pytorch——合并分割
分割与合并
import torch
import numpy as np
#假设a是班级1-4的数据,每个班级里有32个学生,每个学生有8门分数
#假设b是班级5-9的数据,每个班级里有32个学生,每个学生有8门分数
#现在要将两个班级合并
a=torch.rand(4,32,8)
b=torch.rand(5,32,8)
c=torch.cat([a,b],dim=0) #在0维度上进行a和b的拼接.注意只有在拼接的维度上数字可以不一致
print(c.shape) #使用stack拼接
c1=torch.rand(3,8)
d1=torch.rand(3,8)
cd=torch.stack([c1,d1],dim=0)
print('使用stack拼接',cd.shape) #在0维度进行拼接,会在前面插入多一个2的维度,
# 如果新生维度取0就是取上半部分,如果取1就是取下半部分
print('这里是c1',c1)
print('这里是d1',d1)
print('取上半部分',cd[0,0:,0:])
print('取上半部分',cd[1,0:,0:]) #拆分操作
#现在想吧(3,32,8)拆分成三个(1,32,8)
t1=torch.rand(3,32,8)
ts1,ts2,ts3=t1.split(1,dim=0) #将维度0拆分成每个都是1的
print(ts1.shape,ts2.shape,ts3.shape)
#现在想吧(3,32,8)拆分成两个(2,32,8)和(1,32,8)
ts1,ts2=t1.split([2,1],dim=0) #将维度0拆分成第一组两个,第二组1个
print(ts1.shape,ts2.shape)
#使用chunk按块的数量拆分
t1=torch.rand(6,32,8)
ts1,ts2,ts3=t1.chunk(3,dim=0) #将维度0拆分成3块
print(ts1.shape,ts2.shape,ts3.shape)
数学运算
#数学运算
a=torch.rand(3,4)
b=torch.rand(4)
print(a+b) #能执行成功是因为b会用自动拓展使得变成(1,4),然后变成(3,4)来和a运算
#print(a*b)
#print(a/b)
#print(a-b) #矩阵相乘torch.matmul
a=torch.ones(3,3)
b=torch.tensor([[2,2,2],[2,2,2],[2,2,2]]).type(torch.float32)
print(torch.matmul(a,b)) #四维情况下的matmul,此时前两维度不变,取后两维做成矩阵然后进行乘积
a=torch.rand(4,3,28,64)
b=torch.rand(4,3,64,32)
print(torch.matmul(a,b).shape) #有关于取值
qq=torch.tensor(3.14)
print('向下取',qq.floor(),'向上取',qq.ceil(),'取整数部分',qq.trunc(),'取小数部分',qq.frac())
print('四舍五入取整',qq.round()) #筛选
grad=torch.rand(2,3)*15
print(grad.max())
print(grad.median())
print(grad)
print(grad.clamp(9)) #小于9的变成9
print(grad.clamp(6,9)) #大于9的变成9,小于6的变成6 #求范数
f=torch.tensor([[2,2,2,2],[2,2,2,2]]).type(torch.float32)
print(f.norm(1),f.norm(2)) #可以加上dim指定某个维度求范数 #mean和prod和max和min 括号里面如果不加维度的参数会默认将所有维度打平成一个向量来求
m=torch.tensor([[0,1,2,3],[4,5,6,7]]).type(torch.float32)
print(m.shape)
#mean等于的是求和起来再除以size
print(m.mean())
#prod是乘积
print(m.prod())
#上面是打平来求的,下面来看不打平的
print('不打平的求后面这两个列的乘积',m.prod(1))
print('返回列的最大值的索引',m.argmax(1))
高级操作
#keepdim用于求max或者argmax的时候,维度不改变,其他位置自动添加1
#topk,按顺序取几个大的
cd=torch.rand(2,3)
print('初始的tensor',cd)
print('取1维(针对前面的那一维也就是行)上最大的两个',cd.topk(2,dim=1))
#topk,按顺序取几个小的
cd=torch.rand(2,3)
print('初始的tensor',cd)
print('取1维(针对前面的那一维也就是行)上最小的两个',cd.topk(2,dim=1,largest=False))
#取第n个小的
cd=torch.rand(2,8)
print('初始的tensor',cd)
print('取1维(针对前面的那一维也就是行)上最小的第五个(第五小)',cd.kthvalue(5,dim=1)) # where把用其他两个tensort通过特定的条件生成一个tensor
cond=torch.tensor([[0.679,0.7271],[0.8884,0.4163]])
a=torch.tensor([[0.,0.],[0.,0.]])
