深入理解RabbitMQ中的prefetch_count参数
![]()
前提
在某一次用户标签服务中大量用到异步流程,使用了RabbitMQ进行解耦。其中,为了提高消费者的处理效率针对了不同节点任务的消费者线程数和prefetch_count参数都做了调整和测试,得到一个相对合理的组合。这里深入分析一下prefetch_count参数在RabbitMQ中的作用。
prefetch_count参数的含义
先从AMQP(Advanced Message Queuing Protocol,即高级消息队列协议,RabbitMQ实现了此协议的0-9-1版本的大部分内容)和RabbitMQ的具体实现去理解prefetch_count参数的含义,可以查阅对应的文档(见文末参考资料)。AMQP 0-9-1定义了basic.qos方法去限制消费者基于某一个Channel或者Connection上未进行ack的最大消息数量上限。basic.qos方法支持两个参数:
global:布尔值。prefetch_count:整数。
这两个参数在AMQP 0-9-1定义中的含义和RabbitMQ具体实现时有所不同,见下表:
global参数值 |
AMQP 0-9-1中prefetch_count参数的含义 |
RabbitMQ中prefetch_count参数的含义 |
|---|---|---|
false |
prefetch_count值在当前Channel的所有消费者共享 |
prefetch_count对于基于当前Channel创建的消费者生效 |
true |
prefetch_count值在当前Connection的所有消费者共享 |
prefetch_count值在当前Channel的所有消费者共享 |
或者用简洁的英文表格理解:
global |
prefetch_count in AMQP 0-9-1 |
prefetch_count in RabbitMQ |
|---|---|---|
false |
Per channel limit |
