LWIP再探----内存池管理
这这里是接上一篇内存池管理部分的,这里如果读者一打开memp.c的话会感觉特别那一理解原作者在干嘛,但是看懂了就明白原作者是怎么巧妙的使用了宏。废话不多说先说了下我分析是一下宏的条件是
前提条件
MEMP_STATS = 0
MEMP_OVERFLOW_CHECK = 0
首先要去简单的看下#include "lwip/priv/memp_std.h"文件的格式,只需要明白这个文件依赖LWIP_MEMPOOL(name,num,size,desc)这个宏,并且在文件结尾将宏清除。
因此出现底下的最难的两块
#define LWIP_MEMPOOL(name,num,size,desc) LWIP_MEMPOOL_DECLARE(name,num,size,desc)
#include "lwip/priv/memp_std.h" const struct memp_desc *const memp_pools[MEMP_MAX] = {
#define LWIP_MEMPOOL(name,num,size,desc) &memp_ ## name,
#include "lwip/priv/memp_std.h"
};
先说第一个,继续追LWIP_MEMPOOL_DECLARE的定义如下,看完继续懵逼中。。。,但是不能慌一个个宏替换出来
#define LWIP_MEMPOOL_DECLARE(name,num,size,desc) \
LWIP_DECLARE_MEMORY_ALIGNED(memp_memory_ ## name ## _base, ((num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))); \
\
LWIP_MEMPOOL_DECLARE_STATS_INSTANCE(memp_stats_ ## name) \
\
static struct memp *memp_tab_ ## name; \
\
const struct memp_desc memp_ ## name = { \
DECLARE_LWIP_MEMPOOL_DESC(desc) \
LWIP_MEMPOOL_DECLARE_STATS_REFERENCE(memp_stats_ ## name) \
LWIP_MEM_ALIGN_SIZE(size), \
(num), \
memp_memory_ ## name ## _base, \
&memp_tab_ ## name \
};
里面相关宏的实现汇总如下
#ifndef LWIP_DECLARE_MEMORY_ALIGNED
#define LWIP_DECLARE_MEMORY_ALIGNED(variable_name, size) u8_t variable_name[LWIP_MEM_ALIGN_BUFFER(size)]
#endif #define LWIP_MEMPOOL_DECLARE_STATS_INSTANCE(name) #define DECLARE_LWIP_MEMPOOL_DESC(desc) #define LWIP_MEMPOOL_DECLARE_STATS_REFERENCE(name) #define LWIP_MEM_ALIGN_SIZE(size) (((size) + MEM_ALIGNMENT - 1U) & ~(MEM_ALIGNMENT-1U))
最后就有这样一个过程
#define LWIP_MEMPOOL_DECLARE(name,num,size,desc) \
LWIP_DECLARE_MEMORY_ALIGNED(memp_memory_ ## name ## _base, ((num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))); \
\
LWIP_MEMPOOL_DECLARE_STATS_INSTANCE(memp_stats_ ## name) \
\
static struct memp *memp_tab_ ## name; \
\
const struct memp_desc memp_ ## name = { \
DECLARE_LWIP_MEMPOOL_DESC(desc) \
LWIP_MEMPOOL_DECLARE_STATS_REFERENCE(memp_stats_ ## name) \
LWIP_MEM_ALIGN_SIZE(size), \
(num), \
memp_memory_ ## name ## _base, \
&memp_tab_ ## name \
}; |
|
\|/ #define LWIP_MEMPOOL_DECLARE(name,num,size,desc) \ memp_memory_RAW_PCB_base[(num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))]; \
static struct memp *memp_tab_RAW_PCB; \
const struct memp_desc memp_RAW_PCB = {\
LWIP_MEM_ALIGN_SIZE(size), \
(num), \
memp_memory_RAW_PCB _base,\
&memp_tab_ RAW_PCB\
};
然后就是这样子的宏替换,此处未全部列举
#define LWIP_MEMPOOL(name,num,size,desc) LWIP_MEMPOOL_DECLARE(name,num,size,desc)
#include "lwip/priv/memp_std.h"
|
|
\|/
memp_memory_RAW_PCB_base[(num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))]; \
static struct memp *memp_tab_RAW_PCB;
const struct memp_desc memp_RAW_PCB = {
“RAW_PCB”
LWIP_MEM_ALIGN_SIZE(size),
(num),
memp_memory_RAW_PCB _base,
&memp_tab_ RAW_PCB
}; memp_memory_UDP_PCB_base[(num) * (MEMP_SIZE + MEMP_ALIGN_SIZE(size)))]; \
static struct memp *memp_tab_UDP_PCB;
const struct memp_desc memp_UDP_PCB = {
“UDP_PCB”
LWIP_MEM_ALIGN_SIZE(size),
(num),
memp_memory_UDP_PCB _base,
&memp_tab_UDP_PCB
};
.
