Solr 13 - 在URL地址栏中操作Solr集群 - 包括CRUD、别名、切割分片、更新配置
说明: 本篇所有
curl操作是在终端中进行的, 当然可以省去curl和url中的引号, 直接在浏览器的地址栏中发起HTTP请求, 效果更明显.
1 创建Collection、Core
1.1 创建collection
直接在浏览器的URL地址栏进行操作, 命令如下:
http://localhost:8080/solr/admin/collections?action=CREATE&name=mycollection&numShards=3&replicationFactor=4
或者: 直接在终端的命令行中操作(注意curl之后的内容需要加单引号或双引号):
curl 'http://localhost:8080/solr/admin/collections?action=CREATE&name=mycollection&numShards=3&replicationFactor=4'
上述方式创建的Collection中, Shard和Replica由Solr自动分配, 不能手动选择具体的数据存放路径、实例存放路径.
1.2 创建core
手动指定实例存放路径和数据存放路径:
curl 'http://localhost:8080/solr/admin/cores?action=CREATE&name=my_collection-shard1-replica1&instanceDir=/usr/solr/my_collection-shard1-replica1&dataDir=/data_solr/my_collection-shard1-replica1&collection=my_collection&shard=shard1'
curl 'http://localhost:8080/solr/admin/cores?action=CREATE&name=my_collection-shard1-replica2&instanceDir=/usr/solr/my_collection-shard1-replica2&dataDir=/data_solr/my_collection-shard1-replica2&collection=my_collection&shard=shard1'
这样可以创建出一个collection, 并自己指定该collection的shard和replica的所有配置项.
1.3 创建操作中的参数
(1) action: 要操作动作的名称;
(2) name: 要创建的集合名称;
(3) numShards: 集合分片的个数;
(4) replicationFactor(副本因子): 每个分片配备的副本数, 包括Leader和Replica;
(5) collection.configName: 创建新集合时所使用的配置文件的名称, 如果不指定, 就会默认使用name作为配置文件的名称.
(6) createNodeSet: 如果不提供该参数, 创建操作会将Replica分布到所有活跃的Solr节点上. 这个参数用于创建分片和副本的节点集合, 格式为: createNodeSet=node1:8081_solr,node2:8082_solr,node3:8083_solr
(7) maxShardsPerNode: 指定每个Node可以创建的Shard数, 默认为1.
a) 创建操作将生成
numShards * replicationFactor个副本, 并尽可能均匀地分布在所有活跃的Node上;
b) 为了保证高可用, 同一个Solr节点上不能存在同一Shard的多个副本;
c) 如果maxShardsPerNode * nodeNum < numShards * replicationFactor, CREATE操作将失败, 报错信息如下:org.apache.solr.common.SolrException:org.apache.solr.common.SolrException: Cannot create collection mycollection.
Value of maxShardsPerNode is 3, and the number of live nodes is 3. This allows a maximum of 9 to be created.
Value of numShards is 3 and value of replicationFactor is 4. This requires 12 shards to be created (higher than the allowed number)
2 删除Collection、Core、Shard
(1) 删除collection:
collections的API不支持UNLOAD操作;
删除操作将直接删除指定的collection, 包括其目录文件.
curl 'http://localhost:8080/solr/admin/collections?action=DELETE&name=collection1&indent=true'
name: 将被删除的集合的名称;
indent=true: 格式化(有缩进)显示响应结果.
(2) 卸载core:
cores的API不支持DELETE操作;
卸载操作将卸载指定的collection_shard_replica, 并不会删除目录文件.
curl 'http://localhost:8080/solr/admin/cores?action=UNLOAD&core=collection1_shard1_replica2&deleteIndex=true&indent=true'
(3) 删除shard:
这个操作一般配合切分分片(SPLITSHARD)来使用: 切分分片后, 删除被切分的分片.
curl 'http://localhost:8080/solr/admin/collections?action=DELETESHARD&shard=shard1&collection=collection1'
删除操作并不会删除对应Shard的目录文件, 但是会删除其存放index文件的目录, 并将记录core信息的文件标记为已卸载:
core.properties.unloaded, 内容如下:

3 加载Collection、Core
(1) 重新加载collection:
collections的API不支持LOAD操作;
被卸载了的core并不会被RELOAD进来.
curl 'http://localhost:8080/solr/admin/collections?action=RELOAD&name=collection1&indent=true'
name: 将被重新加载的集合的名称.