b=torch.tensor([[1.,1.],[1.,1.]])
print(torch.where(cond>0.5,a,b))
神经元——激活函数
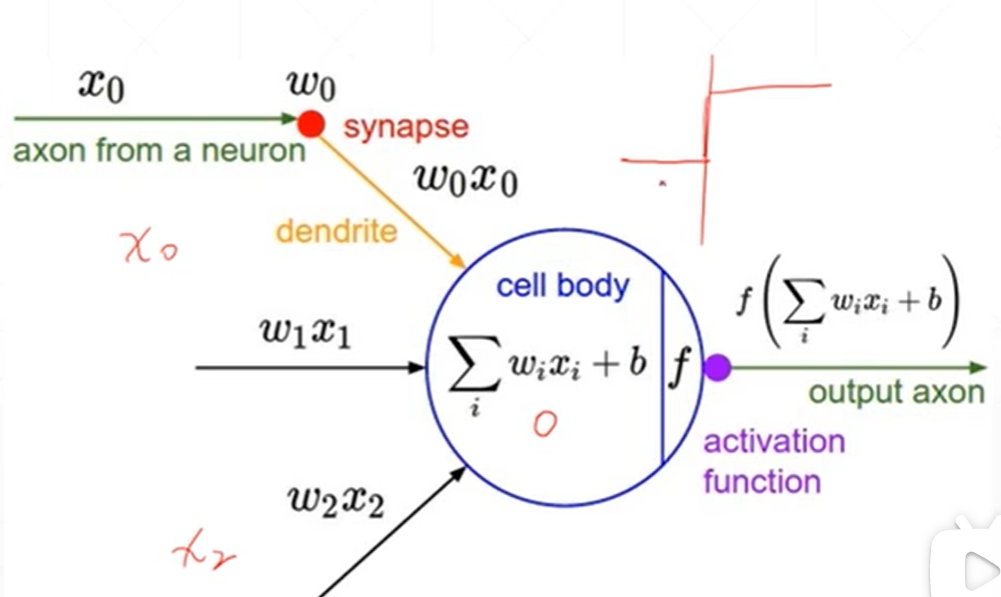
有x0到xi的多个输入,然后经过多个输入的ax+b的加权平均得到一个值,如果这个值大于阈值就可以做出反应,
而且这个反应的输出点平是定的,如果这个值不达到阈值就不会作出反应
为了弄可以求导的连续的提出了一种激活函数sigmoid(区间从0到1)
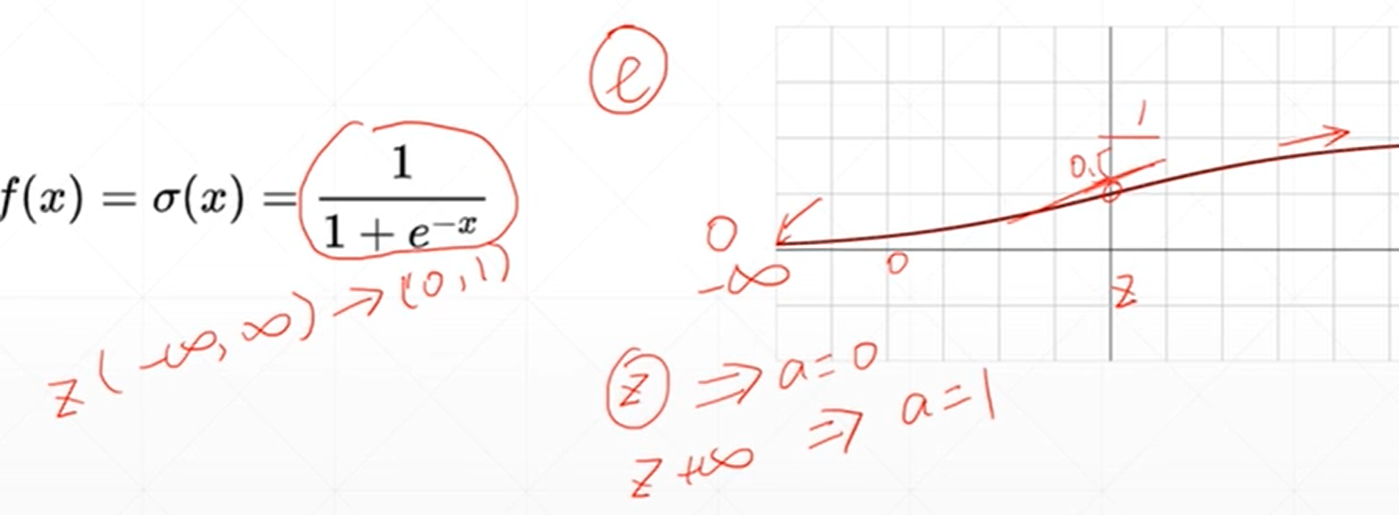
激活函数的导数
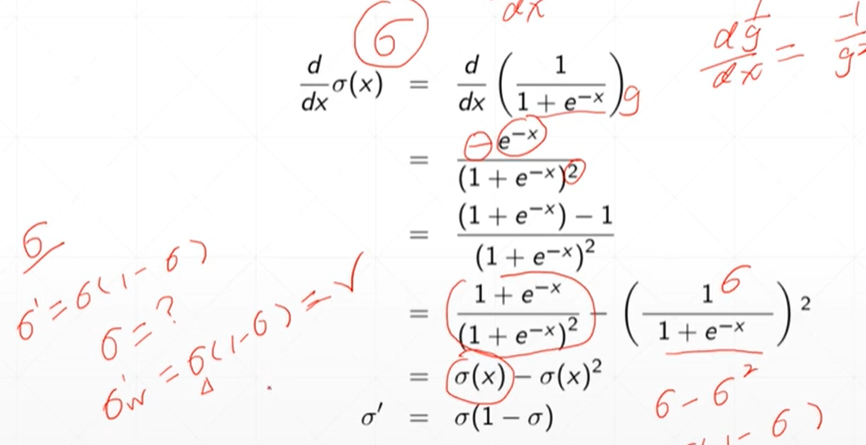
#调用sigmore函数
sig=torch.linspace(-100,100,10)
print(torch.sigmoid(sig))
另外一种的激活函数tanh(区间从-1到1)

tanh激活函数求得的导数的值
