LruCache的缓存策略
一、Android中的缓存策略
一般来说,缓存策略主要包含缓存的添加、获取和删除这三类操作。如何添加和获取缓存这个比较好理解,那么为什么还要删除缓存呢?这是因为不管是内存缓存还是硬盘缓存,它们的缓存大小都是有限的。当缓存满了之后,再想其添加缓存,这个时候就需要删除一些旧的缓存并添加新的缓存。
因此LRU(Least Recently Used)缓存算法便应运而生,LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。采用LRU算法的缓存有两种:LrhCache和DisLruCache分别用于实现内存缓存和硬盘缓存,其核心思想都是LRU缓存算法。
二、LruCache的使用
LruCache是Android 3.1所提供的一个缓存类,所以在Android中可以直接使用LruCache实现内存缓存。而DisLruCache目前在Android 还不是Android SDK的一部分,但Android官方文档推荐使用该算法来实现硬盘缓存。
1.LruCache的介绍
LruCache是个泛型类,主要算法原理是把最近使用的对象用强引用(即我们平常使用的对象引用方式)存储在 LinkedHashMap 中。当缓存满时,把最近最少使用的对象从内存中移除,并提供了get和put方法来完成缓存的获取和添加操作。
2.LruCache的使用
LruCache的使用非常简单,我们就已图片缓存为例。
int maxMemory = (int) (Runtime.getRuntime().totalMemory()/);
int cacheSize = maxMemory/;
mMemoryCache = new LruCache<String,Bitmap>(cacheSize){
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight()/
;
}
①设置LruCache缓存的大小,一般为当前进程可用容量的1/8。
②重写sizeOf方法,计算出要缓存的每张图片的大小。
注意:缓存的总容量和每个缓存对象的大小所用单位要一致。
三、LruCache的实现原理
LruCache的核心思想很好理解,就是要维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,将放在队尾,即将被淘汰。而最近访问的对象将放在队头,最后被淘汰。
如下图所示:
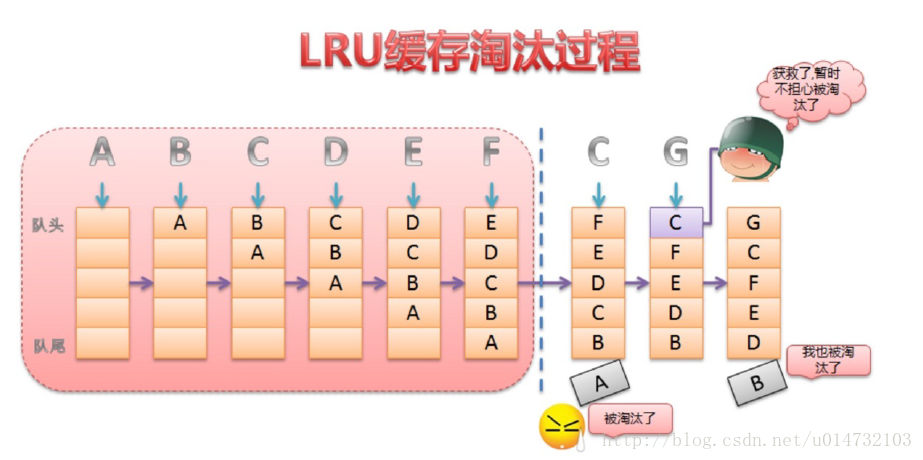
那么这个队列到底是由谁来维护的,前面已经介绍了是由LinkedHashMap来维护。而LinkedHashMap是由数组+双向链表的数据结构来实现的。其中双向链表的结构可以实现访问顺序和插入顺序,使得LinkedHashMap中的对按照一定顺序排列起来。
通过下面构造函数来指定LinkedHashMap中双向链表的结构是访问顺序还是插入顺序。
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
其中accessOrder设置为true则为访问顺序,为false,则为插入顺序。
以具体例子解释: 当设置为true时
public static final void main(String[] args) {
LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(, 0.75f, true);
map.put(, );
map.put(, );
map.put(, );
map.put(, );
map.put(, );
map.put(, );
map.put(, );
map.get();
map.get();
for (Map.Entry<Integer, Integer> entry : map.entrySet())
{
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
输出结果:0:0 3:3 4:4 5:5 6:6 1:1 2:2
即最近访问的最后输出,那么这就正好满足的LRU缓存算法的思想。可见LruCache巧妙实现,就是利用了LinkedHashMap的这种数据结构。
下面我们在LruCache源码中具体看看,怎么应用LinkedHashMap来实现缓存的添加,获得和删除的。
public LruCache(int maxSize) {
if (maxSize <= ) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(, 0.75f, true);
}
从LruCache的构造函数中可以看到正是用了LinkedHashMap的访问顺序。
put()方法:
public final V put(K key, V value) {
//不可为空,否则抛出异常
if (key == null || value == null) {
throw new NullPointerException("key == null || value== null");
}
V previous;
synchronized (this) {
//插入的缓存对象值加1
putCount++;
//增加已有缓存的大小
size += safeSizeOf(key, value);
//向map中加入缓存对象
