切片声明 切片在内存中的组织方式 reslice
数组是具有相同 唯一类型 的一组已编号且长度固定的数据项序列(这是一种同构的数据结构),[5]int和[10]int是属于不同类型的。数组的编译时值初始化是按照数组顺序完成的(如下)。
切片声明方式,
声明切片的格式是: var identifier []type(不需要说明长度)。
一个切片在未初始化之前默认为 nil,长度为 0。
切片的初始化格式是:var slice1 []type = arr1[start:end]。
一个由数字 1、2、3 组成的切片可以这么生成:s := [3]int{1,2,3}[:](注: 应先用s := [3]int{1, 2, 3}生成数组, 再使用s[:]转成切片) 甚至更简单的 s := []int{1,2,3}。
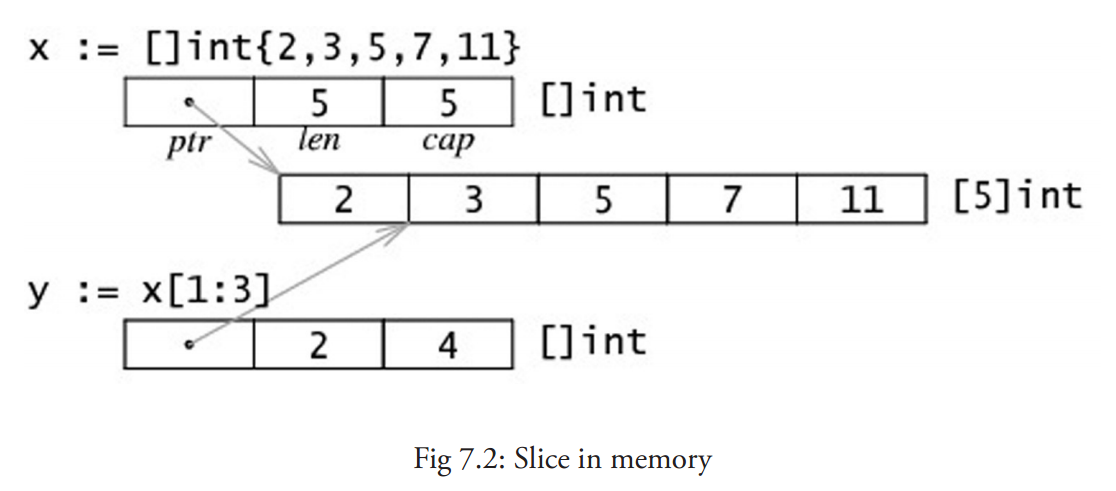
切片也可以用类似数组的方式初始化:var x = []int{2, 3, 5, 7, 11}。这样就创建了一个长度为 5 的数组并且创建了一个相关切片。
Go 切片:用法和本质 - Go 语言博客 https://blog.go-zh.org/go-slices-usage-and-internals
可能的“陷阱”
正如前面所说,切片操作并不会复制底层的数组。整个数组将被保存在内存中,直到它不再被引用。 有时候可能会因为一个小的内存引用导致保存所有的数据。
例如, FindDigits 函数加载整个文件到内存,然后搜索第一个连续的数字,最后结果以切片方式返回。
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
这段代码的行为和描述类似,返回的 []byte 指向保存整个文件的数组。因为切片引用了原始的数组, 导致 GC 不能释放数组的空间;只用到少数几个字节却导致整个文件的内容都一直保存在内存里。
要修复整个问题,可以将感兴趣的数据复制到一个新的切片中:
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
可以使用 append 实现一个更简洁的版本。这留给读者作为练习。
package main import (
"fmt"
"reflect"
) func main() {
x := [3]int{1, 2, 3}
func(arr [3]int) {
arr[0] = 7
fmt.Println(arr)
}(x)
fmt.Println(x) y := [3]int{1, 2, 3}
func(arr *[3]int) {
arr[0] = 7
fmt.Println(arr)
fmt.Println(*arr)
}(&y)
fmt.Println(y) z := []int{1, 2, 3}
func(arr []int) {
arr[0] = 7
fmt.Println(arr)
}(z) fmt.Println(z) fmt.Println("reflect.TypeOf(x,y,z:", reflect.TypeOf(x), reflect.TypeOf(y), reflect.TypeOf(z))
}
1、数组,值类型
2、数组地址,修改了数组
3、切片,引用类型,修改了数组
[7 2 3]
[1 2 3]
&[7 2 3]
[7 2 3]
[7 2 3]
[7 2 3]
[7 2 3]
reflect.TypeOf(x,y,z: [3]int [3]int []int