.
.
,同理理解到这里下面继续第二个宏就是同理结果如下
const struct memp_desc *const memp_pools[MEMP_MAX] = {
#define LWIP_MEMPOOL(name,num,size,desc) &memp_ ## name,
#include "lwip/priv/memp_std.h"
};
|
|
\|/
const struct memp_desc *const memp_pools[MEMP_MAX] = {
&memp_RAW_PCB,
&memp_UDP_PCB,
.
.
.
}
注意这里的MEMP_MAX是这样来的
typedef enum {
#define LWIP_MEMPOOL(name,num,size,desc) MEMP_##name,
#include "lwip/priv/memp_std.h"
MEMP_MAX
} memp_t;
|
|
\|/
typedef enum {
MEMP_RAW_PCB,
MEMP_UDP_PCB,
.
.
.
MEMP_MAX
} memp_t;
然后这里还还需要了解一个结构体的定义如下,
struct memp_desc {
#if defined(LWIP_DEBUG) || MEMP_OVERFLOW_CHECK || LWIP_STATS_DISPLAY
/** Textual description */
const char *desc;
#endif /* LWIP_DEBUG || MEMP_OVERFLOW_CHECK || LWIP_STATS_DISPLAY */
/** Element size */
u16_t size;
#if !MEMP_MEM_MALLOC
/** Number of elements */
u16_t num;
/** Base address */
u8_t *base;
/** First free element of each pool. Elements form a linked list. */
struct memp **tab;
#endif /* MEMP_MEM_MALLOC */
};
这样memp_pools就将整个mempool的内存串到了一个结构体数组中。要注意此时每个memp_pools中的memp_desc结构体中的memp_tab_UDP_PCB还只是一个指针的指针,并未有具体的实际意义。然后memp_init会进行这一工作,去掉宏不编译的部分
memp_init如下
void memp_init(void)
{
u16_t i;
/* for every pool: */
for (i = 0; i < LWIP_ARRAYSIZE(memp_pools); i++) {
memp_init_pool(memp_pools[i]);
}
}
就是循环调用memp_init_pool,接着看去掉宏简化后的memp_init_pool
void
memp_init_pool(const struct memp_desc *desc)
{
int i;