Per customer limit |
true |
Per connection limit |
Per channel limit |
这里画一个图理解一下:
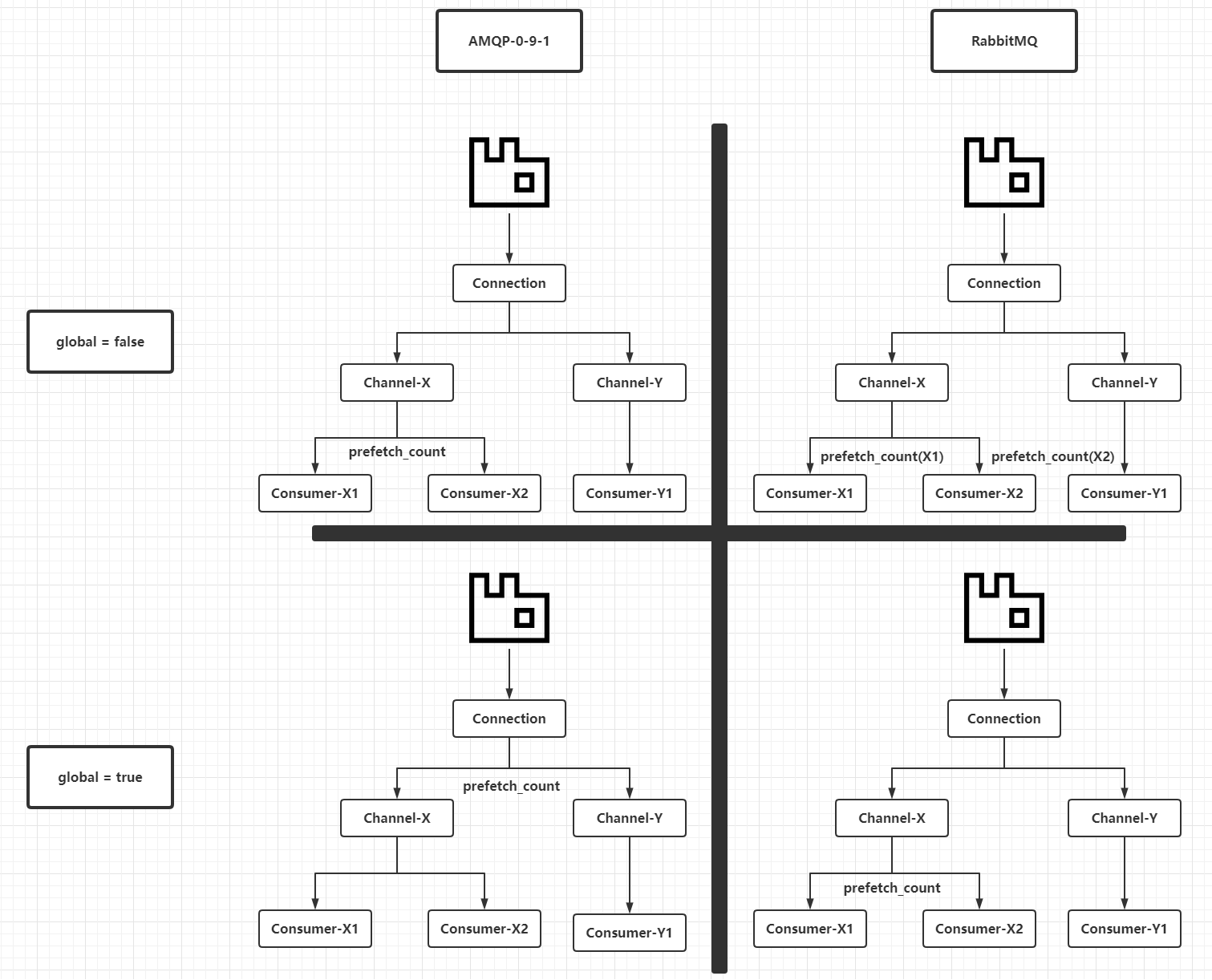
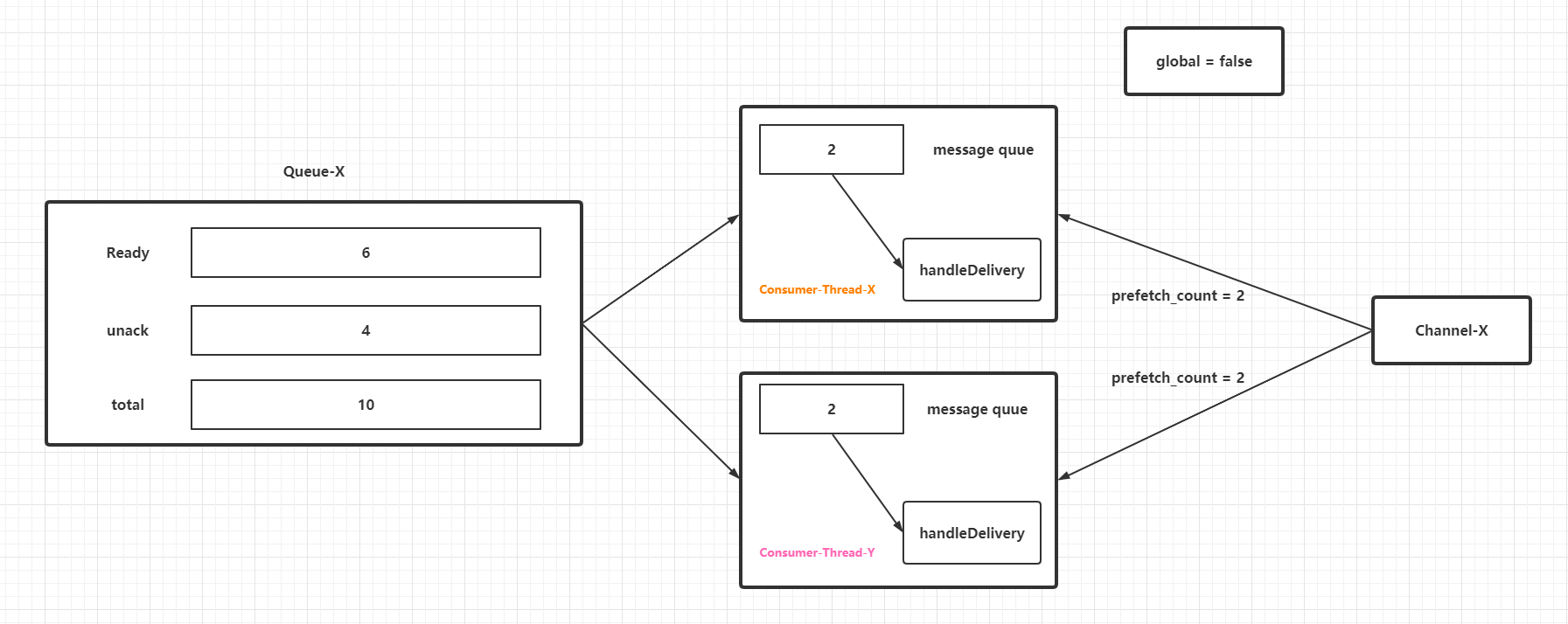
上图仅仅为了区分协议本身和RabbitMQ中实现的不同,接着说说prefetch_count对于消费者(线程)和待消费消息的作用。假定一个前提:RabbitMQ客户端从RabbitMQ服务端获取到队列消息的速度比消费者线程消费速度快,目前有两个消费者线程共用一个Channel实例。当global参数为false时候,效果如下:
而当global参数为true时候,效果如下:
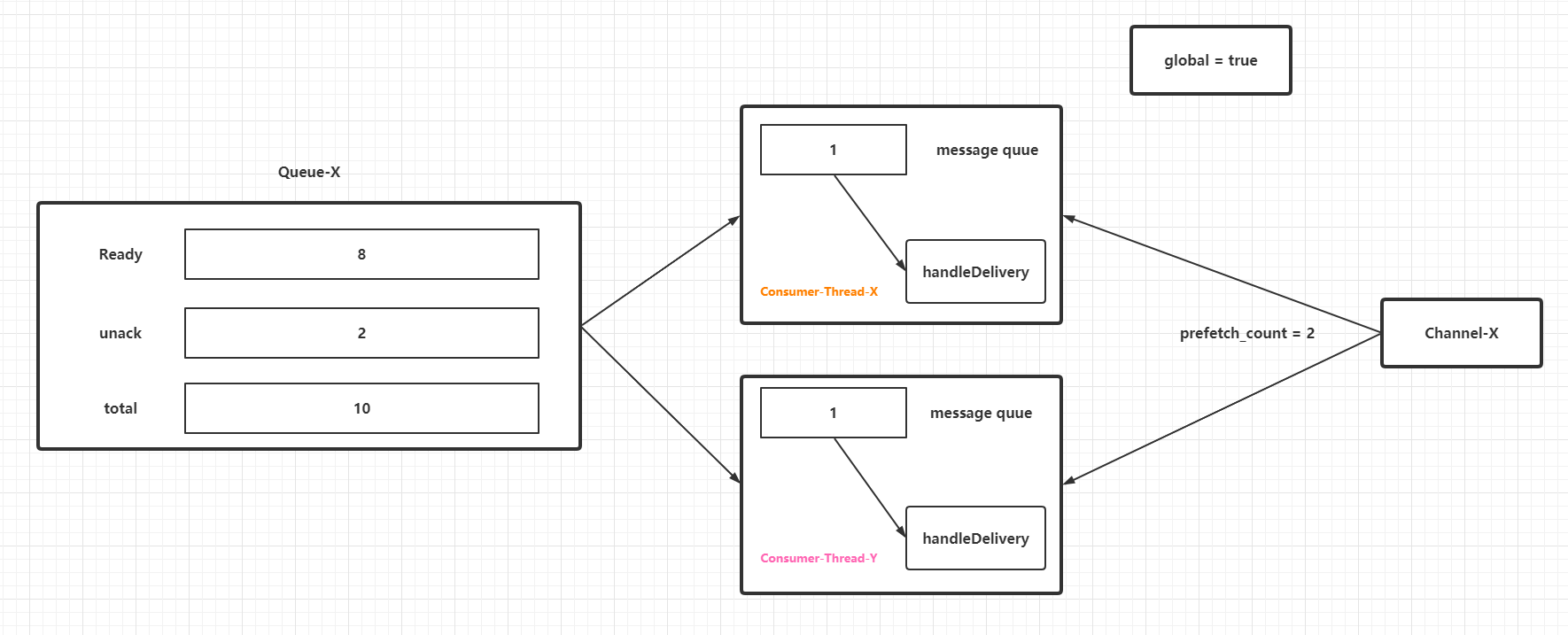
在消费者线程处理速度远低于RabbitMQ客户端从RabbitMQ服务端获取到队列消息的速度的场景下,prefetch_count条未进行ack的消息会暂时存放在一个队列(准确来说是阻塞队列,然后阻塞队列中的消息任务会流转到一个列表中遍历回调消费者句柄,见下一节的源码分析)中等待被消费者处理。这部分消息会占据JVM的堆内存,所以在性能调优或者设定应用程序的初始化和最大堆内存的时候,如果刚好用到RabbitMQ的消费者,必须要考虑这些"预取消息"的内存占用量。不过值得注意的是:prefetch_count是RabbitMQ服务端的参数,它的设置值或者快照都不会存放在RabbitMQ客户端。同时需要注意prefetch_count生效的条件和特性(从参数设置的一些demo和源码上感知):
prefetch_count参数仅仅在basic.consume的autoAck参数设置为false的前提下才生效,也就是不能使用自动确认,自动确认的消息没有办法限流。basic.consume如果在非自动确认模式下忘记了手动调用basic.ack,那么prefetch_count正是未ack消息数量的最大上限。prefetch_count是由RabbitMQ服务端控制,一般情况下能保证各个消费者线程中的未ack消息分发是均衡的,这点笔者猜测是consumerTag起到了关键作用。
