Python可视化库-Matplotlib使用总结
在做完数据分析后,有时候需要将分析结果一目了然地展示出来,此时便离不开Python可视化工具,Matplotlib是Python中的一个2D绘图工具,是另外一个绘图工具seaborn的基础包
先总结下绘制子图的步骤:
1.确定绘制的图形形状(如折线图/条状图/柱状图/饼图/散点图等)
2.填充x/y轴的数据
3.图形细节调整(这里可以做很多调整,如x/y轴文字参数说明,颜色/线粗/柱状粗度,x/y轴文字角度等)
4.显示图像(调用show())
总结下一个区域同时绘制多个子图的步骤
1.确定绘图区域大小
2.确定每个子图在绘图区域的位置
3.绘制每个子图(步骤如上)
4.显示图像(调用show())
绘制折线图
需求:根据一张美国的失业率数据,绘制出1948年12个月中的失业率折线图,其中x轴表示月份,y轴表示失业率
数据如下
DATE VALUE
0 1948-01-01 3.4
1 1948-02-01 3.8
2 1948-03-01 4.0
3 1948-04-01 3.9
4 1948-05-01 3.5
5 1948-06-01 3.6
6 1948-07-01 3.6
7 1948-08-01 3.9
8 1948-09-01 3.8
9 1948-10-01 3.7
10 1948-11-01 3.8
11 1948-12-01 4.0
unrate.csv
上代码
#导包
import pandas as pd
import matplotlib.pyplot as plt
# 读取本地的csv文件,里面的数据为美国失业率数据,得到的数据为DataFrame类型
unrate = pd.read_csv('unrate.csv')
# 使用pd中的pd.to_datetime函数将DATE列的字符串类型数据转换成pd中的标准时间格式
unrate['DATE'] = pd.to_datetime(unrate['DATE'])
# 取出前面12条样本数据
first_twelve = unrate[0:12]
# 填充数据并绘制折线图,第一个参数为x轴数据,第二个参数为y轴数据
plt.plot(first_twelve['DATE'], first_twelve['VALUE'])
# 将x轴下面文字旋转90度
plt.xticks(rotation=90)
# 设置x轴的标签
plt.xlabel('Month')
# 设置y轴的标签
plt.ylabel('Unemployment Rate')
# 设置图标名称
plt.title('Monthly Unemployment Trends, 1948')
# 显示图像
plt.show()
图像如图所示:
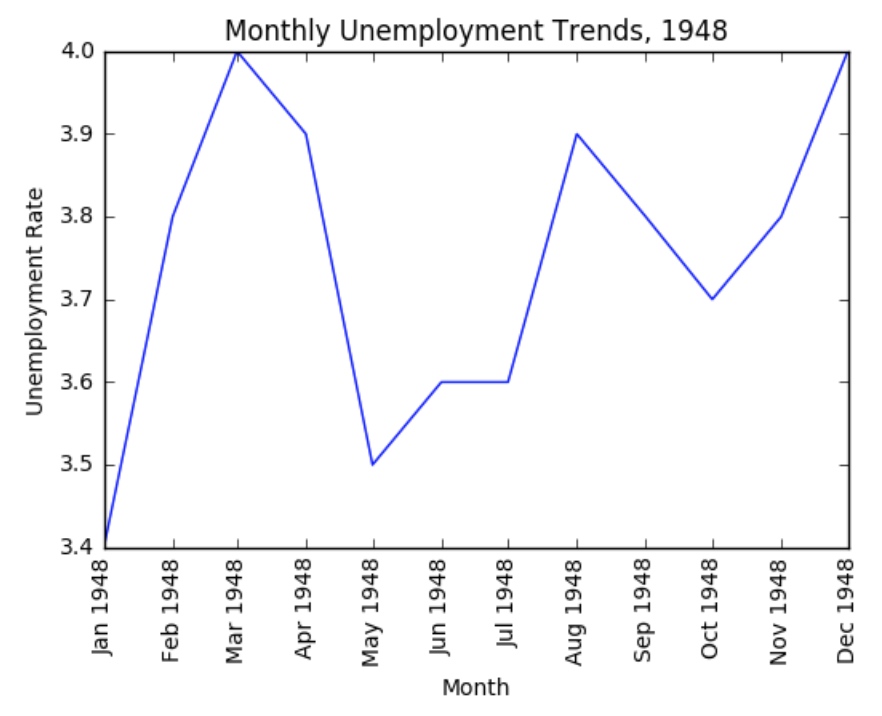 

