go-zero 如何应对海量定时/延迟任务?
一个系统中存在着大量的调度任务,同时调度任务存在时间的滞后性,而大量的调度任务如果每一个都使用自己的调度器来管理任务的生命周期的话,浪费cpu的资源而且很低效。
本文来介绍 go-zero 中 延迟操作,它可能让开发者调度多个任务时,只需关注具体的业务执行函数和执行时间「立即或者延迟」。而 延迟操作,通常可以采用两个方案:
Timer:定时器维护一个优先队列,到时间点执行,然后把需要执行的 task 存储在 map 中collection中的timingWheel,维护一个存放任务组的数组,每一个槽都维护一个存储task的双向链表。开始执行时,计时器每隔指定时间执行一个槽里面的tasks。
方案2把维护task从 优先队列 O(nlog(n)) 降到 双向链表 O(1),而执行task也只要轮询一个时间点的tasks O(N),不需要像优先队列,放入和删除元素 O(nlog(n))。
我们先看看 go-zero 中自己对 timingWheel 的使用 :
cache 中的 timingWheel
首先我们先来在 collection 的 cache 中关于 timingWheel 的使用:
timingWheel, err := NewTimingWheel(time.Second, slots, func(k, v interface{}) {
key, ok := k.(string)
if !ok {
return
}
cache.Del(key)
})
if err != nil {
return nil, err
}
cache.timingWheel = timingWheel
这是 cache 初始化中也同时初始化 timingWheel 做key的过期处理,参数依次代表:
interval:时间划分刻度numSlots:时间槽execute:时间点执行函数
在 cache 中执行函数则是 删除过期key,而这个过期则由 timingWheel 来控制推进时间。
接下来,就通过 cache 对 timingWheel 的使用来认识。
初始化
// 真正做初始化
func newTimingWheelWithClock(interval time.Duration, numSlots int, execute Execute, ticker timex.Ticker) (
*TimingWheel, error) {
tw := &TimingWheel{
interval: interval, // 单个时间格时间间隔
ticker: ticker, // 定时器,做时间推动,以interval为单位推进
slots: make([]*list.List, numSlots), // 时间轮
timers: NewSafeMap(), // 存储task{key, value}的map [执行execute所需要的参数]
tickedPos: numSlots - 1, // at previous virtual circle
execute: execute, // 执行函数
numSlots: numSlots, // 初始化 slots num
setChannel: make(chan timingEntry), // 以下几个channel是做task传递的
moveChannel: make(chan baseEntry),
removeChannel: make(chan interface{}),
drainChannel: make(chan func(key, value interface{})),
stopChannel: make(chan lang.PlaceholderType),
}
// 把 slot 中存储的 list 全部准备好
tw.initSlots()
