JAVA高并发集合详解
- Queue(队列)
主要是为了高并发准备的容器
Deque:双端队列,可以反方向装或者取 - 最开始jdk1.0只有Vector和hashtable 默认所有方法都实现了synchronized锁,线程安全但性能比较差,因此后续SUN意识到这个问题之后加了完全没加锁的hashmap,但是由于Hashmap完全没锁,SUN又想到能不能让Hashmap在有锁的时候用呢,此时添加了Collection,里面有一个Collection.synchronizedMap(new HashMap()),将Hashmap变成了加锁的版本,里面锁的粒度变小了,能部分提高性能,在JUC之后,新出来了ConcurrentHashtable由于Hashtable和Vectoy是古老的版本带过来的,所以现在基本不用,知道就行。
1、HashTable性能测试
public class Constants {
public static final int COUNT = 1000000;
public static final int THREAD_COUNT = 100;
}public class T01_TestHashtable {
static Hashtable<UUID, UUID> m = new Hashtable<>();
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
}相对来说,插入的时候ConcurrentHashMap相对于HashMap效率没有明显提高,但是读取的时候效率高很多。
- ConcurrentSkipListMap 跳表结构,由于CAS在Tree这种结构上操作太复杂,然后冒出了跳表这种结构,底层时链表,为了查找效率,提取关键元素,制作新的链表,找的时候先找11->78,发现元素比78小,则与11比较,如果大,则在11-78中找,明显效率提高了。
跳表: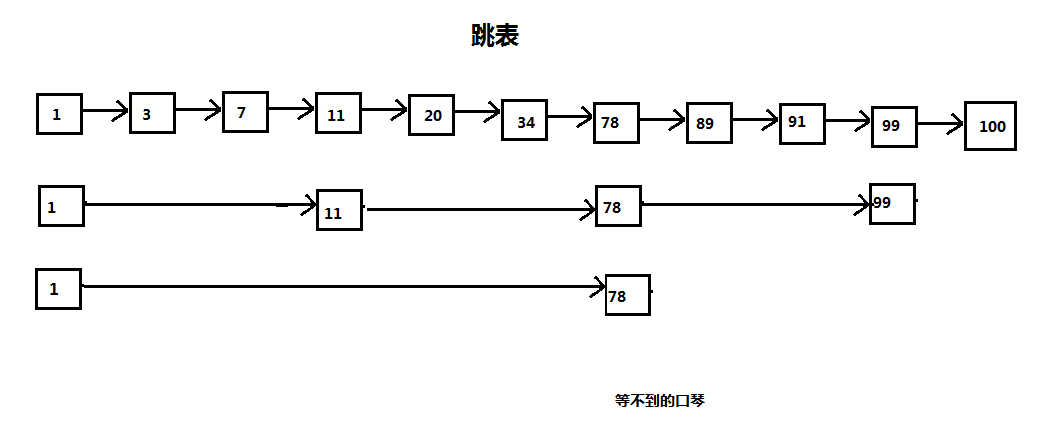
- 多线程尽量使用Queue,少用List、Set
- CopyOnWrite,写时复制,读的时候不加锁,写的时候加锁,原理是:会在原来基础上Copy一个出来数组,在新的数组上写,写完后将引用指向新数组,过程中读的时候读的是原来数组,当写的过程结束之后读得是新数组,写时复制
- CopyOnWriteArrayList,写(添加)的时候是加了锁的,里面先获取原数组的长度,创建新数组长度为原数组+1,读(get)的时候是加了锁的
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}public E get(int index) {
return get(getArray(), index);
} - BlockingQueue 为线程池做准备,重点在blocking上,阻塞队列,有很多对多线程友好的方法。
1、常用的一共三种,分别是无界的LinkedBlockingQueue(表示用Linked实现是,无界,除非内存溢出,添加方法put的区别是,put方法非要添加,如果满了就阻塞住,取方法 take(),非要取,如果没有了就阻塞,阻塞的原理就是实现了park(),线程阻塞住,进入wait状态)、
2、有界的ArrayBlockingQueue(表示用Array实现是,有界,除非内存溢出,满了之后程序会阻塞住,等消费者)、
3、DelayQueue(实现时间上的排序)、
4、synchronusQueue(实现线程中间传输内容、任务)、
5、TransferQueue(是前面几种的组合,也可以传输任务,并且不是传递一个,可以传递多个) - ConcurrentLinkedQueue
里面一些友好的方法添加 offer()(返回值是Boolean类型,true表示成功,)、peak()(取) - Queue 与 List的区别,主要在于Queue添加了很多对线程友好的API,比如offer peek poll
这其中一个子类BlockingQueue在上面(offer peek poll)的基础上添加了put take ->主要是实现了阻塞,可以自然而然的实现任务队列,也就是生产者、消费者模型,这是多线程中最重要的模型,是MQ的基础(必问内容) - DelayQueue,可以实现等待时间,类实现Delayed接口,同时设置运行时间runningtime,时间等待越短的优先运行,实现Compare接口,重写方法来确定任务执行队列
按时间进行任务调度。本质是priorityQueue。
static BlockingQueue<MyTask> tasks = new DelayQueue<>(); static Random r = new Random(); static class MyTask implements Delayed {
String name;
long runningTime; MyTask(String name, long rt) {
this.name = name;
this.runningTime = rt;
} @Override
public int compareTo(Delayed o) {
if(this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS))
return -1;
else if(this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS))
return 1;
else
return 0;
} @Override
public long getDelay(TimeUnit unit) { return unit.convert(runningTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
} @Override
public String toString() {
return name + " " + runningTime;
}
}main方法:
public static void main(String[] args) throws InterruptedException {
long now = System.currentTimeMillis();
MyTask t1 = new MyTask("t1", now + 1000);
MyTask t2 = new MyTask("t2", now + 2000);
MyTask t3 = new MyTask("t3", now + 1500);
MyTask t4 = new MyTask("t4", now + 2500);
MyTask t5 = new MyTask("t5", now + 500); tasks.put(t1);
tasks.put(t2);
tasks.put(t3);
tasks.put(t4);
tasks.put(t5); System.out.println(tasks); for(int i=0; i<5; i++) {
System.out.println(tasks.take());
}
}结果:
t5 1587472415617
t1 1587472416117
t3 1587472416617
t2 1587472417117
t4 1587472417617 - PriorityQueue,会默认对任务排序,最小最优先,里面是小顶堆
Demo:
public class T07_01_PriorityQueque {
public static void main(String[] args) {
PriorityQueue<String> q = new PriorityQueue<>();
q.add("c");
q.add("e");
q.add("a");
q.add("d");
q.add("z");
for (int i = 0; i < 5; i++) {
System.out.println(q.poll());
}
}
}
//打印结果:a、c、d、e、z - synchronusQueue,容量为0,不是用来装东西,主要是用来一个线程给另一个线程下达任务,与之前的exchanger容器类似,不可以用add方法,里面容器为0,不可以装东西。应用场景是:做某件事需要等待结果完成才继续执行接下来的任务。
JAVA高并发集合详解的更多相关文章
- 《JAVA高并发编程详解》-七种单例模式
- 《JAVA高并发编程详解》-volatile和synchronized
- 《JAVA高并发编程详解》-并发编程有三个至关重要的特性:原子性,有序性,可见性
- 《JAVA高并发编程详解》-类的加载过程简介
- 《JAVA高并发编程详解》-wait和sleep
- 《JAVA高并发编程详解》-程序可能出现死锁的场景
- 《JAVA高并发编程详解》-Thread start方法的源码
Thread start方法的源码:
- 《JAVA高并发编程详解》-Thread对象的启动
当我们用关键字new创建一个Thread对象时,此时它并不处于执行状态,因为没有调用start方法启动该线程,那么线程的状态为NEW状态,NEW状态通过start方法进入RUNNABLE状态. 线程一 ...
- Java中的集合详解及代码测试
1:对象数组 (1)数组既可以存储基本数据类型,也可以存储引用类型.它存储引用类型的时候的数组就叫对象数组. 2:集合(Collection) (1)集合的由来 我们学习的是Java -- 面向对象 ...
随机推荐
- Python利用xlutils统计excel表格数据
假设有像上这样一个表格,里面装满了各式各样的数据,现在要利用模板对它进行统计每个销售商的一些数据的总和.模板如下: 代码开始: 1 #!usr/bin/python3 2 # -*-coding=ut ...
- iOS常见遍历方法汇总
一.for循环 NSArray *iosArray = @[@"L", @"O", @"V", @"E", @" ...
- NET 5使用gRPC
gRPC 是一种与语言无关的高性能远程过程调用 (RPC) 框架. https://grpc.io/docs/guides/ https://github.com/grpc/grpc-dotnet h ...
- 详解Vue中的插槽
作者: 小土豆 博客园:https://www.cnblogs.com/HouJiao/ 掘金:https://juejin.im/user/2436173500265335 什么是插槽 在日常的项目 ...
- git使用上
因为最近工作上多处都用到了基于 Git 的开发,需要深入理解 Git 的工作原理,以往的 Git 基本知识已经满足不了需求了,因此写下这篇 Git 进阶的文章,主要是介绍了一些大家平时会碰到但是很少去 ...
- 讲两个int 数组找出重复的数字 用最少的循环
int a[] = {1,3}; int b[] = {1,3,5}; int size = a.length>b.length ?a.length:b.length; int valueA = ...
- leetcode 274H-index
public int hIndex(int[] citations) { /* 唠唠叨叨说了很多 其实找到一个数h,使得数组中至少有h个数大于等于这个数, 其他N-h个数小于这个数,h可能有多个,求最 ...
- udp聊天室--简易
package 聊天; /*一切随便消逝吧*/ import java.net.DatagramSocket; import java.net.SocketException; public clas ...
- 学习DOS,个人笔记
在win中\表示根目录, 在linux中/表示根目录 注意: 有些家庭版的系统会选择性的调用命令的,有的命令虽然有那个文件,但是不能使用..... dir 命令 英语全称 ...
- 一行 CSS 代码的魅力
之前在知乎看到一个很有意思的讨论 一行代码可以做什么? 那么,一行 CSS 代码又能不能搞点事情呢? CSS Battle 首先,这让我想到了,年初的时候沉迷的一个网站 CSS Battle .这个网 ...