在一个区域绘制多个子图
有时候,需要将多张图像在一块区域显示,方便对比
上代码:
# 导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 确定总绘图区宽和高分别为都是3x6
fig = plt.figure(figsize=(3, 6))
# 添加第一个子图,并且确定在总绘图区域的位置,add_subpolt(2,1,1),前两个参数参数2,1表示将总绘图区域划分为两行1列(跟矩阵表示很像)
# 第3个参数表示该子图占总区域的第一个位置.注(将总区域分成2行1列后,位置顺序从上到下,从左到右,从1开始递增)
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
# 绘制子图
ax1.plot(np.random.randint(1,5,5), np.arange(5))
ax2.plot(np.arange(10)*3, np.arange(10))
# 显示图像
plt.show()
图像如图所示

在一张图中同时绘制多条曲线
需求:在同一张图,同时将1948到1952年的失业率展示出来,曲线使用不同的颜色区分
上代码
#绘制5年内的失业率曲线图
#导包
import numpy as np
import pandas as pd
import matplotlib.pypolt as plt
# 读取本地数据
unrate=pd.read_csv('UNRATE.csv')
# 将字符串时间转换成pd中的时间格式
unrate['DATE']=pd.to_datetime(unrate['DATE'])
# 将年份时间转换成月份时间,并新建列存起来,因为需求需要将5年内的当年12个月内的失业率展示出来,此时再用年时间作为x轴下标就不合适了
unrate['MONTH']=unrate['DATE'].dt.month
# 设置5个颜色数组,分别表示5条曲线颜色
colors=['red','green','blue','black','yellow']
# 设置总绘图区域大小,需要在调用绘图函数之前调用才有效果
plt.figure(figsize=(10,6))
#遍历5次
for i in range(5):
#取出当年12个月的数据
data12=unrate[12*i:12*(i+1)]
#x轴数据
data_x=data12['MONTH']
#y轴数据
data_y=data12['VALUE']
#当年的曲线的标签
label=str(1948+i)
# 绘制当年的曲线图
plt.plot(data_x,data_y,c=colors[i],label=label)
# 设置x轴标签
plt.xlabel('MONTH')
# 设置y轴标签
plt.ylabel('unrate')
# 设置图标名称
plt.title('US-unrae,1948-1952')
# 设置曲线标签说明,loc='best'表示自己选择合适的位置来摆放
plt.legend(loc='best')
# 显示图像
plt.show()
得到的图像:
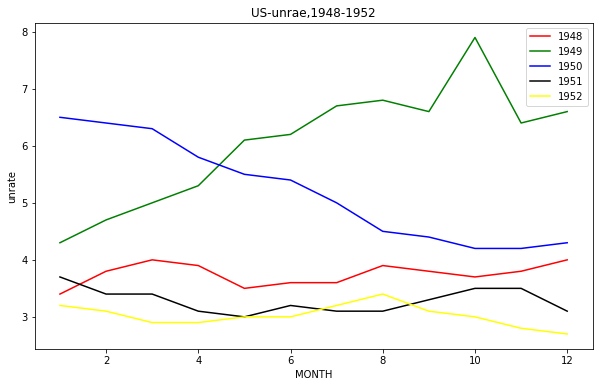 

绘制条形图
直方图和条形图的区别:由于分组数据具有连续性,直方图中的各矩形通常是连续排列,而条形图则是分开排列。此外直方图的高度表示各小组内数据个数,而条形图高度表示某项目内的数据个数。
fandango_scores.csv
上代码:
# 导包
import pandas as pd
import matplotlib.pyplot as plt
from numpy import arange
# 读取电影评分数据
reviews = pd.read_csv('fandango_scores.csv')
# 取出需要展示的列名
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
# 取出需要展示的样本数据
norm_reviews = reviews[cols]
# 评分数据的列名
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
# 取出第一部电影的评分样本数据
bar_heights = norm_reviews.loc[0, num_cols].values
# 条形图的位置
bar_positions = arange(5) + 0.75
tick_positions = range(1,6)
fig, ax = plt.subplots()
# 绘制条形图,第一个参数为x轴数据,第二个参数为y轴数据,第三个参数为每个条形的宽度
ax.bar(bar_positions, bar_heights,0.5)
# 设置x轴标签的位置
ax.set_xticks(tick_positions)
# 设置x轴标签的名字和角度
ax.set_xticklabels(num_cols, rotation=45)
# 设置x轴标签
ax.set_xlabel('Rating Source')
# y轴标签
ax.set_ylabel('Average Rating')
# 标题
ax.set_title('Average User Rating For Avengers: Age of Ultron (2015)')
plt.show()
绘制的图片:
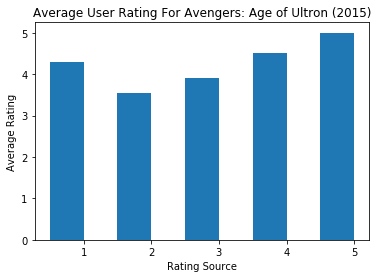 

