
链接:https://www.jianshu.com/p/238a13995b2b
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写。首先我们需要了解点ORM方面的知识
ORM技术
对象关系映射技术,即ORM(Object-Relational Mapping)技术,指的是把关系数据库的表结构映射到对象上,通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
在Python中,最有名的ORM框架是SQLAlchemy。Java中典型的ORM中间件有:Hibernate,ibatis,speedframework。
SQLAlchemy
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行
SQLAlchemy模块提供了create_engine()函数用来初始化数据库连接,SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
Pandas读写MySQL数据库
我们需要以下三个库来实现Pandas读写MySQL数据库:
- pandas
- sqlalchemy
- pymysql
其中,pandas模块提供了read_sql_query()函数实现了对数据库的查询,to_sql()函数实现了对数据库的写入。并不需要实现新建MySQL数据表。
sqlalchemy模块实现了与不同数据库的连接,而pymysql模块则使得Python能够操作MySQL数据库。
我们将使用MySQL数据库中的mydb数据库以及employee表,内容如下:
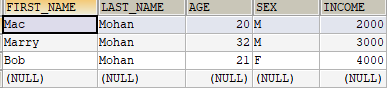
注意:
- 1.根据库的文档,我们看到to_sql函数支持两类mysql引擎一个是sqlalchemy,另一个是sqlliet3.没错,在你写入库的时候,pymysql是不能用的!!!
- mysqldb也是不能用的,你只能使用sqlalchemy或者sqlliet3!!鉴于sqllift3已经很久没有更新了,笔者这里建议使用sqlalchemy!!
- 2.to_sql函数并不在pd之中,而是在io.sql之中,是sql脚本下的一个类!!!所以to_sql的最好写法就是:
- pd.io.sql.to_sql(df1,tablename,con=conn,if_exists='repalce') qq_34685317的博客

1 import pandas as pd
2 from sqlalchemy import create_engine
3 # 初始化数据库连接,使用pymysql模块
4 # MySQL的用户:root, 密码:147369, 端口:3306,数据库:test
5 engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
6 # 查询语句,选出employee表中的所有数据
7 sql = ''' select * from employee; '''
8 # read_sql_query的两个参数: sql语句, 数据库连接
9 df = pd.read_sql_query(sql, engine)
10 # 输出employee表的查询结果
11 print(df)
12
13 # 新建pandas中的DataFrame, 只有id,num两列
14 df = pd.DataFrame({'id': [1, 2, 3, 4], 'name': ['zhangsan', 'lisi', 'wangwu', 'zhuliu']})
15 # 将新建的DataFrame储存为MySQL中的数据表,储存index列
16 df.to_sql('mydf', engine, index=True)
17 print('Read from and write to Mysql table successfully!')
运行结果:
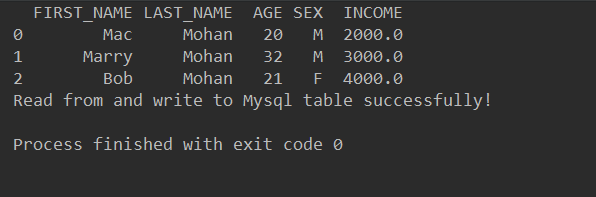
这说明我们确实将pandas中新建的DataFrame写入到了MySQL中!
将CSV文件写入到MySQL中
以上的例子实现了使用Pandas库实现MySQL数据库的读写,我们将再介绍一个实例:将CSV文件写入到MySQL中,示例的example.csv文件如下
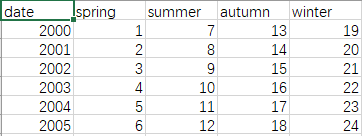
示例的Python代码如下:
1 # -*- coding: utf-8 -*-
2
3 # 导入必要模块
4 import pandas as pd
5 from sqlalchemy import create_engine
6
7 # 初始化数据库连接,使用pymysql模块
8 db_info = {'user': 'root',
9 'password': '123456',
10 'host': 'localhost',
11 'port': 3306,
12 'database': 'test'
13 }
14
15 engine = create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s:%(port)d/%(database)s?charset=utf8' % db_info, encoding='utf-8')
16 # 直接使用下一种形式也可以
17 # engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
18
19 # 读取本地CSV文件
20 df = pd.read_csv("C:/Users/fuqia/Desktop/example.csv", sep=',')
21 print(df)
22 # 将新建的DataFrame储存为MySQL中的数据表,不储存index列(index=False)
23 # if_exists:
24 # 1.fail:如果表存在,啥也不做
25 # 2.replace:如果表存在,删了表,再建立一个新表,把数据插入
26 # 3.append:如果表存在,把数据插入,如果表不存在创建一个表!!
27 pd.io.sql.to_sql(df, 'example', con=engine, index=False, if_exists='replace')
28 # df.to_sql('example', con=engine, if_exists='replace')这种形式也可以
29 print("Write to MySQL successfully!")