the-way-to-go_ZH_CN/07.2.md at master · unknwon/the-way-to-go_ZH_CN https://github.com/unknwon/the-way-to-go_ZH_CN/blob/master/eBook/07.2.md
切片(slice)是对数组一个连续片段的引用,切片在内存中的组织方式实际上是一个有 3 个域的结构体:指向相关数组的指针,切片长度以及切片容量。
你真的懂 golang reslice 吗 | HHF技术博客 https://www.haohongfan.com/post/2020-10-20-golang-slice/
分片截取也叫reslice
如果你知道这些, 那么 slice 的使用基本上不会出现问题.
下面这些问题你考虑过吗 ?
- a1, a2 是如何共享底层数组的?
- a1[low:high]是如何实现的?
继续来看这段代码的汇编:
|
|
- 第4行: 将 AX 栈顶指针下移 8 字节, 指向了 a1 的 data 指向的地址空间里
- 第5-10行: 将 [3,4,5,6,7,8] 放入到 a1 的 data 指向的地址空间里
- 第11行: AX 指针后移 16 个字节. 也就是指向元素 5 的位置
- 第12行: 将 SP 指针下移 32 字节指向即将返回的 slice (其实就是 a2 ), 同时将 AX 放入到 SP. 注意 AX 放入 SP 里的是一个指针, 也就造成了a1, a2是共享同一块内存空间的
- 第13行: 将 SP 指针下移 40 字节指向了 a2 的 len, 同时 把 4 放入到 SP, 也就是 len(a2) = 4
- 第14行: 将 SP 指针下移 48 字节指向了 a2 的 cap, 同时 把 4 放入到 SP, 也就是 cap(a2) = 4
下图是 slice 的 栈图, 可以配合着上面的汇编一块看.
切片声明 切片在内存中的组织方式 reslice的更多相关文章
- Caffe Blob针对图像数据在内存中的组织方式
Caffe使用Blob结构在CNN网络中存储.传递数据.对于批量2D图像数据,Blob的维度为 图像数量N × 通道数C × 图像高度H × 图像宽度W 显然,在此种场景下,Blob使用4维坐标定位数 ...
- <转载>浅谈C/C++的浮点数在内存中的存储方式
C/C++浮点数在内存中的存储方式 任何数据在内存中都是以二进制的形式存储的,例如一个short型数据1156,其二进制表示形式为00000100 10000100.则在Intel CPU架构的系统中 ...
- 数据在内存中的存储方式( Big Endian和Little Endian的区别 )(x86系列则采用little endian方式存储数据)
https://www.cnblogs.com/renyuan/archive/2013/05/26/3099766.html 1.故事的起源 “endian”这个词出自<格列佛游记>.小 ...
- C语言中浮点数在内存中的存储方式
关于多字节数据类型在内存中的存储问题 //////////////////////////////////////////////////////////////// int ,short 各自是4. ...
- QList介绍(QList比QVector更快,这是由它们在内存中的存储方式决定的。QStringList是在QList的基础上针对字符串提供额外的函数。at()操作比操作符[]更快,因为它不需要深度复制)非常实用
FROM:http://apps.hi.baidu.com/share/detail/33517814 今天做项目时,需要用到QList来存储一组点.为此,我对QList类的说明进行了如下翻译. QL ...