绘制直方图
直方图一般用来统计一定范围内的数据
上代码
import pandas as pd
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
norm_reviews = reviews[cols]
# 对评分进行数量统计
fandango_distribution = norm_reviews['Fandango_Ratingvalue'].value_counts()
# 排序索引
fandango_distribution = fandango_distribution.sort_index()
imdb_distribution = norm_reviews['IMDB_norm'].value_counts()
imdb_distribution = imdb_distribution.sort_index()
fig, ax = plt.subplots()
# 绘制直方图
ax.hist(norm_reviews['Fandango_Ratingvalue'],bins=20)
plt.show()
绘制所得图像:
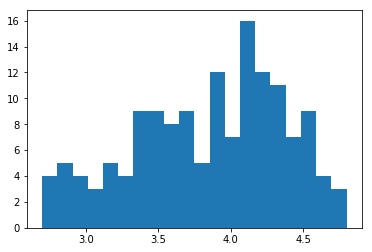 

绘制散点图
上代码:
# 导包
import pandas as pd
import matplotlib.pyplot as plt
from numpy import arange
# 读取电影评分数据
norm_reviews = pd.read_csv('fandango_scores.csv')
# 取出需要展示的列名
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue', 'Fandango_Stars']
# 取出需要展示的样本数据
norm_reviews = reviews[cols]
fig, ax = plt.subplots()
#绘制散点图
ax.scatter(norm_reviews['Fandango_Ratingvalue'], norm_reviews['RT_user_norm'])
ax.set_xlabel('Fandango')
ax.set_ylabel('Rotten Tomatoes')
plt.show()
绘制所得图片:
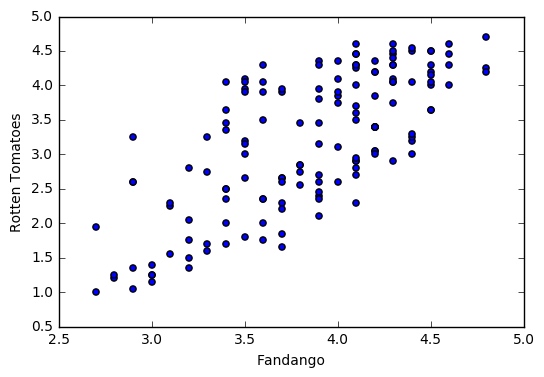 

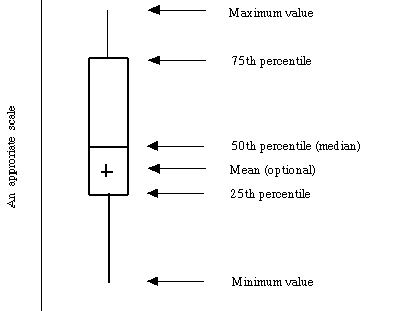
绘制盒图
箱形图(英文:Box-plot),又称为盒须图、盒式图、盒状图或箱线图,是一种用作显示一组数据分散情况资料的统计图。因型状如箱子而得名。在各种领域也经常被使用,常见于品质管理。不过作法相对较繁琐。它能显示出一组数据的最大值、最小值、中位数、下四分位数及上四分位数。

上代码:
import pandas as pd
import matplotlib.pyplot as plt
reviews = pd.read_csv('fandango_scores.csv')
cols = ['FILM', 'RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
norm_reviews = reviews[cols]
num_cols = ['RT_user_norm', 'Metacritic_user_nom', 'IMDB_norm', 'Fandango_Ratingvalue']
fig, ax = plt.subplots()
#绘制盒图
ax.boxplot(norm_reviews[num_cols].values)
ax.set_xticklabels(num_cols, rotation=90)
ax.set_ylim(0,5)
plt.show()
绘制所得图片:
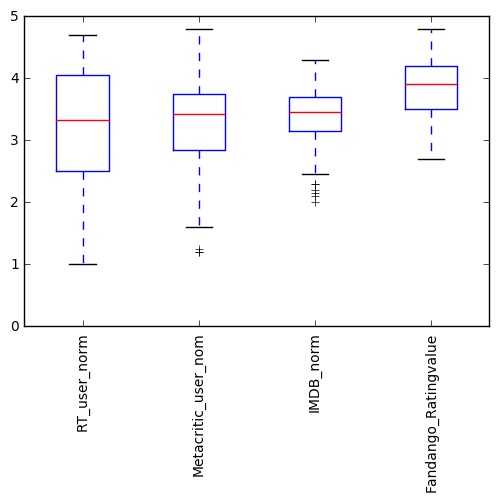 

