使用.Net Core做个爬虫
最近接手一个新项目,爬亚马逊分类、商品数据。记得大学的时候,自己瞎玩,写过一个爬有缘网数据的程序,那个时候没有考虑那么多,写的还是单线程,因为网站没有反爬,就不停的一直请求,记得放到实验室电脑上一天,跑了30w+的数据。然后当前晚上有缘网网站显示维护中。。。。
毕竟小打小闹,没有真正的写过爬虫。就翻别人博客了解了下爬虫所用到的技术、技巧、套路。然后就翻到这个老哥写的博客, 虽然语言是有点嚣张,但是我还是比较认同的 哈哈哈哈。

下面从爬虫涉及的几任务调度、数据去重、数据解析、并发控制、断点续爬、代理来聊聊项目遇到的坑。
一、数据解析
数据解析就是提取网页上的有效数据。.Net下有个HtmlAgilityPack组件,可以很好地解析HMTL。想都没想 就直接用了它(这就为后面挖了一个大坑)。刚开始单线程测试的时候,一切正常,但是当我开了50个线程的时候,内存在90s内飙升到了3G,而且持续爬升。
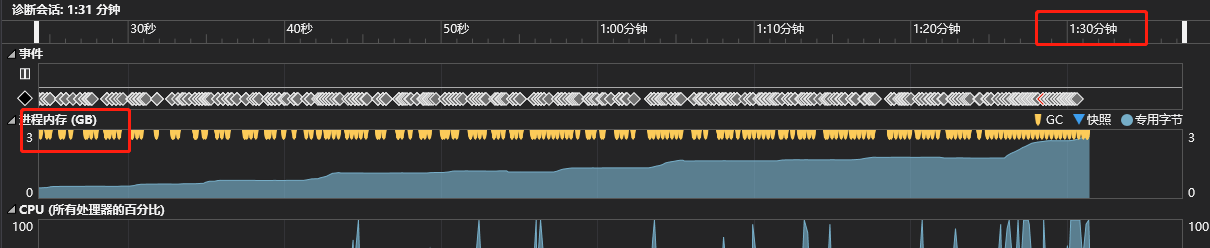
用.Net Memory工具分析发现 内存被大对象沾满了,所以每次GC的时候内存并没有被回收,有5w多HtmlNode,每个对象大小都超过 85000byte。
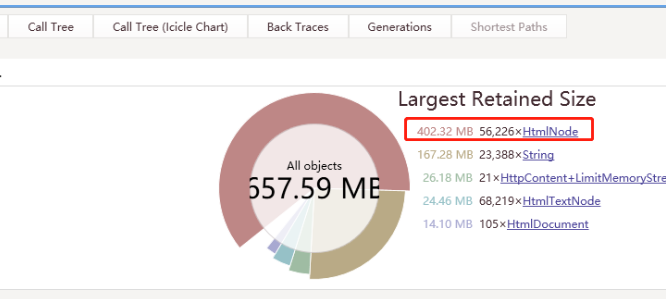
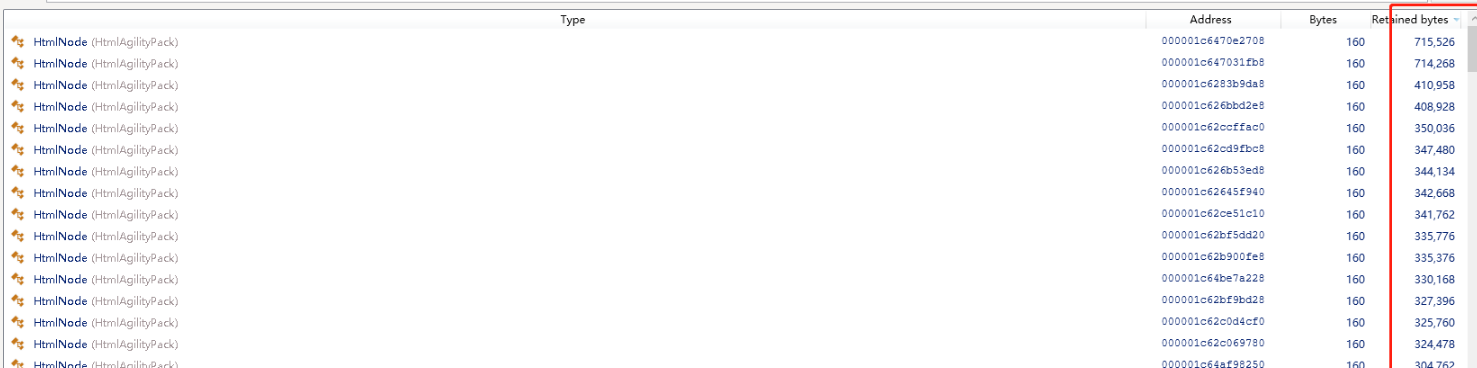
因为亚马逊的图片不是通过链接外链的,而是通过base64编码的,所以导致下载的网页Html超过1M,而85000byte就算大对象了。导致每爬取一个商品详情页,都会加载到HtmlNode中变成一个大对象,而GC对大对象的回收只有在回收2代的时候才触发。所以只能改变策略,通过正则、切分字符串来处理。
二、任务调度、并行爬取