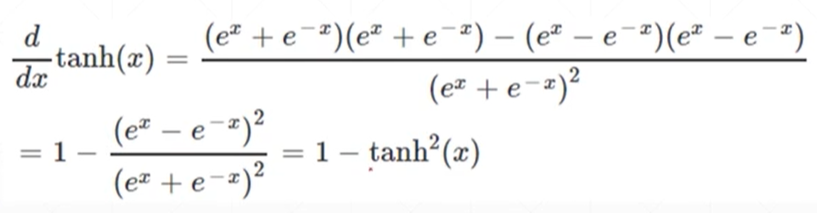
#调用tanh函数
tanh=torch.linspace(-3,3,5)
print(torch.tanh(tanh))
relu整形的线性单元
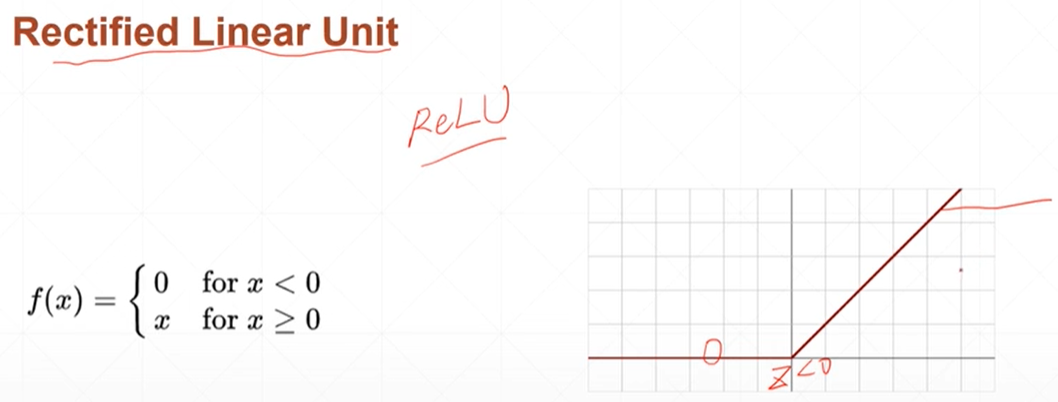
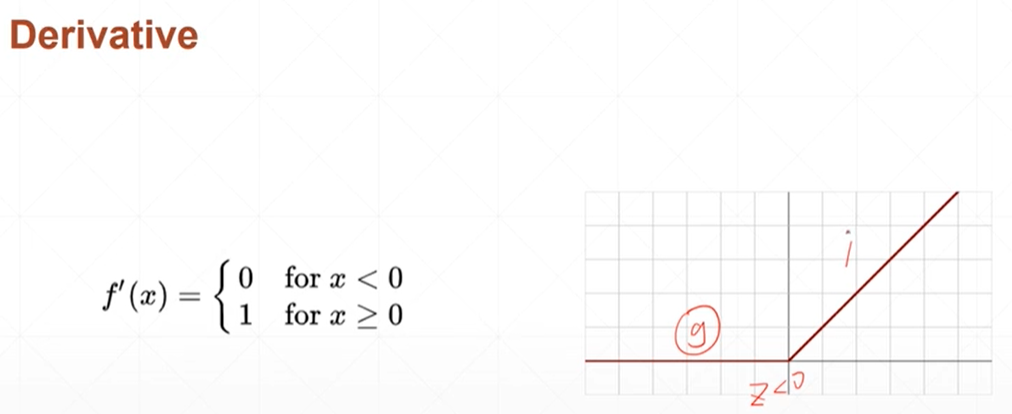
#调用relu函数
relu=torch.linspace(-3,3,5)
print(torch.relu(relu))
loss损失种类及其求导后的公式
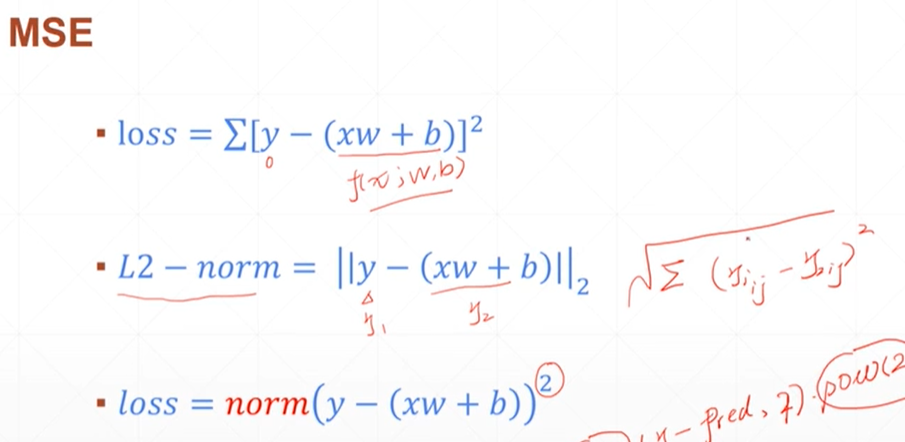
1.均方差
均方差里面有两种,一种是loss还有一种是norm,norm相当于是对loss的开平方
import torch
x = torch.tensor([1]).type(torch.float32) #x的值是单个数字1
x.requires_grad_() #设置x是需要进行求导的
y = x*2 #公式
grads = torch.autograd.grad(outputs=y, inputs=x)[0] #导数是output(y)去对input--x求导,由于y=2*1=2是标量,不是向量
#所以不用设置grad_outputs
print(grads)
pytorch——合并分割的更多相关文章
- js数组常用操作方法小结(增加,删除,合并,分割等)
本文实例总结了js数组常用操作方法.分享给大家供大家参考,具体如下: var arr = [1, 2, 3, 4, 5]; //删除并返回数组中第一个元素 var theFirst = arr.shi ...
- 【daily】文件分割限速下载,及合并分割文件
说明 主要功能: 1) 分割文件, 生成下载任务; 2) 定时任务: 检索需要下载的任务, 利用多线程下载并限制下载速度; 3) 定时任务: 检索可合并的文件, 把n个文件合并为完整的文件. GitH ...