struct memp *memp; *desc->tab = NULL;
memp = (struct memp *)LWIP_MEM_ALIGN(desc->base); /* create a linked list of memp elements */
for (i = 0; i < desc->num; ++i) {
memp->next = *desc->tab;
*desc->tab = memp;
memp = (struct memp *)(void *)((u8_t *)memp + MEMP_SIZE + desc->size
}
}
到这里所有内存池的定义和初始化已经完成了借用野火的一张图,初始化后的pool结构如下
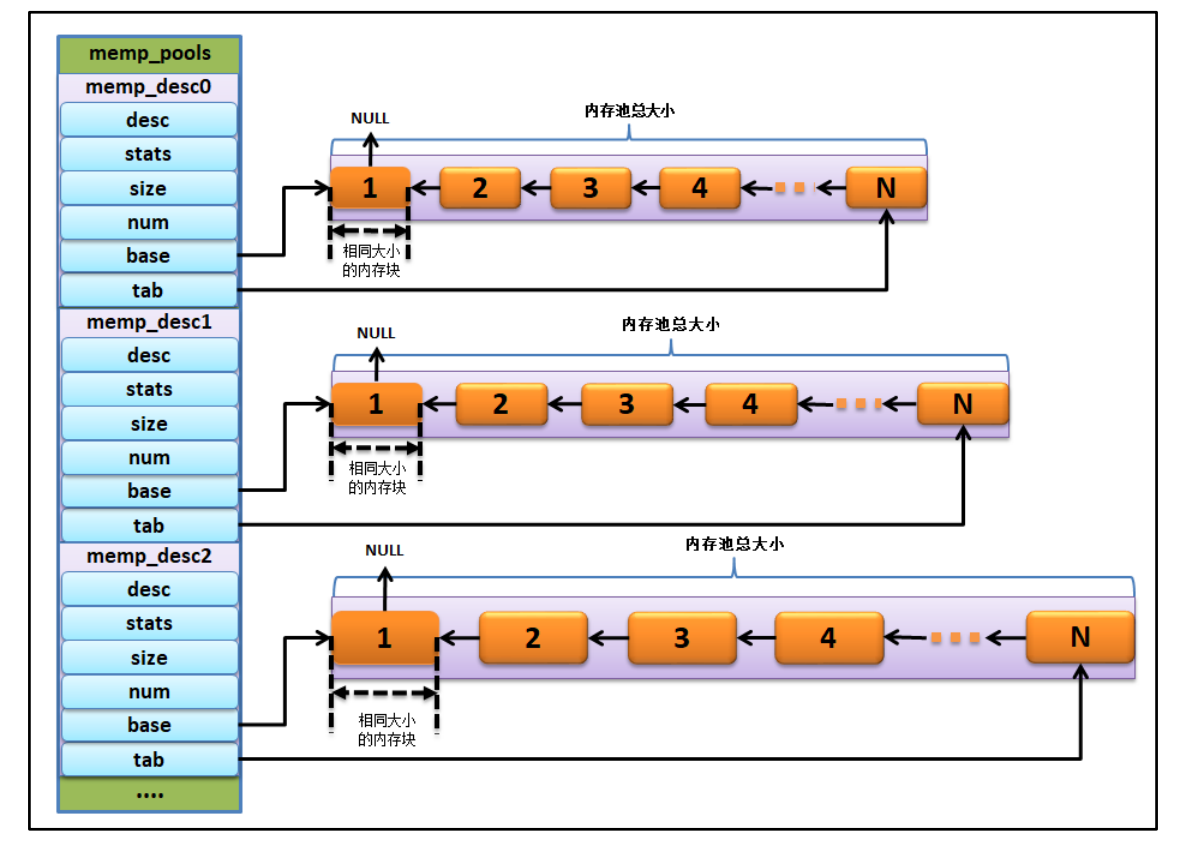
每一个类型的池最后由,tab将所有的空闲池串起来,组成一个内存池单向链表。到此最难理解的部分已经完了,接下来内存池的内存分配和释放就是很简单的内容了。
内存申请
void * memp_malloc(memp_t type){
void *memp;
// 取对应内存池的控制块
memp = do_memp_malloc_pool(memp_pools[type]);
return memp;
}
//这个函数内部实际上调用了 do_memp_malloc_pool简化后如下,
static void * do_memp_malloc_pool(const struct memp_desc *desc)
{
struct memp *memp;
SYS_ARCH_DECL_PROTECT(old_level);
SYS_ARCH_PROTECT(old_level);
memp = *desc->tab;
if (memp != NULL) {
*desc->tab = memp->next;
SYS_ARCH_UNPROTECT(old_level);
/* cast through u8_t* to get rid of alignment warnings */
return ((u8_t *)memp + MEMP_SIZE);
} else {
SYS_ARCH_UNPROTECT(old_level);
}
return NULL;
}
因为tab是空闲pool的头,所以内存申请直接就是返回tab指向pool就可以了。同时内存释放就是将pool从新插入单向链表的操作了。具体简化的代码如下
内存释放
void memp_free(memp_t type, void *mem)
{
if (mem == NULL) {
return;
}
do_memp_free_pool(memp_pools[type], mem); }
//调用do_memp_free_pool
static void do_memp_free_pool(const struct memp_desc *desc, void *mem)
{
struct memp *memp;
SYS_ARCH_DECL_PROTECT(old_level); /* cast through void* to get rid of alignment warnings */