RabbitMQ客户端中prefetch_count源码跟踪
编写本文的时候引入的RabbitMQ客户端版本为:com.rabbitmq:amqp-client:5.9.0
上面说了这么多都只是根据官方的文档或者博客中的理论依据进行分析,其实更加根本的分析方法是直接阅读RabbitMQ的Java客户端源码,主要是针对basic.qos和basic.consume两个方法,对应的是com.rabbitmq.client.impl.ChannelN#basicQos()和com.rabbitmq.client.impl.ChannelN#basicConsume()两个方法。先看ChannelN#basicQos():
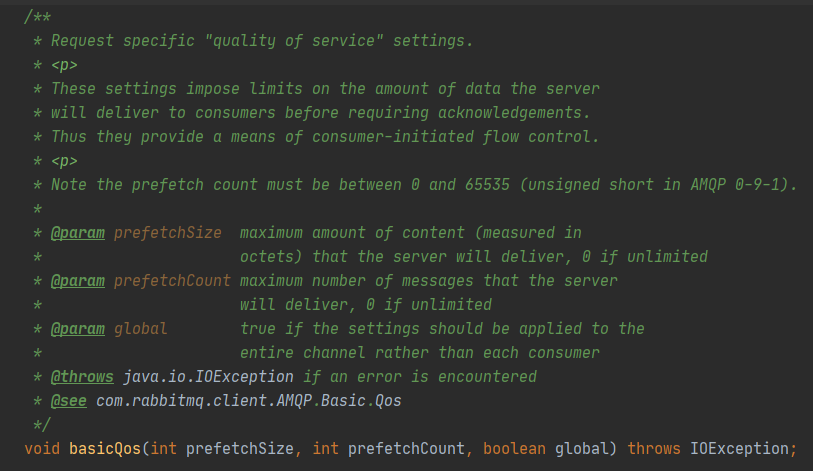
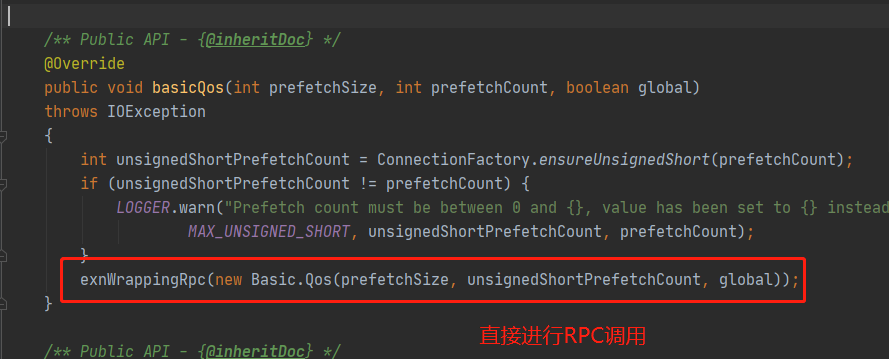
这里的basicQos()方法多了一个prefetchSize参数,用于限制分发内容的大小上限,默认值0代表无限制,而prefetchCount的取值范围是[0,65535],取值为0也是代表无限制。这里的ChannelN#basicQos()实现中直接封装basic.qos方法参数进行一次RPC调用,意味着直接更变RabbitMQ服务端的配置,即时生效,同时参数值完全没有保存在客户端代码中,印证了前面一节的结论。接着看ChannelN#basicConsume()方法:
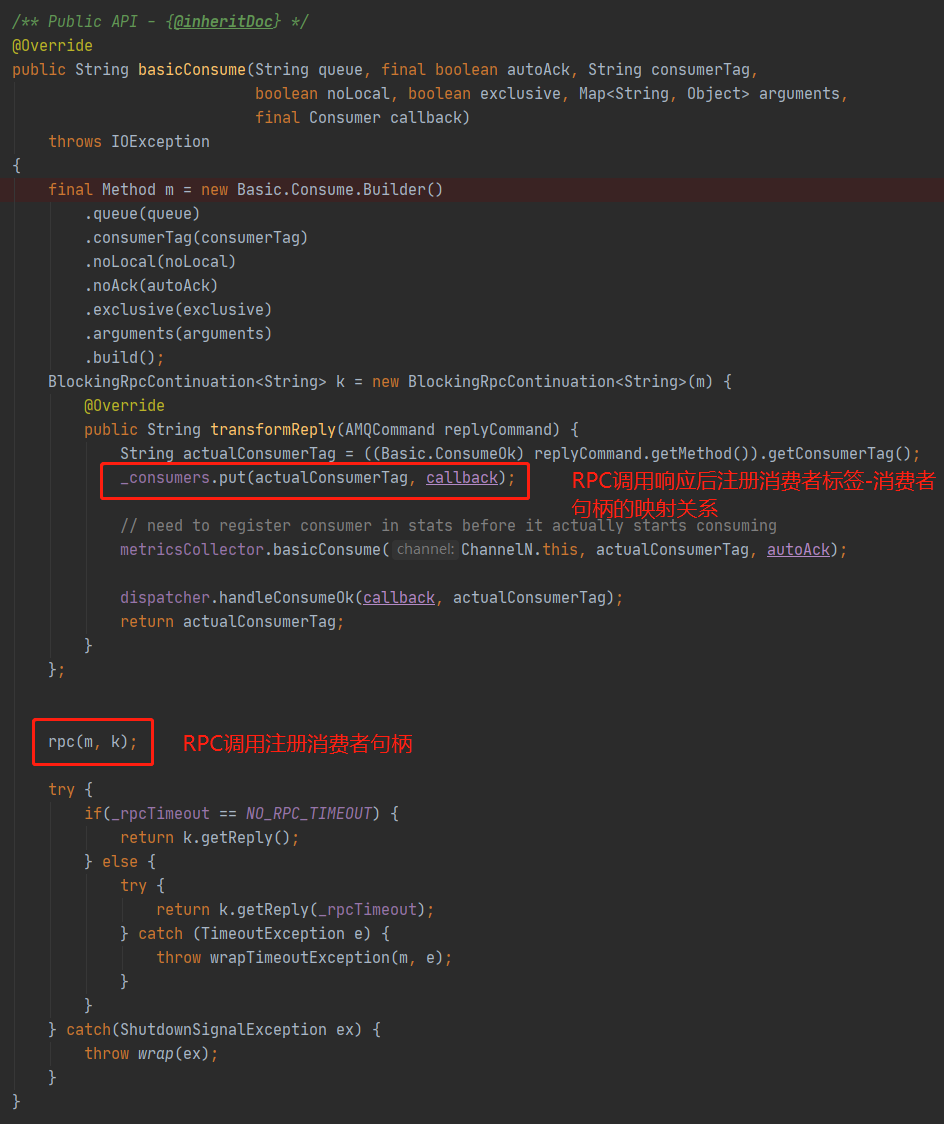
上图已经把关键部分用红圈圈出,因为整个消息消费过程是异步的,涉及太多的类和方法,这里不全量贴出,整理了一个流程图:
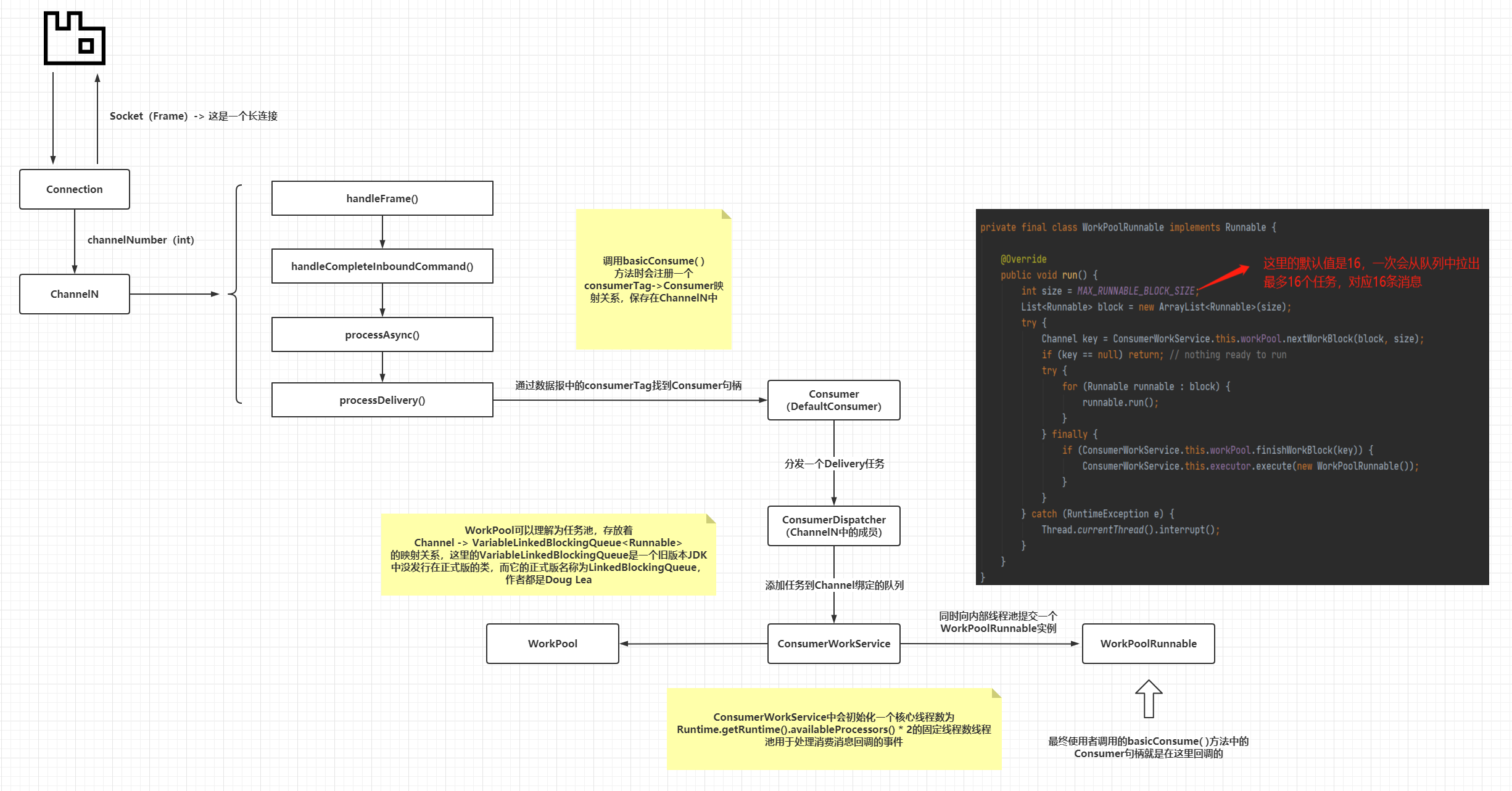