- NumPy学习(索引和切片,合并,分割,copy与deep copy)
NumPy学习(索引和切片,合并,分割,copy与deep copy) 目录 索引和切片 合并 分割 copy与deep copy 索引和切片 通过索引和切片可以访问以及修改数组元素的值 一维数组 程 ...
- Linux大文件split分割以及cat合并
文件大小分割文件时,需要以-C参数指定分割后的文件大小: $ split -C 100M large_file.txt stxt 如上所示,我们将大文件large_file.txt按100M大小进 ...
- Linux中split大文件分割和cat合并文件
当需要将较大的数据上传到服务器,或从服务器下载较大的日志文件时,往往会因为网络或其它原因而导致传输中断而不得不重新传输.这种情况下,可以先将大文件分割成小文件后分批传输,传完后再合并文件. 1.分割 ...
- WinRAR分割超大文件
在自己的硬盘上有一个比较大的文件,想把它从网上通过E-Mail发送给朋友时,却发现对方的收信服务器不能够支持那么大的文件……,这时即使用ZIP等压缩软件也无济于事,因为该文件本身已经被压缩过了.于是许 ...
- Atitit 数据存储视图的最佳实际best practice attilax总结
Atitit 数据存储视图的最佳实际best practice attilax总结 1.1. 视图优点:可读性的提升1 1.2. 结论 本着可读性优先于性能的原则,面向人类编程优先于面向机器编程,应 ...
- FastReport.Net 常用功能总汇
一.常用控件 文本框:输入文字或表达式 表格:设置表格的行列数,输入数字或表达式 子报表:放置子报表后,系统会自动增加一个页面,你可以在此页面上设计需要的报表.系统在打印处理时,先按主报表打印,当碰到 ...
- python字符串及其方法详解
首先来一段字符串的基本操作 str1="my little pony" str2="friendship is magic" str3=str1+", ...
随机推荐
- 网站开发学习Python实现-Django项目部署-介绍(6.2.1)
@ 目录 1.第一步:找源码 2.第二步:在windows中更改代码 2.第三步:同步到linux中 3.第三步:部署 4.第四步:运行 关于作者 1.第一步:找源码 从github上找一个djang ...
- Yii2 给表添加字段后报错 Getting unknown property
手动在数据库中添加了image字段 然后再模型类Image中的 rule方法也将image的验证规则放进去了 但是在 $model = new Image 后,使用$model->iamge 还 ...
- 持久层之 MyBatis: 第一篇:快速入门
MyBatis入门到精通 JDBC回顾 1.1.认识MyBatis 1.1.使用IDEA创建maven工程 1.2.引入mysql依赖包 1.3.准备数据 1.4 使用JDBC手写MyBatis框架 ...
- Linux系统搭建RabbitMQ
下载erlang和rabbitmq-server 1.下载Erlang安装包 [root@VM_0_9_centos soft]# wget http://erlang.org/download/ot ...
- 转载:从输入 URL 到页面加载完的过程中都发生了什么事情?
原帖地址:http://www.guokr.com/question/554991/ 1)把URL分割成几个部分:协议.网络地址.资源路径.其中网络地址指示该连接网络上哪一台计算机,可以是域名或者IP ...
- 在C#中使用OpenCV(使用GOCW)
在C#中使用OpenCV(使用GOCW) 1.什么是GOCW 为了解决在Csharp下编写OpenCV程序的问题,我做过比较深入的研究,并且实现了高效可用的方法GreenOpenCshar ...
- redis加锁的几种实现
redis加锁的几种实现 2017/09/21 1. redis加锁分类 redis能用的的加锁命令分表是INCR.SETNX.SET 2. 第一种锁命令INCR 这种加锁的思路是, key 不存在, ...
- Spring Boot Starters
Spring Boot Starters 摘自 https://www.nosuchfield.com/2017/10/15/Spring-Boot-Starters/ 2017-10-15 Spri ...
- 浅入kubernetes(2):Kubernetes 的组成
目录 说明 Kubernetes集群的组成 What are containerized applications? What are Kubernetes containers? What are ...
- linux系统重启网卡后网络不通(NetworkManager篇)
一.故障现象 RHEL7.6系统,使用nmcli绑定双网卡后,再使用以下命令重启network服务后主机网络异常,导致无法通过ssh远程登录系统. # systemctl restart n ...