目的是爬取亚马逊的分类和分类下的商品,我做了个3个任务,
1、找到分类入口,爬取分类Id、标题、url 、分类等级存储到数据库。
2、根据1任务爬取的分类Id,获取分类下商品列表。爬取列表上商品部分信息,包括商品的Id、名称、缩略图。
3、根据2任务爬取的商品Id,获取商品详情页,爬取商品详情页的其他信息。
一个分类下有几百页商品列表,而每个列表一般有22个商品。所以1任务爬取完一次,2任务要爬取几百次(当然不会将分类下的所有页码都爬完,设定只爬20页) ,3任务要爬 20 x 22次。这样分任务的好处就是 3个任务中,不论哪个任务挂了,其他2个任务是不受影响的,可以继续跑。
比如2任务挂掉了,1任务不受它影响,虽然3任务的需要2任务的数据,但是3任务的速度是比2任务慢了22倍还多(获取详情的时候 还需要在请求其他页面)所以任务线程相同的情况下 2任务的会有很多剩余商品 3还没有来得及跑。
调度采用了QuartZ 使用Cron配置定时任务。使用Parallel并行爬取,线程数量可以配只需要将方法和方法所需要的参数集合放到ForEach
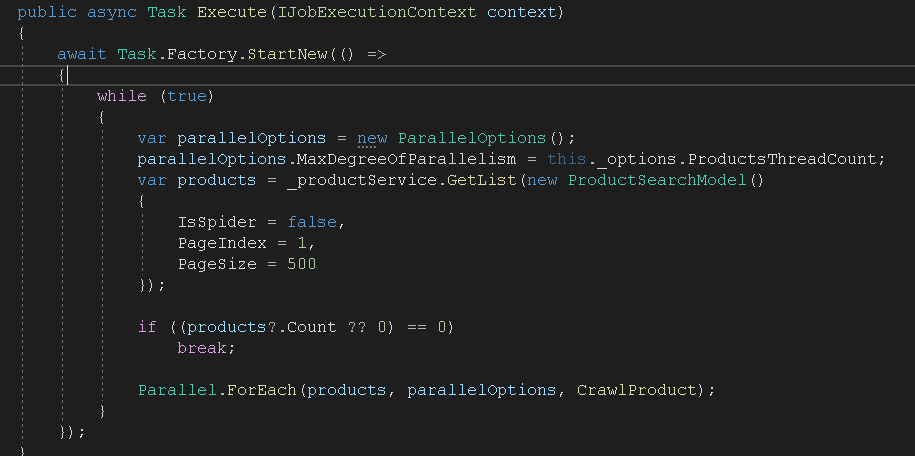
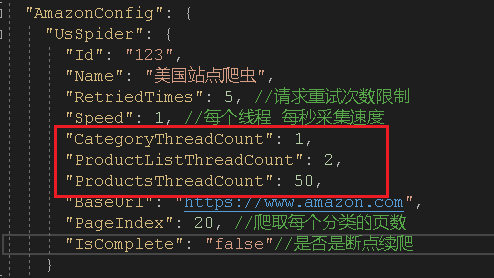
合理配置每个任务的线程数量,我设置爬取分类线程数1,商品列表的线程是2,商品详情爬取线程为50。爬取的速度不同线程数量就不同,而且并不是线程越高越好,这个值是不断的调试采集相同时间的数据分析得出来的。
三、代理
现在有很多代理商,普遍分为两种:
第一种通过接口返回代理IP和这个代理的可用时间,在这个时间段内,这个代理是可用的。注意:这种代理方式需要有个代理池,因为爬虫一般都是多线程,如果在代理IP可用时间段内,多个线程一直使用同一个代理IP,也会有被封的风险。所以保险的做法就是一个线程一个代理,降低一个代理的请求次数。