// 开启异步协程,使用 channel 来做task通信和传递
go tw.run()
return tw, nil
}
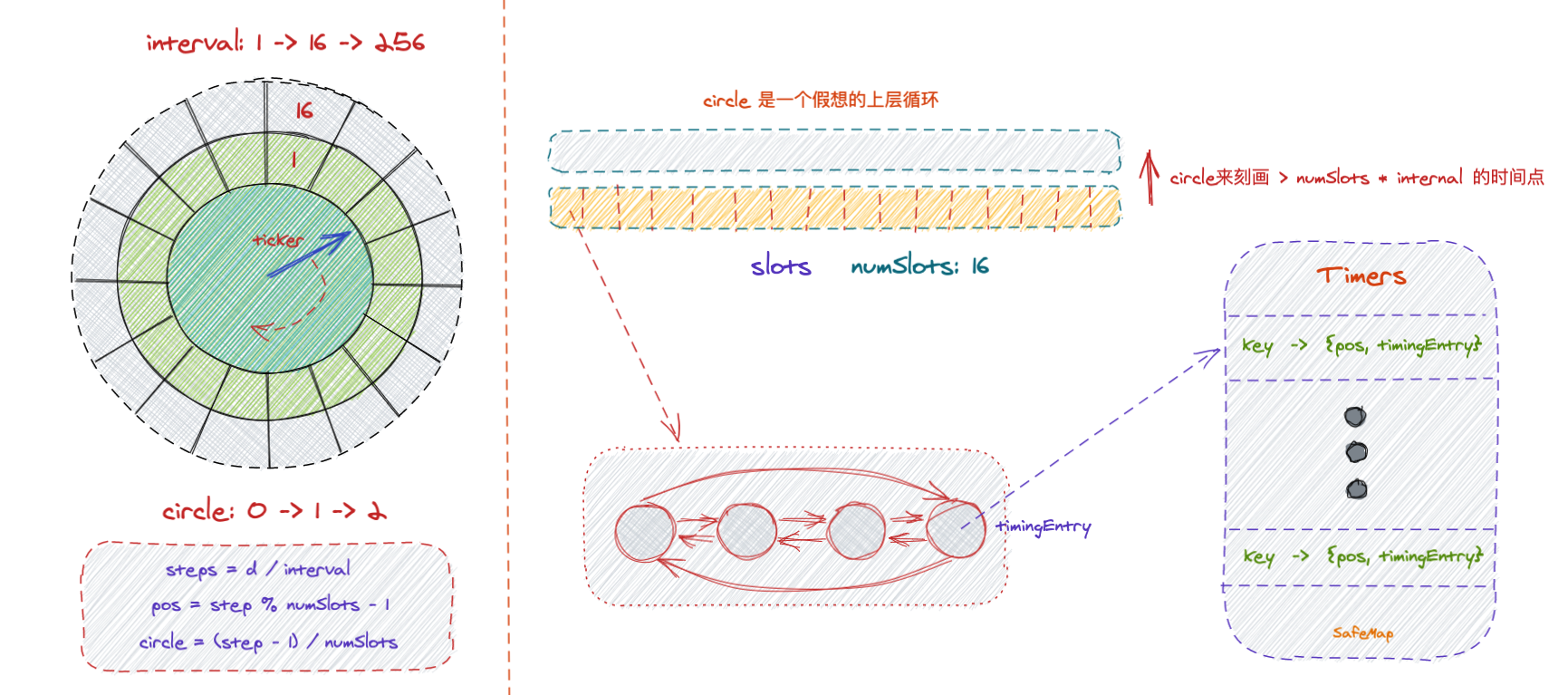
以上比较直观展示 timingWheel 的 “时间轮”,后面会围绕这张图解释其中推进的细节。
go tw.run() 开一个协程做时间推动:
func (tw *TimingWheel) run() {
for {
select {
// 定时器做时间推动 -> scanAndRunTasks()
case <-tw.ticker.Chan():
tw.onTick()
// add task 会往 setChannel 输入task
case task := <-tw.setChannel:
tw.setTask(&task)
...
}
}
}
可以看出,在初始化的时候就开始了 timer 执行,并以internal时间段转动,然后底层不停的获取来自 slot 中的 list 的task,交给 execute 执行。
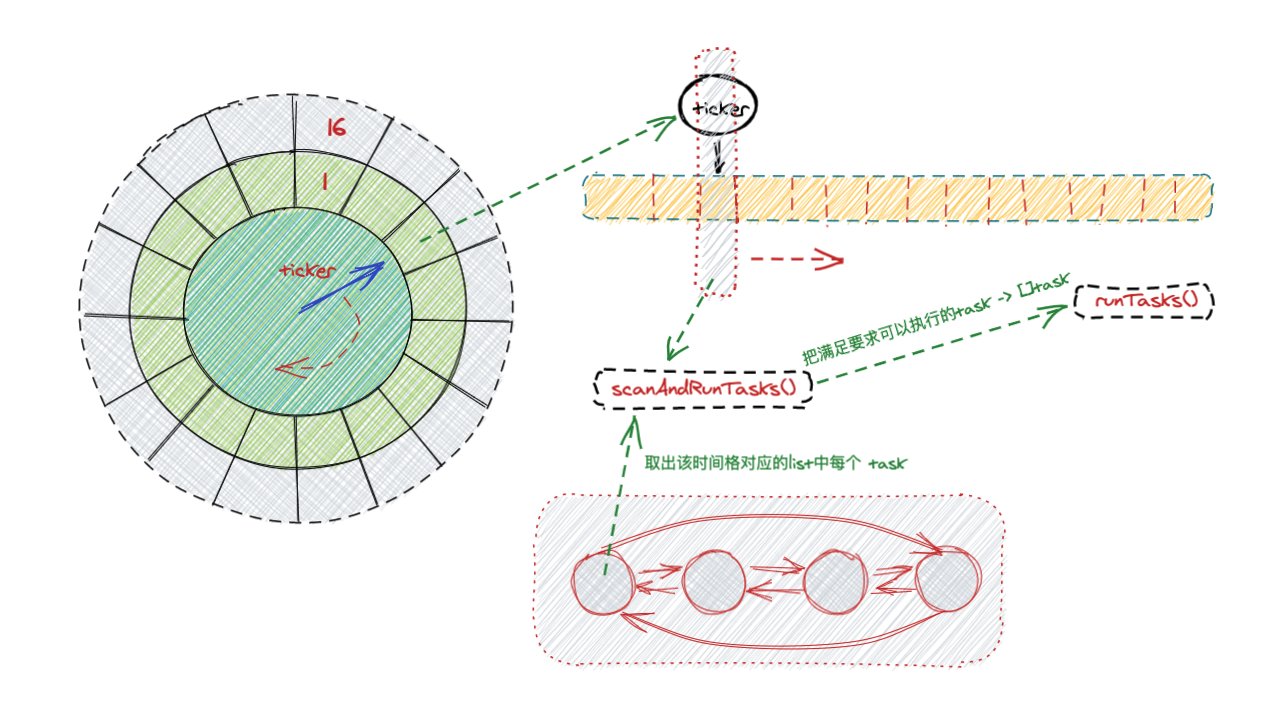
Task Operation
紧接着就是设置 cache key :
func (c *Cache) Set(key string, value interface{}) {
c.lock.Lock()
_, ok := c.data[key]
c.data[key] = value
c.lruCache.add(key)
c.lock.Unlock()
expiry := c.unstableExpiry.AroundDuration(c.expire)
if ok {
c.timingWheel.MoveTimer(key, expiry)
} else {
c.timingWheel.SetTimer(key, value, expiry)
}
}
- 先看在
data map中有没有存在这个key - 存在,则更新
expire->MoveTimer() - 第一次设置key ->
SetTimer()
所以对于 timingWheel 的使用上就清晰了,开发者根据需求可以 add 或是 update。
同时我们跟源码进去会发现:SetTimer() MoveTimer() 都是将task输送到channel,由 run() 中开启的协程不断取出 channel 的task操作。
SetTimer() -> setTask():
- not exist task:
getPostion -> pushBack to list -> setPosition- exist task:
get from timers -> moveTask()
MoveTimer() -> moveTask()
由上面的调用链,有一个都会调用的函数:moveTask()
func (tw *TimingWheel) moveTask(task baseEntry) {
// timers: Map => 通过key获取 [positionEntry「pos, task」]
val, ok := tw.timers.Get(task.key)
if !ok {
return
}
timer := val.(*positionEntry)
// {delay < interval} => 延迟时间比一个时间格间隔还小,没有更小的刻度,说明任务应该立即执行
if task.delay < tw.interval {
threading.GoSafe(func() {
tw.execute(timer.item.key, timer.item.value)
})
return
}
// 如果 > interval,则通过 延迟时间delay 计算其出时间轮中的 new pos, circle