memp = (struct memp *)(void *)((u8_t *)mem - MEMP_SIZE);
SYS_ARCH_PROTECT(old_level);
memp->next = *desc->tab;
*desc->tab = memp; SYS_ARCH_UNPROTECT(old_level); }
现在LWIP的两种内存策略的实现方式,都已经理解过了,其中内存池的溢出检测部分没有说,但是已经可以帮助我们使用LWIP了,作者设计两种内存策略是有他的设计初衷的,看了#include "lwip/priv/memp_std.h"文件就知道,内存池的出现就是为一些特殊的长度固定的数据结构设计的,他分配快速,释放亦是,并且很定不会有内存碎片,但是这还是一种空间换时间的做法,因为内存池申请函数,支持如果当前尺寸的pool用完了,可以分配更大的池。内存堆就是用来应对大小不定的内存分配场合的,当人LWIP支持用堆实现pool也支持用pool实现堆,同时还支持用户池,这些功能都可以通过宏简单 的配置具体如下
MEM_LIBC_MALLOC 使用C库
MEMP_MEM_MALLOC 使用内存堆替换内衬池。
MEM_USE_POOLS 使用内存池替换内存堆
MEMP_USE_CUSTOM_POOLS 使用用户定义的内存池,这个实现需要用户提供一个文件lwippools.h,并按如下形式定义字节的内存池,要求内存池的大小要依次增大。
LWIP_MALLOC_MEMPOOL_START LWIP_MALLOC_MEMPOOL(20, 256) LWIP_MALLOC_MEMPOOL(10, 512) LWIP_MALLOC_MEMPOOL(5, 1512) LWIP_MALLOC_MEMPOOL_END
好了,到此LWIP的内存管理部分算是简单的学习了一下了,内存管理完。
2019-06-16 17:58:42
LWIP再探----内存池管理的更多相关文章
- LWIP再探----内存堆管理
LWIP的内存管理主要三种:内存池Pool,内存堆,和C库方式.三种方式中C库因为是直接从系统堆中分配内存空间且易产生碎片因此,基本不会使用,其他两种是LWIP默认全部采用的方式,也是综合效率和空间的 ...
- 【uTenux实验】内存池管理(固定内存池和可变内存池)
1.固定内存池管理实验 内存管理是操作系统的一个基础功能.uTenux的内存池管理函数提供了基于软件的内存池管理和内存块分配管理.uTenux的内存池有固定大小的内存池和大小可变的内存池之分,它们被看 ...
- Linux简易APR内存池学习笔记(带源码和实例)
先给个内存池的实现代码,里面带有个应用小例子和画的流程图,方便了解运行原理,代码 GCC 编译可用.可以自己上网下APR源码,参考代码下载链接: http://pan.baidu.com/s/1hq6 ...
- Boost内存池使用与测试
目录 Boost内存池使用与测试 什么是内存池 内存池的应用场景 安装 内存池的特征 无内存泄露 申请的内存数组没有被填充 任何数组内存块的位置都和使用operator new[]分配的内存块位置一致 ...