第二种代理直接给你一个固定的IP,这个代理IP没有时间限制,代理商那边会帮你自动帮你换不同的IP请求目标地址。
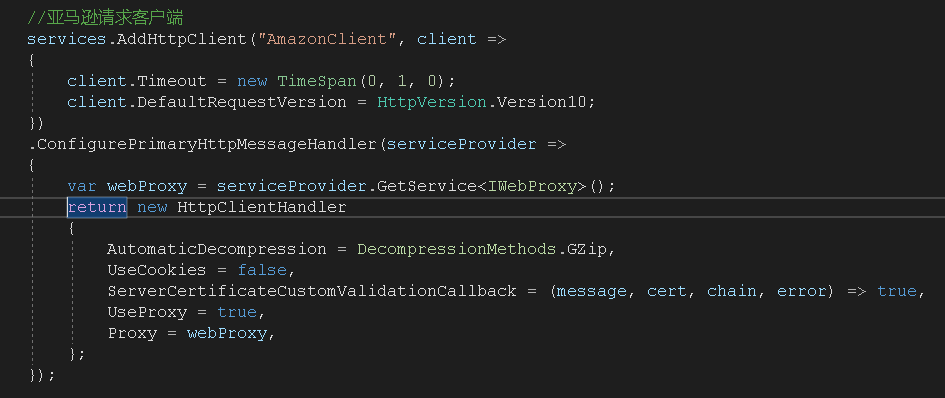
.Net Core中使用代理很简单,因为我使用的是HttpClientFactory,所以在添加服务的时候配置 HttpClientHandler的代理就可以,需要实现一个IWebProxy类,返回对应的代理IP和端口号就可以了。
刚开始使用的是第一种代理,为了实现一个线程一个代理,我创建了一个代理池,在程序启动的时候,每个线程都会从代理商那获取到一个代理IP,然后放到代理池中,每次获取代理的时候,通过代理池中随机挑选一个代理IP,在挑选前会判断当前代理池中的代理数量,如果小于线程数据,就会去获取填充到代理池中。
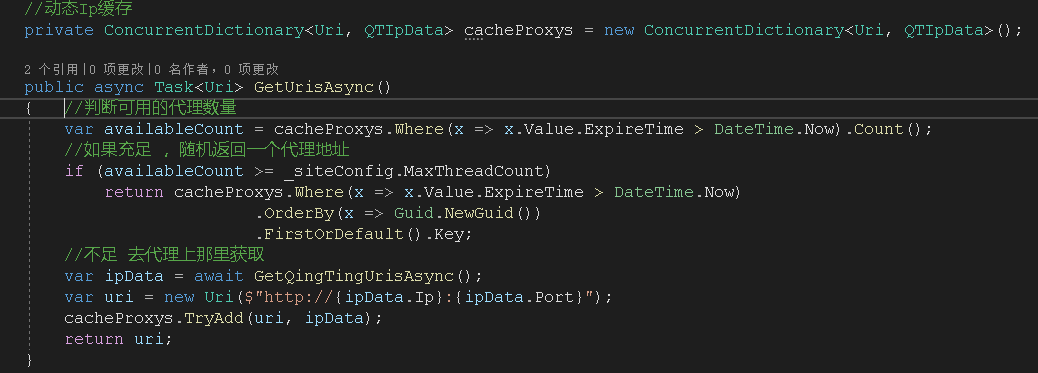
后面发现国内的代理商的IP访问国外网址太慢了,就换了国外代理,国外代理使用的是第二种方案。但是这个代理商不是自动帮你更换IP,而是需要每次传递一个随机数 SessionId,随机数不同,代理商访问目标网站的IP就不同,而且要传用户名和密码。
开始 我是这么做的: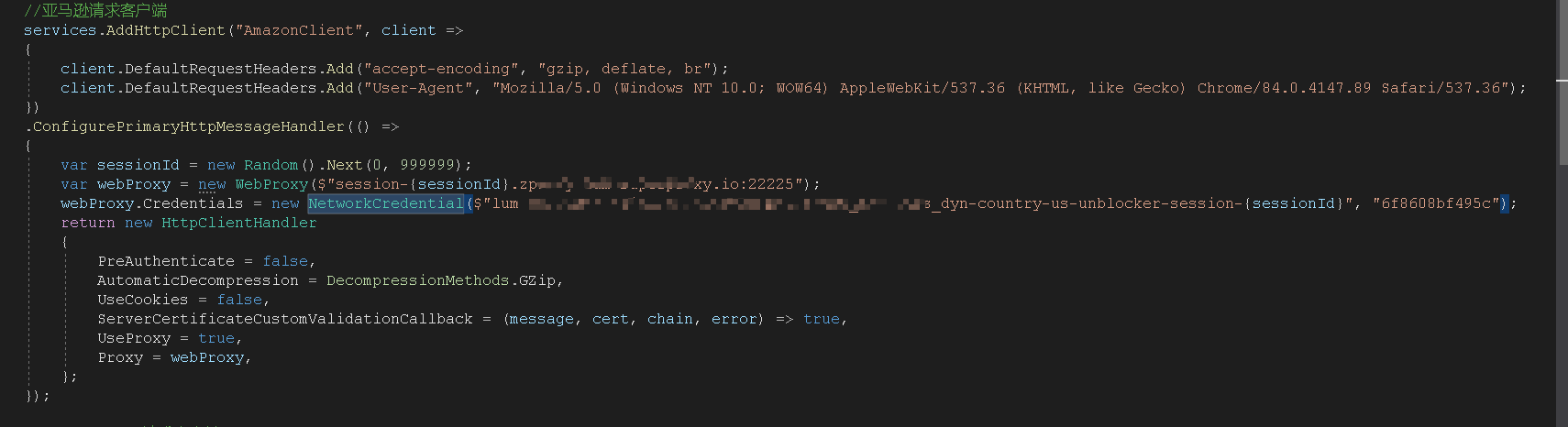
发现这种只有在第一次创建HttpClient的时候才会去走配置ConfigurePrimaryHttpMessageHandler方法,之后创建HttpClient都不会走。就导致一直在使用同一个IP请求。
所以没办法,只能放弃使用HttpClientFactory,自己手动创建HttpClient ,然后释放。但这种又随之带来一个问题HttpClient虽然释放了,但是端口还是被占用着,目前还没有好的解决办法。