previous = map.put(key, value);
//如果已有缓存对象,则缓存大小恢复到之前
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
//entryRemoved()是个空方法,可以自行实现
if (previous != null) {
entryRemoved(false, key, previous, value);
}
//调整缓存大小(关键方法)
trimToSize(maxSize);
return previous;
}
可以看到put()方法并没有什么难点,重要的就是在添加过缓存对象后,调用trimToSize()方法,来判断缓存是否已满,如果满了就要删除近期最少使用的算法。
trimToSize()方法:
public void trimToSize(int maxSize) {
//死循环
while (true) {
K key;
V value;
synchronized (this) {
//如果map为空并且缓存size不等于0或者缓存size小于0,抛出异常
if (size < || (map.isEmpty() && size != )) {
throw new IllegalStateException(getClass().getName()+ ".sizeOf() is reporting inconsistent results!");
}
//如果缓存大小size小于最大缓存,或者map为空,不需要再删除缓存对象,跳出循环
if (size <= maxSize || map.isEmpty()) {
break;
}
//迭代器获取第一个对象,即队尾的元素,近期最少访问的元素
Map.Entry<K, V> toEvict = map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
//删除该对象,并更新缓存大小
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
trimToSize()方法不断地删除LinkedHashMap中队尾的元素,即近期最少访问的,直到缓存大小小于最大值。
当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序。这个更新过程就是在LinkedHashMap中的get()方法中完成的。
先看LruCache的get()方法:
public final V get(K key) {
//key为空抛出异常
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
//获取对应的缓存对象
//get()方法会实现将访问的元素更新到队列头部的功能
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
其中LinkedHashMap的get()方法如下:
public V get(Object key) {
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
//实现排序的关键方法
e.recordAccess(this);
return e.value;
}
调用recordAccess()方法如下:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//判断是否是访问排序
if (lm.accessOrder) {
lm.modCount++;
//删除此元素
remove();
//将此元素移动到队列的头部
addBefore(lm.header);
}
}
由此可见LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队尾元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队头。
LruCache的缓存策略的更多相关文章
- 【安卓中的缓存策略系列】安卓缓存之内存缓存LruCache
缓存策略在移动端设备上是非常重要的,尤其是在图片加载这个场景下,因为图片相对而言比较大会花费用户较多的流量,因此可用缓存方式来解决,即当程序第一次从网络上获取图片的时候,就将其缓存到存储设备上,这样在 ...
- Android下的缓存策略
Android下的缓存策略 内存缓存 常用的内存缓存是软引用和弱引用,大部分的使用方式是Android提供的LRUCache缓存策略,本质是个LinkedHashMap(会根据使用次数进行排序) 磁盘 ...
- 安卓开发笔记——关于图片的三级缓存策略(内存LruCache+磁盘DiskLruCache+网络Volley)
在开发安卓应用中避免不了要使用到网络图片,获取网络图片很简单,但是需要付出一定的代价——流量.对于少数的图片而言问题不大,但如果手机应用中包含大量的图片,这势必会耗费用户的一定流量,如果我们不加以处理 ...
- Android Volley框架的使用(四)图片的三级缓存策略(内存LruCache+磁盘DiskLruCache+网络Volley)
在开发安卓应用中避免不了要使用到网络图片,获取网络图片很简单,但是需要付出一定的代价——流量.对于少数的图片而言问题不大,但如果手机应用中包含大量的图片,这势必会耗费用户的一定流量,如果我们不加以处理 ...