在MySQL中查看example表格
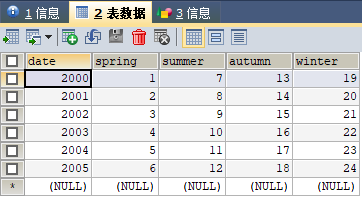
补充:engine.execute(sql)可以直接执行sql语句:
1 from sqlalchemy import create_engine
2
3
4 engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
5 sql = "DROP TABLE IF EXISTS example"
6 engine.execute(sql)
如果用pymysql,则必须用cursor,读者可以对比一下。
1 import pymysql
2 from sqlalchemy import create_engine
3
4 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='test')
5 # engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test')
6 sql = "DROP TABLE IF EXISTS test_input"
7 cursor = conn.cursor()
8 cursor.execute(sql)
总结
本文主要介绍了ORM技术以及SQLAlchemy模块,并且展示了两个Python程序的实例,介绍了如何使用Pandas库实现MySQL数据库的读写。
程序本身并不难,关键在于多多练习
数据可视化基础专题(四):Pandas基础(三) mysql导入与导出的更多相关文章
- [独孤九剑]Oracle知识点梳理(三)导入、导出
本系列链接导航: [独孤九剑]Oracle知识点梳理(一)表空间.用户 [独孤九剑]Oracle知识点梳理(二)数据库的连接 [独孤九剑]Oracle知识点梳理(三)导入.导出 [独孤九剑]Oracl ...
- mysql导入和导出数据
Linux下如何单个库进行导入和备份操作 1.将数据导入数据库mysql -u账号 -p密码 数据库<sql脚本 mysql -uroot -proot test</home/upload ...
- 数据可视化之powerBI基础(十二)PowerBI导入Excel数据有哪几种方式?
https://zhuanlan.zhihu.com/p/64999937 Excel作为使用最频繁.应用最广泛.用户最庞大的数据处理工具,当然也应该是PowerBI最常用的数据获取方式,本文介绍一下 ...
- 前端er必须掌握的数据可视化技术
又是一月结束,打工人准时准点的汇报工作如期和大家见面啦.提到汇报,必不可少的一部分就是数据的汇总.分析. 作为一名合格的社会人,我们每天都在工作.生活.学习中和数字打交道.小到量化的工作内容,大到具体 ...
- Oracle 数据的导入和导出(SID service.msc)
一:版本号说明: (1)(Oracle11 32位系统)Oracle - OraDb11g_home1: (2)成功安装后显演示样例如以下:第一个图是管理工具.创建连接.创建表:第二个是数据库创建工 ...
- 小白学 Python 数据分析(5):Pandas (四)基础操作(1)查看数据
在家为国家做贡献太无聊,不如跟我一起学点 Python 人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Panda ...
- Python数据可视化基础讲解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:爱数据学习社 首先,要知道我们用哪些库来画图? matplotlib ...
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- 「kuangbin带你飞」专题十四 数论基础
layout: post title: 「kuangbin带你飞」专题十四 数论基础 author: "luowentaoaa" catalog: true tags: mathj ...
随机推荐
- 如何安装 Sublime text 编辑器相关的插件
Sublime是一个伟大的编辑器,具有可靠的基础功能,使编写代码变得愉快.您可以安装一个包管理器,以便于安装插件和添加新功能. 为什么使用包管理器(package manager) 包管理器可以方便地 ...
- Java 多线程基础(五)线程同步
Java 多线程基础(五)线程同步 当我们使用多个线程访问同一资源的时候,且多个线程中对资源有写的操作,就容易出现线程安全问题. 要解决上述多线程并发访问一个资源的安全性问题,Java中提供了同步机制 ...
- Sequence in the Pocket【思维+规律】
Sequence in the Pocket 题目链接(点击) DreamGrid has just found an integer sequence in his right pocket. A ...
- MSCHART控件中长字符的X轴坐标标注全部显示
X轴坐标如果超过9位的话,就不能完全显示了,就会一个隔一个的显示,解决的办法: Chart1.ChartAreas[].AxisX.Interval = ; //设置X轴坐标的间隔为1 Chart1. ...
- range用法(倒序取值)
range(4,-1,-1) #倒数取值 ''' start: 计数从 start 开始.默认是从 0 开始.例如range(5)等价于range(0, 5); stop: 计数到 stop 结束,但 ...
- MongoDB 逻辑备份工具mongodump
mongodump是官方提供的一个对数据库进行逻辑导出的备份工具,导出文件为BSON二进制格式,无法使用文本编辑工具直接查看.mongodump可以导出mongod或者mongos实例的数据,从集群模 ...
- 阿里云Ubuntu配置mysql+navicat连接
一>mysql安装配置(工具:Xshell6) 1.安装mysql apt-get install mysql-server mysql-client 2.查看安装:查看版本 sudo ...
- SpringBoot — HelloWorld开发部署
springboot官方推荐使用jdk1.8 一.配置pom.xml 二.Application.java 三.HelloController.java 四.项目运行: Application.jav ...
- android 6.0 以上在doze模式精确定时
public static void start12hAlarm() { int seconds = TIMERLENGTH; ECMLog.i_ecms(CLASS_TAG, " star ...
- ArrayList类的使用
ArrayList常用类方法 (1)添加元素 public boolean add(E element) 在集合末端添加一个元素 public void add(int index,E element ...