Python可视化库-Matplotlib使用总结的更多相关文章
- Python可视化库Matplotlib的使用
一.导入数据 import pandas as pd unrate = pd.read_csv('unrate.csv') unrate['DATE'] = pd.to_datetime(unrate ...
- python可视化库 Matplotlib 01 figure的详细用法
1.上一章绘制一幅最简单的图像,这一章介绍figure的详细用法,figure用于生成图像窗口的方法,并可以设置一些参数 2.先看此次生成的图像: 3.代码(代码中有详细的注释) # -*- enco ...
- python可视化库 Matplotlib 00 画制简单图像
1.下载方式:直接下载Andaconda,简单快捷,减少准备环境的时间 2.图像 3.代码:可直接运行(有详细注释) # -*- encoding:utf-8 -*- # Copyright (c) ...
- Pycon 2017: Python可视化库大全
本文首发于微信公众号“Python数据之道” 前言 本文主要摘录自 pycon 2017大会的一个演讲,同时结合自己的一些理解. pycon 2017的相关演讲主题是“The Python Visua ...
- Python可视化库
转自小小蒲公英原文用Python可视化库 现如今大数据已人尽皆知,但在这个信息大爆炸的时代里,空有海量数据是无实际使用价值,更不要说帮助管理者进行业务决策.那么数据有什么价值呢?用什么样的手段才能把数 ...
- Python数据可视化库-Matplotlib(一)
今天我们来学习一下python的数据可视化库,Matplotlib,是一个Python的2D绘图库 通过这个库,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率图,条形图,错误图,散点图等等 废 ...
- python的数据可视化库 matplotlib 和 pyecharts
Matplotlib大家都很熟悉 不谈. ---------------------------------------------------------------------------- ...
- 高效使用 Python 可视化工具 Matplotlib
Matplotlib是Python中最常用的可视化工具之一,可以非常方便地创建海量类型的2D图表和一些基本的3D图表.本文主要介绍了在学习Matplotlib时面临的一些挑战,为什么要使用Matplo ...
- Python 可视化工具 Matplotlib
英文出处:Chris Moffitt. Matplotlib是Python中最常用的可视化工具之一,可以非常方便地创建海量类型的2D图表和一些基本的3D图表.本文主要介绍了在学习Matplotlib时 ...
随机推荐
- Linux双网卡搭建NAT服务器之网络应用
一:拓扑.网络结构介绍 Eth1 外网卡的IP 地址, GW和DNS 按照提供商提供配置.配置如下: IP:114.242.25.18 NETMASK:255.255.255.0 GW:114.242 ...
- 移动web页面给用户发送邮件的方法
微信商户通有这么一个需求,用户打开H5页面后,引导用户到电脑下载设计资源包,由于各种内部原因,被告知无后台资源支持,自己折腾了一段时间找了下面2个办法,简单做下笔记. 使用mailto功能,让用户自己 ...
- object类的equals方法简介 & String类重写equals方法
object类中equals方法源码如下所示 public boolean equals(Object obj) { return this == obj; } Object中的equals方法是直接 ...
- 标签(Label、JLabel)
构造函数 Label( ) Label(String str) Label(String str, int how) 第一种形式生成一个空白标签:第二种形式生成一个包含由参数str所设定的字符串的标签 ...
- Java经典编程题50道之十五
输入三个整数x,y,z,请把这三个数由小到大输出. public class Example15 { public static void main(String[] args) { ...
- Activt工作流数据库对应表的作用
1.资源库流程规则表 1) act_re_deployment 部署信息表 2) act_re_model 流程设计模型部署表 3) ...
- Mysql 远程登录及常用命令
第一招.mysql服务的启动和停止 net stop mysql net start mysql 第二招.登陆mysql 语法如下: mysql -u用户名 -p用户密码 键入命令mysql -uro ...
- Egret学习笔记 (Egret打飞机-6.实现敌机飞起来)
有了子弹,总得有敌人来打吧,不然游戏有啥意思呢?今天我们来实现敌机从屏幕上边往下飞 参考微信打飞机游戏里面,敌机分为3种 1是特小飞机,2是小飞机,还有一种就是大飞机 面向对象编程提倡抽象,实现代码复 ...
- Create小程序
我有时候喜欢直接用命令行创建.编译.执行java文件, 每次创建一个文件都要新建一个.java文件,然后再编辑.java文件加入类名,主函数…… 这些流程我有点厌倦,于是就编写了一个超级简单的自动创建 ...
- RotatedRect 类的用法
RotatedRect 以 Emgu.CV.Structure 为命名空间. 表示带有旋转角度的矩形. 结构说明 普通矩形的基本结构