四、断点续爬、数据去重
我这个业务中这两个功能就很好实现,每次爬取完成商品页码,就存储下一页的页码和当前爬取的页码数。配置一个参数是否是断点续爬,如果是断点续爬,就从上次记录的页码爬取商品。
数据去重,因为直接可以拿到亚马逊的商品Id和分类Id,所以去重就变的很简单,任务启动的时候,会将已经爬取过的商品Id和分类Id放到缓存中,爬取的时候对比数据。
项目在服务器上跑了2个晚上,表现还是可以的,数据都正确采集到了117w数据(包含未爬取详情的商品),最后的最后。。。。项目被砍了,因为亚马逊的商品详情页数据太大,导致爬了12个小时用了40G流量,1G=6$ ,一个月就要40x2x6x30=14400$。忙碌了两周,也算从零写了一个小小的爬虫,还算有所得。
使用.Net Core做个爬虫的更多相关文章
- 如何让你的scrapy爬虫不再被ban之二(利用第三方平台crawlera做scrapy爬虫防屏蔽)
我们在做scrapy爬虫的时候,爬虫经常被ban是常态.然而前面的文章如何让你的scrapy爬虫不再被ban,介绍了scrapy爬虫防屏蔽的各种策略组合.前面采用的是禁用cookies.动态设置use ...
- ASP.NET CORE做的网站运行在docker实践
用VS2017 建立了 DotNet Core 2.2 的网站后,如何转移到 Docker 下运行? 下面分两种方式来实践: 1.直接手动命今行,将本机目录映射进Docker,运行网站.2.制作 Im ...
- 用.NET CORE做项目,VS里编译碰到‘。。。。包降级。。。。’错误
用.NET CORE做项目,VS里编译碰到‘....包降级....’错误 本地开发机:WIN10+VS2017 15.7.3 ,用CORE2.1版本的建立一个项目,做好了,传到gitee上 今天有新同 ...