pos, circle := tw.getPositionAndCircle(task.delay)
if pos >= timer.pos {
timer.item.circle = circle
// 记录前后的移动offset。为了后面过程重新入队
timer.item.diff = pos - timer.pos
} else if circle > 0 {
// 转移到下一层,将 circle 转换为 diff 一部分
circle--
timer.item.circle = circle
// 因为是一个数组,要加上 numSlots [也就是相当于要走到下一层]
timer.item.diff = tw.numSlots + pos - timer.pos
} else {
// 如果 offset 提前了,此时 task 也还在第一层
// 标记删除老的 task,并重新入队,等待被执行
timer.item.removed = true
newItem := &timingEntry{
baseEntry: task,
value: timer.item.value,
}
tw.slots[pos].PushBack(newItem)
tw.setTimerPosition(pos, newItem)
}
}
以上过程有以下几种情况:
delay < internal:因为 < 单个时间精度,表示这个任务已经过期,需要马上执行- 针对改变的
delay:new >= old:<newPos, newCircle, diff>newCircle > 0:计算diff,并将 circle 转换为 下一层,故diff + numslots- 如果只是单纯延迟时间缩短,则将老的task标记删除,重新加入list,等待下一轮loop被execute
Execute
之前在初始化中,run() 中定时器的不断推进,推进的过程主要就是把 list中的 task 传给执行的 execute func。我们从定时器的执行开始看:
// 定时器 「每隔 internal 会执行一次」
func (tw *TimingWheel) onTick() {
// 每次执行更新一下当前执行 tick 位置
tw.tickedPos = (tw.tickedPos + 1) % tw.numSlots
// 获取此时 tick位置 中的存储task的双向链表
l := tw.slots[tw.tickedPos]
tw.scanAndRunTasks(l)
}
紧接着是如何去执行 execute:
func (tw *TimingWheel) scanAndRunTasks(l *list.List) {
// 存储目前需要执行的task{key, value} [execute所需要的参数,依次传递给execute执行]
var tasks []timingTask
for e := l.Front(); e != nil; {
task := e.Value.(*timingEntry)
// 标记删除,在 scan 中做真正的删除 「删除map的data」
if task.removed {
next := e.Next()
l.Remove(e)
tw.timers.Del(task.key)
e = next
continue
} else if task.circle > 0 {
// 当前执行点已经过期,但是同时不在第一层,所以当前层即然已经完成了,就会降到下一层
// 但是并没有修改 pos
task.circle--
e = e.Next()
continue
} else if task.diff > 0 {
// 因为之前已经标注了diff,需要再进入队列
next := e.Next()
l.Remove(e)