- nginx源码分析——内存池
内存池的目的就是管理内存,使回收内存可以自动化一些. ngx_palloc.h /* * Copyright (C) Igor Sysoev * Copyright (C) Nginx, Inc. * ...
- PooledByteBuf内存池-------这个我现在不太懂
转载自:http://blog.csdn.net/youaremoon/article/details/47910971 http://blog.csdn.net/youar ...
- nginx源码分析—内存池结构ngx_pool_t及内存管理
Content 0. 序 1. 内存池结构 1.1 ngx_pool_t结构 1.2 其他相关结构 1.3 ngx_pool_t的逻辑结构 2. 内存池操作 2.1 创建内存池 2.2 销毁内存池 2 ...
- netty源码解解析(4.0)-24 ByteBuf基于内存池的内存管理
io.netty.buffer.PooledByteBuf<T>使用内存池中的一块内存作为自己的数据内存,这个块内存是PoolChunk<T>的一部分.PooledByteBu ...
- C语言内存管理(内存池)
C语言可以使用alloc从栈上动态分配内存. 内存碎片 Malloc/free或者new/delete大量使用会造成内存碎片,这种碎片形成的机理如下: 内存碎片一般是由于空闲的内存空间比要连续申请的空 ...
随机推荐
- 使用npm install安装项目依赖的时候报错
使用npm install安装项目依赖的时候报错: npm ERR! code ELIFECYCLE npm ERR! errno 1 npm ERR! node-sass@4.14.1 postin ...
- (转载)微软数据挖掘算法:Microsoft 神经网络分析算法(10)
前言 有段时间没有进行我们的微软数据挖掘算法系列了,最近手头有点忙,鉴于上一篇的神经网络分析算法原理篇后,本篇将是一个实操篇,当然前面我们总结了其它的微软一系列算法,为了方便大家阅读,我特地整理了一篇 ...
- LOJ10075 农场派对
USACO 2007 Feb. Silver N(1≤N≤1000) 头牛要去参加一场在编号为 x(1≤x≤N) 的牛的农场举行的派对.有 M(1≤M≤100000) 条有向道路,每条路长Ti(1≤ ...
- H5Slides幻灯演示系统
H5Slides幻灯演示系统基于HTML5的幻灯片编辑,播放的工具. 通过HTML5的技术,可以在浏览器上进行编辑.传播.控制幻灯片. 选择样板模式 添加新的页面 特点 它是HTML5的! 不需要臃肿 ...
- Java中运行javascript代码
Java中运行javascript代码 1.Java 代码 2.JS代码 2.1demoWithParams.js 2.2demoWithListParams.js 原文作者:russle 原文地址: ...
- scala之map,List,:: , +:, :+, :::, +++操作
scala之map,List操作 1.Map操作 2.List操作 2.1Demo1 2.2Demo2 3.:: , +:, :+, :::, +++ 1.Map操作 Map(映射)是一种可迭代的键值 ...
- JavaScript学习(一)——引擎,运行时,调用堆栈
JavaScript引擎 谷歌 V8 引擎是流行的 JavaScript 引擎之一.V8 引擎在诸如 Chrome 和 Node.js 内部使用. 引擎包括两个主要组件: 动态内存管理 – 在这里分配 ...
- stop脚本
PID=$(ps -ef | grep eladmin-system-2.0.jar | grep -v grep | awk '{ print $2 }')if [ -z "$PID&qu ...
- python模块----paramicko模块 (ssh远程主机并命令或传文件)
paramiko模块 paramicko模块是非标准库模块,需要pip下载 paramicko:模拟ssh登陆linux主机,也有上传下载功能.ansible自动化部署软件底层就有应用paramick ...
- 23.centos 7配置网络
1.ifconfig:查看网卡信息 如果centos7 最小化安装没有ifconfig这个命令,可以使用yum install net-tools 来安装. centos7 网卡命名规则: en ...