- 牛腩学ASP.NET CORE做博客(视频)
牛腩学习ASP.NET CORE做的项目,边学边做. 目录: 01-dotnetcore网站部署到centos7系统上(时长 2:03:16) 02-前期准备及项目搭建 (时长:0:23:35) 03 ...
- 使用AKKA做分布式爬虫的思路
上周公司其它小组在讨论做分布式爬虫,我也思考了一下.提了一个方案,就是使用akka分布式rpc框架来做,自己写master和worker程序,client向master提交begin任务或者其它爬虫需 ...
- .Net Core 做请求监控NLog
使用 NLog 给 Asp.Net Core 做请求监控 https://www.cnblogs.com/cheesebar/p/9078207.html 为了减少由于单个请求挂掉而拖垮整站的情况发生 ...
- win10 uwp 使用 asp dotnet core 做图床服务器客户端
原文 win10 uwp 使用 asp dotnet core 做图床服务器客户端 本文告诉大家如何在 UWP 做客户端和 asp dotnet core 做服务器端来做一个图床工具 服务器端 从 ...
- win10 uwp 手把手教你使用 asp dotnet core 做 cs 程序
本文是一个非常简单的博客,让大家知道如何使用 asp dot net core 做后台,使用 UWP 或 WPF 等做前台. 本文因为没有什么业务,也不想做管理系统,所以看到起来是很简单. Visua ...
- UWP开发之ORM实践:如何使用Entity Framework Core做SQLite数据持久层?
选择SQLite的理由 在做UWP开发的时候我们首选的本地数据库一般都是Sqlite,我以前也不知道为啥?后来仔细研究了一下也是有原因的: 1,微软做的UWP应用大部分也是用Sqlite.或者说是微软 ...
随机推荐
- Docker安装Oracle11g
为什么使用docker安装oracle,因为自己搭建配置的话可能时间太久太繁琐等等原因,也因为docker实在太方便了 本文主要是使用docker-compose安装Oracle 11g,因为使用do ...
- day05-类型转换和变量
1.类型转换概念 java是强类型语言,所以有些运算的时候,需要用到类型转换 类型转换原则:低-->高,byte,short,char-->int-->long-->float ...
- 通过ceph-deploy安装不同版本ceph
之前有在论坛写了怎么用 yum 安装 ceph,但是看到ceph社区的群里还是有人经常用 ceph-deploy 进行安装,然后会出现各种不可控的情况,虽然不建议用ceph-deploy安装,但是既然 ...
- 关于android.view.InflateException【转载】
在AndroidStudio中编译没有问题,但是运行时会crash,常发生于自定义View的引用.出现问题的原因大致分为以下几种 1.引用View的路径问题:如果自定义的view为CustomerVi ...
- Spring Boot优雅地处理404异常
背景 在使用SpringBoot的过程中,你肯定遇到过404错误.比如下面的代码: @RestController @RequestMapping(value = "/hello" ...
- Python_faker (伪装者)创建假数据
faker (伪装者)创建假数据 工作中,有时候我们需要伪造一些假数据,如何使用 Python 伪造这些看起来一点也不假的假数据呢? Python 有一个包叫 Faker,使用它可以轻易地伪造姓名.地 ...
- [原题复现+审计][BUUCTF 2018]WEB Online Tool(escapeshellarg和escapeshellcmd使用不当导致rce)
简介 原题复现:https://github.com/glzjin/buuctf_2018_online_tool (环境php5.6.40) 考察知识点:escapeshellarg和escap ...
- 面经分享!蚂蚁金服三面被拒,重拾起鼓四面猿辅导成功拿下offer!
前言 一直有小伙伴要我分享面经,说自己想面互联网公司,无奈经验太少想多看看其他人是怎么面的.我这两天刚好和一个刚拿到猿辅导offer的朋友吃了个饭,他向我说了说自己的面试经历.粉丝朋友是末流211毕业 ...
- HBase高级特性、rowkey设计以及热点问题处理
在阐述HBase高级特性和热点问题处理前,首先回顾一下HBase的特点:分布式.列存储.支持实时读写.存储的数据类型都是字节数组byte[],主要用来处理结构化和半结构化数据,底层数据存储基于hdfs ...
- prometheus监控实战--基础
1.简介 prometheus就是监控系统+TSDB(时间序列数据库),通过pull方式从exporter获取时间序列数据,存入本地TSDB,被监控端需安装exporter作为http端点暴露指标数据 ...