(2) 加载core:
cores的API不支持RELOAD操作;
可以LOAD某一个collection, 但被卸载了的core不能被LOAD进来;
可以LOAD某一个指定的core, 但被卸载了的core也不能被LOAD进来.
curl 'http://localhost:8080/solr/admin/cores?action=LOAD&core=collection1_shard1_replica2&indent=true'
4 查看集群状态
(1) 查看集群的Cloud data:
此操作亦可通过浏览器的URL查看, 格式化响应结果, 更加清晰:
curl 'http://localhost:8080/solr/zookeeper?wt=json&detail=true&path=/clusterstate.json'
(2) 查看集群中的所有core:
curl 'http://localhost:8080/solr/admin/collections?action=LIST'
(3) 查看集群的健康状况:
curl 'http://localhost:8080/solr/admin/collections?action=CLUSTERSTATUS'
可以查看到Shard的路由、活跃状态、副本状态等信息.
5 添加副本(ADDREPLICA)
如果服务器配置优良, 为了提高检索性能, 我们可以通过为分片添加副本.
如果要在指定的节点中创建副本, 则可以指定节点名称 —— 可以在http://localhost:8080/solr/#/~cloud?view=tree中的live_nodes下查看活跃的节点, 一般格式都是:
/live_nodes
172.16.10.11:8080_solr
172.16.10.12:8080_solr
172.16.10.13:8080_solr
(1) 使用方式:
http://localhost:8080/solr/admin/collections?action=ADDREPLICA&collection=collection1&shard=shard1&node=nodeName
①
collection: 集合的名称;
shard: 要添加副本的分片, 如果不指定, 就要指定_route_参数 —— 如果无法确定分片名, 就可以传递该_route_值, 系统会识别这个_route_所属的分片, 然后完成相关操作;
②node: 应该创建副本的节点的名称, 必须活跃, 必须是活跃节点, 可不指定, Solr会自动进行负载均衡;
③instanceDir: 将被创建的核心的instanceDir, 可不指定;
④dataDir: 应在其中创建核心的目录, 可不指定;
⑤type: 要创建的副本的类型, 有以下几种: (可不指定)nrt: NRT类型维护事务日志并在本地更新其索引, 这是默认的, 也是最常用的;
tlog: TLOG类型维护事务日志, 但只通过复制更新其索引;
pull: PULL类型不维护事务日志, 只通过复制更新其索引. 这种类型没有资格成为Leader.
(2) 使用示例:
http://localhost:8080/solr/admin/collections?action=ADDREPLICA&collection=test&shard=shard1&node=172.16.10.11:8080_solr
操作成功后的响应信息为:
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">1496</int>
</lst>
<lst name="success">
<lst>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">1407</int>
</lst>
<!-- 添加成功后的副本名称 -->
<str name="core">test_shard1_replica2</str>
</lst>
</lst>
</response>
6 切割分片(SPLITSHARD)
(1) 切割示例:
curl 'http://localhost:8080/solr/admin/collections?action=SPLITSHARD&collection=mycollection&shard=shard2&indent=true'
collection: 集合的名称;
shard: 将被切割的分片ID, 必须存在, 且当前Collection的shard个数必须大于1个(已验证).