- 网络图片的获取以及二级缓存策略(Volley框架+内存LruCache+磁盘DiskLruCache)
在开发安卓应用中避免不了要使用到网络图片,获取网络图片很简单,但是需要付出一定的代价——流量.对于少数的图片而言问题不大,但如果手机应用中包含大量的图片,这势必会耗费用户的一定流量,如果我们不加以处理 ...
- Android 开源框架Universal-Image-Loader完全解析(二)--- 图片缓存策略详解
转载请注明本文出自xiaanming的博客(http://blog.csdn.net/xiaanming/article/details/26810303),请尊重他人的辛勤劳动成果,谢谢! 本篇文章 ...
- Android 开源框架Universal-Image-Loader全然解析(二)--- 图片缓存策略具体解释
转载请注明本文出自xiaanming的博客(http://blog.csdn.net/xiaanming/article/details/26810303),请尊重他人的辛勤劳动成果,谢谢! 本篇文章 ...
- 【安卓中的缓存策略系列】安卓缓存策略之综合应用ImageLoader实现照片墙的效果
在前面的[安卓缓存策略系列]安卓缓存之内存缓存LruCache和[安卓缓存策略系列]安卓缓存策略之磁盘缓存DiskLruCache这两篇博客中已经将安卓中的缓存策略的理论知识进行过详细讲解,还没看过这 ...
- 【安卓中的缓存策略系列】安卓缓存策略之磁盘缓存DiskLruCache
安卓中的缓存包括两种情况即内存缓存与磁盘缓存,其中内存缓存主要是使用LruCache这个类,其中内存缓存我在[安卓中的缓存策略系列]安卓缓存策略之内存缓存LruCache中已经进行过详细讲解,如看官还 ...
随机推荐
- 浅谈element-ui中的BEM范式实践
日常的工作中,我们无时无刻不在和样式打交道.没有样式的页面就如同一部电影,被人随意地在不同地方做了截取. BEM规范应该是对于我们现在前端组件开发中我觉得是最合适的一套范式了.所以,我在自己的日常工作 ...
- 一个非常标准的连接Mysql数据库的示例代码
一.About Mysql 1.Mysql 优点 体积小.速度快.开放源码.免费 一般中小型网站的开发都选择 MySQL ,最流行的关系型数据库 LAMP / LNMP Linux作为操作系统 Apa ...
- C程序设计-----第1次作业
一. PTA作业. 在完成PTA作业的时候我没有认真读题.每次都是提交完整代码 6-1(1) #include <stdio.h> //P++等价于(p)++还是等价于*(p++)? ...
- JAVA接口基础知识总结
1:是用关键字interface定义的. 2:接口中包含的成员,最常见的有全局常量.抽象方法. 注意:接口中的成员都有固定的修饰符. 成员变量:public static final 成员方法 ...
- iOS开发所有KeyboardType与图片对应展示
1.UIKeyboardTypeAlphabet 2.UIKeyboardTypeASCIICapable 3.UIKeyboardTypeDecimalPad 4.UIKeyboardTypeDe ...
- labview与单片机串口通信
labview与单片机串口通信 VISA是虚拟仪器软件体系结构的缩写(即Virtual Instruments Software Architecture),实质上是一个I/O口软件库及其规范的总 ...
- php_类的定义
此文章为原创见解,例子各方面也是东拼西凑.如果有错请留言.谢谢 在面向对象的思维中提出了两个概念,类和对象. 类是对某一类实物的抽象描述,而对象用于表示现实中该类事物的个体, 例子:老虎是父类,东北虎 ...
- JAVA_SE基础——15.循环嵌套
嵌套循环是指在一个循环语句的循环体中再定义一个循环语句结构,while,do-while,for循环语句都可以进行嵌套,并且可以互相嵌套,下面来看下for循环中嵌套for循环的例子. 如下: publ ...
- Python内置函数(61)——eval
英文文档: eval(expression, globals=None, locals=None) The arguments are a string and optional globals an ...
- Asp.net容器化
注意:本文只用于探讨asp.net容器化,不建议生产环境下使用(docker 镜像太大!!!!) 安装docker 准备一个台windwos server 2016 ,在PowerShell 里执行以 ...