pos := (tw.tickedPos + task.diff) % tw.numSlots
tw.slots[pos].PushBack(task)
tw.setTimerPosition(pos, task)
task.diff = 0
e = next
continue
}
// 以上的情况都是不能执行的情况,能够执行的会被加入tasks中
tasks = append(tasks, timingTask{
key: task.key,
value: task.value,
})
next := e.Next()
l.Remove(e)
tw.timers.Del(task.key)
e = next
}
// for range tasks,然后把每个 task->execute 执行即可
tw.runTasks(tasks)
}
具体的分支情况在注释中说明了,在看的时候可以和前面的 moveTask() 结合起来,其中 circle 下降,diff 的计算是关联两个函数的重点。
至于 diff 计算就涉及到 pos, circle 的计算:
// interval: 4min, d: 60min, numSlots: 16, tickedPos = 15
// step = 15, pos = 14, circle = 0
func (tw *TimingWheel) getPositionAndCircle(d time.Duration) (pos int, circle int) {
steps := int(d / tw.interval)
pos = (tw.tickedPos + steps) % tw.numSlots
circle = (steps - 1) / tw.numSlots
return
}
上面的过程可以简化成下面:
steps = d / interval
pos = step % numSlots - 1
circle = (step - 1) / numSlots
总结
timingWheel靠定时器推动,时间前进的同时会取出当前时间格中list「双向链表」的task,传递到execute中执行。因为是是靠internal固定时间刻度推进,可能就会出现:一个 60s 的task,internal = 1s,这样就会空跑59次loop。而在扩展时间上,采取
circle分层,这样就可以不断复用原有的numSlots,因为定时器在不断loop,而执行可以把上层的slot下降到下层,在不断loop中就可以执行到上层的task。这样的设计可以在不创造额外的数据结构,突破长时间的限制。
同时在
go-zero中还有很多实用的组件工具,用好工具对于提升服务性能和开发效率都有很大的帮助,希望本篇文章能给大家带来一些收获。
项目地址
https://github.com/tal-tech/go-zero
好未来技术
go-zero 如何应对海量定时/延迟任务?的更多相关文章
- “军装照”背后——天天P图如何应对10亿流量的后台承载。
WeTest 导读 天天P图"军装照"活动交出了一份10亿浏览量的答卷,一时间刷屏朋友圈,看到这幕,是不是特别想复制一个如此成功的H5?不过本文不教你如何做一个爆款H5,而是介绍天 ...
- 全面解密QQ红包技术方案:架构、技术实现、移动端优化、创新玩法等
本文来自腾讯QQ技术团队工程师许灵锋.周海发的技术分享. 一.引言 自 2015 年春节以来,QQ 春节红包经历了企业红包(2015 年).刷一刷红包(2016 年)和 AR 红包(2017 年)几个 ...
- ElasticSearch + Canal 开发千万级的实时搜索系统
公司是做社交相关产品的,社交类产品对搜索功能需求要求就比较高,需要根据用户城市.用户ID昵称等进行搜索. 项目原先的搜索接口采用SQL查询的方式实现,数据库表采用了按城市分表的方式.但随着业务的发展, ...