(2) 该特性发布于Solr4.3, 测试结果如图:
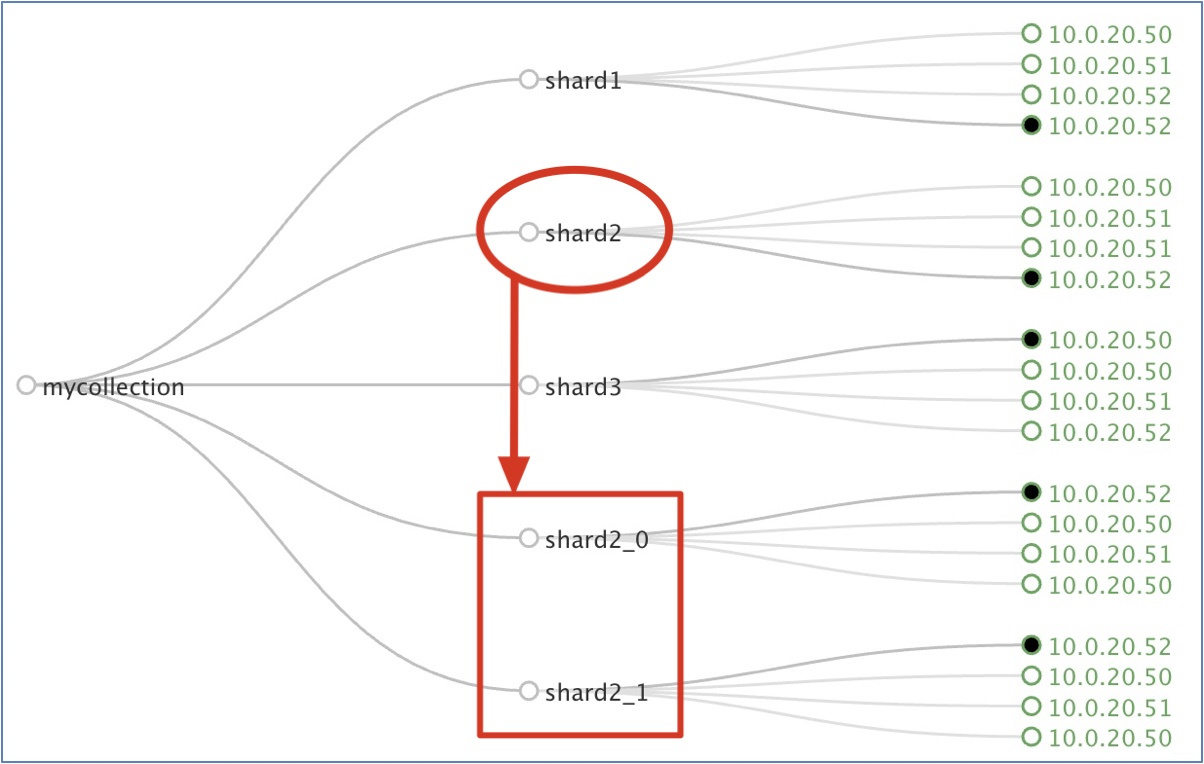
①
SPLITSHARD命令不能用于使用了自定义哈希的集群, 因为这样的集群没有一个明确的哈希范围 —— 它只用于具有plain或compositeid路由的集群;
② 该命令将指定的shard的切割成 两个新的具有相同数据的分片, 并根据新分片的路由范围切割父分片 (被切割的shard) 中的文档;
③ 新的分片将被命名为shardx_0和shardx_1—— 表明是从shardx上分裂得到的新Shard;
④ 一旦新分片被成功创建, 它们就会被立即激活, 同时父分片也将被暂停 —— 新的读写请求就不会被发送到父分片中了, 而是直接路由到新的切割生成的新分片中;
④ 该特征能够保证无缝切割和无故障时间: 父分片数据不会被删除, 在切割操作完成之前, 父分片将继续提供读写请求, 直到切割完成.
(3) 使用注意事项:
① 切割分片后, 再使用
DELETESHARD命令删除被切割的原始Shard, 就能保证数据不冗余, 当然也可以通过UNLOAD命令卸载被切割的Shard;
② 原Shard目录下的配置文件会变成core.properties.unloaded, 也就是加了个卸载标示;data目录下保存索引数据的index目录被删除 —— 从侧面印证了数据完成了切分和迁移;
③ SolrCloud不支持对索引到其他Shard上的数据的动态迁移, 可以通过切割分片实现SolrCloud的扩容, 这只会对 切割操作之后、路由的哈希范围仍然属于原分片的数据 进行扩容.
7 操作集合别名(操作成功, 但未查出区别)
Solr允许用户创建独立的指向一个或多个真实集合的虚拟集合, 可以在运行时修改别名.
(1) 创建或修改别名:
curl 'http://localhost:8080/solr/admin/collections?action=CREATEALIAS&name=alias&collections=collection1&indent=true'
用来修改的别名应该只映射一个独立的集合, 读取的别名能映射一个或多个集合.