整个消息消费过程,prefetch_count参数并未出现在客户端代码中,又再次印证了前面一节的结论,即prefetch_count参数的行为和作用完全由RabbitMQ服务端控制。而最终Customer或者常用的DefaultCustomer句柄是在WorkPoolRunnable中回调的,这类任务的执行线程来自于ConsumerWorkService内部的线程池,而这个线程池又使用了Executors.newFixedThreadPool()去构建,使用了默认的线程工厂类,因此在Customer#handleDelivery()方法内部打印的线程名称的样子是pool-1-thread-*。
这里VariableLinkedBlockingQueue就是前一节中的message queue的原型
prefetch_count参数使用
设置prefetch_count参数比较简单,就是调用Channel#basicQos()方法:
public class RabbitQos {
static String QUEUE = "qos.test";
public static void main(String[] args) throws Exception {
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("localhost");
connectionFactory.setPort(5672);
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE, true, false, false, null);
channel.basicQos(2);
channel.basicConsume("qos.test", false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("1------" + Thread.currentThread().getName());
sleep();
}
});
channel.basicConsume("qos.test", false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println("2------" + Thread.currentThread().getName());
sleep();
}
});
for (int i = 0; i < 20; i++) {
channel.basicPublish("", QUEUE, MessageProperties.TEXT_PLAIN, String.valueOf(i).getBytes());
}
sleep();
}
private static void sleep() {
try {
Thread.sleep(Long.MAX_VALUE);
} catch (Exception ignore) {
}
}
}
上面是原生的amqp-client的写法,如果使用了spring-amqp(spring-boot-starter-amqp),可以通过配置文件中的spring.rabbitmq.listener.direct.prefetch属性指定所有消费者线程的prefetch_count,如果要针对部分消费者线程进行该属性的设置,则需要针对RabbitListenerContainerFactory进行改造。
prefetch_count参数最佳实践
关于prefetch_count参数的设置,RabbitMQ官方有一篇文章进行了分析:《Finding bottlenecks with RabbitMQ 3.3》。该文章分析了消息流控的整个流程,其中提到了prefetch_count参数的一些指标:

这里指出了,如果prefetch_count的值超过了30,那么网络带宽限制开始占主导地位,此时进一步增加prefetch_count的值就会变得收效甚微。也就是说,官方是建议把prefetch_count设置为30。这里再参看一下spring-boot-starter-amqp中对此参数定义的默认值,具体是AbstractMessageListenerContainer中的DEFAULT_PREFETCH_COUNT:
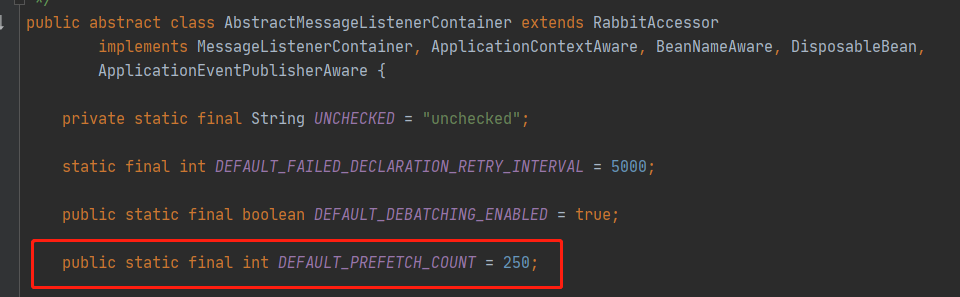
如果没有通过spring.rabbitmq.listener.direct.prefetch进行覆盖,那么使用spring-boot-starter-amqp中的注解定义的消费者线程中设置的prefetch_count就是250。
笔者认为,应该综合带宽、每条消息的数据报大小、消费者线程处理的速率等等角度去考虑prefetch_count的设置。总结如下(个人经验仅供参考):
- 当消费者线程的处理速度十分慢,而队列的消息量十分少的场景下,可以考虑把
prefetch_count设置为1。 - 当队列中的每条消息的数据报十分大的时候,要计算好客户端可以容纳的未
ack总消息量的内存极限,从而设计一个合理的prefetch_count值。 - 当消费者线程的处理速度十分快,远远大于
RabbitMQ服务端的消息分发,在网络带宽充足的前提下,设置可以把prefetch_count值设置为0,不做任何的消息流控。 - 一般场景下,建议使用
RabbitMQ官方的建议值30或者spring-boot-starter-amqp中的默认值250。
小结
小结一下:
prefetch_count是RabbitMQ服务端的参数,设置后即时生效。prefetch_count对于AMQP-0-9-1中的定义与RabbitMQ中的实现不完全相同。prefetch_count值设置建议使用框架提供的默认值或者通过分组实验结合数据报大小进行计算和评估出一个合理值。
彩蛋
笔者把文章发布到公众号和朋友圈后,笔者的师傅作了点评,指出其中的一点不足:
确实如此,prefetch_count的本质作用就是消费者的流控,官方的那篇文章也提到了网络和带宽的重要性,所以要考虑RTT(Round-Trip Time,往返时延),这里的RTT概念来源于《计算机网络原理》:
The RTT includes packet-propagation delays, packet-queuing delays and packet -processing delay.
也就是说RTT = 数据包传播时延(往返)+ 数据包排队时延(路由器和交换机的)+ 数据处理时延(应用程序处理耗时,用在本文的场景就是消费者处理消息的耗时)。假设RTT中只计算网络的时延,不包含数据处理的时延,那么数据包往返需要2RTT,也就是一条消费消息处理的数据包的往返,RTT越大,那么数据传输成本越高,应该允许客户端"预取"更多的未ack消息避免消费者线程等待。这样就可以计算出单个消费者线程处理达到最饱和状态下的"预取"消息量:prefetch_count = 2RTT / 消费者线程处理单条消息的耗时。依照此概念举例:
- 当
RTT为30ms,而消费者线程处理单条消息的耗时为10ms,此时,消费速率占优势,可以考虑把prefetch_count设置为6或者更大的值(考虑堆内存极限的限制)。 - 当
RTT为30ms,而消费者线程处理单条消息的耗时为200ms,RTT占优势,消费速率滞后,此时考虑把prefetch_count设置为1即可。
思考:为什么spring-boot-starter-amqp把prefetch_count默认值设置为250这么高的值,很少开发者改动它却没有出现明显问题?
(本文完 c-4-d e-a-20201017)
深入理解RabbitMQ中的prefetch_count参数的更多相关文章
- 理解RabbitMQ中的AMQP-0-9-1模型
前提 之前有个打算在学习RabbitMQ之前,把AMQP详细阅读一次,挑出里面的重点内容.后来找了下RabbitMQ的官方文档,发现了有一篇文档专门介绍了RabbitMQ中实现的AMQP模型部分,于是 ...