- Float在内存中的存储方式及IEC61131处理
Float在内存中的存储方式及IEC61131处理 1,fp32(32bits float)类型数据在存储器中占用4Bytes存储,且遵循IEEE-754标准: 一个浮点数分三部分组成: 符号位s(1 ...
- float和double在内存中的存储方式
本文转载于:http://wenku.baidu.com/link?url=ARfMiXVHCwCZJcqfA1gfeVkMOj9RkLlR9fIexbgs9gDdV8rIS48A1_xe1y6YgX ...
- C/C++中整数与浮点数在内存中的表示方式
在C/C++中数字类型主要有整数与浮点数两种类型,在32位机器中整型占4字节,浮点数分为float,double两种类型,其中float占4字节,而double占8字节.下面来说明它们在内存中的具体表 ...
- java中的各种数据类型在内存中存储的方式
原文地址:http://blog.csdn.net/aaa1117a8w5s6d/article/details/8251456 1.Java是如何管理内存的 java的内存管理就是对象的分配和释放问 ...
随机推荐
- 点名小辣辣,带你入门 JMeter (。・∀・)ノ゙
什么是 JMeter Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试,它最初被设计用于Web应用测 试但后来扩展到其他测试领域. 它可以用于测试静态 ...
- 【vue】入门介绍
一.前端开发工具vscode 前端代码编写工具,使用vscode:vscode官网 安装好之后,可以先装如下几个插件,方便后续的开发. 二.编写代码 1.vscode快捷键生成html代码 在vsco ...
- Mac苹果电脑单片机开发
1.安装虚拟机 可以阅读往期文章:Mac苹果电脑安装虚拟机 2.在虚拟机上安装CH340驱动,keil4,PZ-ISP, 下载 CH340驱动安装 下载keil4破解及汉化 下载普中科技烧录软件
- JDBC(六)—— 数据库事务
数据库事务 事务 一组逻辑操作单元,使数据从一种状态变换到另一种状态 事务处理 保证所有事务都作为一个工作单元来执行,即使出现了故障,都不能改变这种执行方式. 当在一个事务中执行多个操作时,要么所有事 ...
- 实现连续登录X天送红包这个连续登录X天算法
实现用户只允许登录系统1次(1天无论登录N次算一次) //timeStamp%864000计算结果为当前时间在一天当中过了多少秒 //当天0点时间戳 long time=timeStamp-timeS ...
- 通过BulkLoad快速将海量数据导入到Hbase(TDH,kerberos认证)
一.概念 使用BlukLoad方式利用Hbase的数据信息是 按照特点格式存储在HDFS里的特性,直接在HDFS中生成持久化的Hfile数据格式文件,然后完成巨量数据快速入库的操作,配合MapRedu ...
- linux系统重启后提示An error occurred during the file system check.
一.问题描述 生产环境中一台浪潮NF8480M3外观红灯报警,鉴于无法登陆带外管理口,只能对服务器进行断电重启操作 二.问题现象 重启后进入开机过程并报错,正常来说进入此界面后直接输入root密码即可 ...
- TypeLoadException: 未能从程序集“ECS.GUI.Define, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null”中加载类型“ECS.GUI.Define.ArmgAimPos”,因为它在 4 偏移位置处包含一个对象字段,该字段已由一个非对象字段不正确地对齐或重叠
TypeLoadException: 未能从程序集"ECS.GUI.Define, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null ...
- VBA实现相同行合并
帮人捣鼓了个VBA代码用来实现多行合并,具体需求为:列2/列3/列4 相同的情况下,则对应的行合并为一行,且列1用空格隔开,列5则相加: (对大多数办公室职员,VBA还算是提高效率的一个利器吧) 最终 ...
- QPinter 常用绘制图像的方法
阅读本文大概需要 3 分钟 我们在开发软件的过程中,绘制图像功能必不可少,使用 Qt 绘制图像时非常简单,只需要传递几个参数就可以实现功能,在 Qt 中绘制图像的 api有好几个 void drawI ...