- Web 建站技术中,HTML、HTML5、XHTML、CSS、SQL、JavaScript、PHP、ASP.NET、Web Services 是什么(转)
Web 建站技术中,HTML.HTML5.XHTML.CSS.SQL.JavaScript.PHP.ASP.NET.Web Services 是什么?修改 建站有很多技术,如 HTML.HTML5.X ...
- 关于Mongodb的全面总结
MongoDB的内部构造<MongoDB The Definitive Guide> MongoDB的官方文档基本是how to do的介绍,而关于how it worked却少之又少,本 ...
- ElasticSearch + Canal 开发千万级的实时搜索系统【转】
公司是做社交相关产品的,社交类产品对搜索功能需求要求就比较高,需要根据用户城市.用户ID昵称等进行搜索. 项目原先的搜索接口采用SQL查询的方式实现,数据库表采用了按城市分表的方式.但随着业务的发展, ...
- 基于消息队列 RocketMQ 的大型分布式应用上云最佳实践
作者|绍舒 审核&校对:岁月.佳佳 编辑&排版:雯燕 前言 消息队列是分布式互联网架构的重要基础设施,在以下场景都有着重要的应用: 应用解耦 削峰填谷 异步通知 分布式事务 大数据处理 ...
- 网络协议学习笔记(四)传输层的UDP和TCP
概述 传输层里比较重要的两个协议,一个是 TCP,一个是 UDP.对于不从事底层开发的人员来讲,或者对于开发应用的人来讲,最常用的就是这两个协议.由于面试的时候,这两个协议经常会被放在一起问,因而我在 ...
- 过年7天乐,学nodejs 也快乐
自从上次接触nodejs 已经好长时间了,但是年底公司太忙了 ,没时间看, 上次文章在ubuntu上安装nodejs[开启实时web时代] http://www.cnblogs.com/qqlovin ...
随机推荐
- ZT:做一个连自己都羡慕的人
当你越来越杰出时,自然有人关注你, 当你越来越有能力时,自然会有人看得起你, 改变自己,你才有自信,梦想才会慢慢的实现. 做最好的自己,懒可以毁掉一个人,勤可以激发一个人! 不要等夕阳西下的时候才对自 ...
- IOException的子类
ChangedCharSetException, CharacterCodingException, CharConversionException, ClosedChannelException, ...
- linux基础一(目录结构)
一.linux目录结构 1.根目录/下 bin:用户二进制文件,常用命令都在此目录下 sbin;这个目录下的linux命令通常由系统管理员使用 etc:包含所有程序所需的配置文件,以及服务的启动文件 ...
- C的文件操作---笔记
打开文件 FILE *fp = fopen(char *filename, char *mode) 关闭文件 fclose(fp) 字符形式读 char ch = fgetc(fp) 字符形式写 ...
- JVM强引用、软引用、弱引用、虚引用、终结器引用垃圾回收行为总结
JVM引用 我们希望能描述这样一类对象: 当内存空间还足够时,则能保留在内存中:如果内存空间在进行垃圾收集后还是很紧张,则可以抛弃这些对象. -[既偏门又非常高频的面试题]强引用.软引用.弱引用.虚引 ...
- day53:django:URL别名/反向解析&URL分发&命名空间&ORM多表操作修改/查询
目录 1.URL别名&反向解析 2.URL分发&命名空间 3.ORM多表操作-修改 4.ORM多表操作-查询 4.1 基于对象的跨表查询 4.2 基于双下划线的跨表查询 4.3 聚合查 ...
- Arnold变换(猫脸变换)
Arnold变换是Arnold在遍历理论研究中提出的一种变换.由于Arnold本人最初对一张猫的图片进行了此种变换,因此它又被称为猫脸变换.Arnold变换可以对图像进行置乱,使得原本有意义的图像变成 ...
- 自己实现一个 DFA 串模式识别器(二)
正规表达式的实现原理 上文讨论了串的模式的表达,即正规表达式.那么这一小节将讨论我们实现一个正规表达式的方法和原理.因为我们知道,一个正规表达式对应着一个串模式,而一个串模式又对应着一些列符合该模 ...
- Anaconda使用及管理
接下来均是以命令行模式进行介绍,Windows用户请打开"Anaconda Prompt":macOS和Linux用户请打开"Terminal"("终 ...
- 一文读懂MySQL的索引结构及查询优化
回顾前文: 一文学会MySQL的explain工具 (同时再次强调,这几篇关于MySQL的探究都是基于5.7版本,相关总结与结论不一定适用于其他版本) MySQL官方文档中(https://dev.m ...