- 如何理解javaSript中函数的参数是按值传递
本文是我基于红宝书<Javascript高级程序设计>中的第四章,4.1.3传递参数小节P70,进一步理解javaSript中函数的参数,当传递的参数是对象时的传递方式. (结合资料的个人 ...
- 深入理解python中函数传递参数是值传递还是引用传递
深入理解python中函数传递参数是值传递还是引用传递 目前网络上大部分博客的结论都是这样的: Python不允许程序员选择采用传值还是传 引用.Python参数传递采用的肯定是"传对象引用 ...
- 理解 Python 中的可变参数 *args 和 **kwargs:
默认参数: Python是支持可变参数的,最简单的方法莫过于使用默认参数,例如: def getSum(x,y=5): print "x:", x print "y:& ...
- 基于TensorFlow理解CNN中的padding参数
1 TensorFlow中用到padding的地方 在TensorFlow中用到padding的地方主要有tf.nn.conv2d(),tf.nn.max_pool(),tf.nn.avg_pool( ...
- 关于vue自定义事件中,传递参数的一点理解
例如有如下场景 先熟悉一下Vue事件处理 <!-- 父组件 --> <template> <div> <!--我们想在这个dealName的方法中传递额外参数 ...
- RabbitMQ中 exchange、route、queue的关系
从AMQP协议可以看出,MessageQueue.Exchange和Binding构成了AMQP协议的核心,下面我们就围绕这三个主要组件 从应用使用的角度全面的介绍如何利用Rabbit MQ构建 ...
- RabbitMQ中交换机的消息分发机制
RabbitMQ是一个消息代理,它接受和转发消息,是一个由 Erlang 语言开发的遵循AMQP协议的开源实现.在RabbitMQ中生产者不会将消息直接发送到队列当中,而是将消息直接发送到交换机(ex ...
- 怎么理解js中的事件委托
怎么理解js中的事件委托 时间 2015-01-15 00:59:59 SegmentFault 原文 http://segmentfault.com/blog/sunchengli/119000 ...
随机推荐
- SpringBoot集成Nacos
一.环境说明 1.CentOS7 2.Jdk1.8 3.Mysql5.7 4.Nacos1.3 5.SpringBoot2.3.1.RELEASE 6.Maven3.6 二.下载Nacos 1.Nac ...
- 数据库漏洞扫描工具scuba
1.先下载安装scuba 参考地址 https://www.52pojie.cn/thread-702605-1-1.html 百度网盘下载地址: 链接:https://pan.baidu.com/ ...
- 使用vscode编辑和提交github仓库代码
写在前面 在github上想删除仓库中的某个文件或文件夹,亦或是重命名操作都很麻烦,这里提供一种vscode的解决方案.在vscode中克隆远程github仓库,然后对代码或文件进行编辑,最后提交即可 ...
- 微信小程序入门到精通
微信小程序账号与工具 在线文档:https://mp.weixin.qq.com/debug/wxadoc/dev/ 小程序开发者账号注册 微信公众平台:https://mp.weixin.qq.co ...
- Magento中数据拷贝一实现
Mage_Sales_Model_Quote::setCustomer方法,有这么一行代码 Mage::helper('core')->copyFieldset('customer_accoun ...
- Java 异常面试题(2020 最新版)
Java异常架构与异常关键字 Java异常简介 Java异常是Java提供的一种识别及响应错误的一致性机制. Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程 ...
- Flutter 使用image_gallery_saver保存图片
Flutter 使用image_gallery_saver保存图片 其实我们开发项目app的时候, 你会发现有很多问题, 比如保存图片功能时 ,不仅导入包依赖包: image_gallery_sav ...
- 《Redis入门指南》笔记
第1章 简介 1.1 历史与发展 2008年 意大利创业公司创始人因对mysql性能不满意,于是他决定开发redis. 2009年 redis初版由他一个人开发完成.redis是"remot ...
- 【测试基础第六篇】bug定义及生命周期
bug定义 狭义:软件程序的漏洞或缺陷 广义:测试工程师或用户所发现和提出的软件可改进的细节(增强型.建议性)或需求文档存在差异的功能实现 职责:发现bug,提给开发,让其修改 bug类型--了解 代 ...
- C#方法Extra
C#方法Extra 上次说的只是方法的一些基本东西,今天讲讲重载和 Lambda 表达式. 重载 方法的重载(overload)指的是同一个名字的方法,有着不一样的方法签名(method signat ...