(2) 移除存在的别名:
curl 'http://localhost:8080/solr/admin/collections?action=DELETEALIAS&name=alias&indent=true'
8 更新集群的配置
集群会发生变化的就是collection的配置, 因此当配置文件发生变化后就应该使用命令更新ZooKeeper中的配置信息. 对此, Solr提供了很好的运维工具:
8.1 将配置文件上传到ZooKeeper中
需要的jar包:
$SOLR_HOME/example/lib/ext/*以及 Solr项目的WEB-INF/lib/*, 这里已经将ext下的jar包拷贝到了WEB-INF/lib目录下, 便捷很多.
cd /data/solr-cloud/tomcat/display/solr/WEB-INF/lib
下述一长串是一条命令, 为了便于查看, 使用了反斜杠(\)来断句, 如果使用中出现问题, 可将反斜杠(\)删除, 并删除所有的换行, 然后回车执行.
# 注意本地路径, 以及../classes/log4j.properties文件的路径
java -classpath .:* \
-Dlog4j.configuration=file:../classes/log4j.properties \
org.apache.solr.cloud.ZkCLI -cmd upconfig \
-zkhost 10.0.20.50:2181,10.0.20.51:2181,10.0.20.52:2181 \
-confdir /data/solr-cloud/tomcat/solrhome/collection1/conf \
-confname myconf2
建议: 将配置文件单独存放, 比如: 我这里将整个example/solr/collection1/conf存放至/data/solr-cloud/tomcat下, 之后执行配置文件的更新:
java -classpath .:* \
-Dlog4j.configuration=file:../classes/log4j.properties \
org.apache.solr.cloud.ZkCLI -cmd upconfig \
-zkhost 10.0.20.50:2181,10.0.20.51:2181,10.0.20.52:2181 \
-confdir /data/solr-cloud/tomcat/conf \
-confname myconf
8.2 将ZooKeeper中的配置文件与Collection相关联
cd /data/solr-cloud/tomcat/display/solr/WEB-INF/lib
java -classpath .:* \
-Dlog4j.configuration=file:../classes/log4j.properties \
org.apache.solr.cloud.ZkCLI -cmd linkconfig \
-collection mycollection -confname myconf \
-zkhost 10.0.20.50:2181,10.0.20.51:2181,10.0.20.52:2181
注意: 配置文件若被删除, 将会导致ZooKeeper中的配置文件被同步删除, 从而在建立collection时将出现问题.
可关闭Tomcat服务与ZooKeeper服务, 删除ZooKeeper目录下的配置文件的版本信息, 然后再次启动ZooKeeper更新配置文件, 最后启动Tomcat服务继续测试.
参考资料
版权声明
出处: 博客园 马瘦风的博客(https://www.cnblogs.com/shoufeng)
感谢阅读, 如果文章有帮助或启发到你, 点个[好文要顶
Solr 13 - 在URL地址栏中操作Solr集群 - 包括CRUD、别名、切割分片、更新配置的更多相关文章
- 在URL地址栏中显示ico
<!-- 在URL地址栏中显示ico --> <link Rel="SHORTCUT ICON" href="imag ...
- 项目中使用Quartz集群分享--转载
项目中使用Quartz集群分享--转载 在公司分享了Quartz,发布出来,希望大家讨论补充. CRM使用Quartz集群分享 一:CRM对定时任务的依赖与问题 二:什么是quartz,如何使用, ...
- (4) Spring中定时任务Quartz集群配置学习
原 来配置的Quartz是通过spring配置文件生效的,发现在非集群式的服务器上运行良好,但是将工程部署到水平集群服务器上去后改定时功能不能正常运 行,没有任何错误日志,于是从jar包.JDK版本. ...
- [转贴]CentOS7.5 Kubernetes V1.13(最新版)二进制部署集群
CentOS7.5 Kubernetes V1.13(最新版)二进制部署集群 http://blog.51cto.com/10880347/2326146 一.概述 kubernetes 1.13 ...
- 操作Hadoop集群
操作Hadoop集群 所有必要的配置完成后,将文件分发到所有机器上的HADOOP_CONF_DIR目录.这应该是所有机器上相同的目录. 一般来说,建议HDFS和YARN作为单独的用户运行.在大多数安装 ...
- python 操作redis集群
一.连接redis集群 python的redis库是不支持集群操作的,推荐库:redis-py-cluster,一直在维护.还有一个rediscluster库,看GitHub上已经很久没更新了. 安装 ...
- Java操作Hadoop集群
mavenhdfsMapReduce 1. 配置maven环境 2. 创建maven项目 2.1 pom.xml 依赖 2.2 单元测试 3. hdfs文件操作 3.1 文件上传和下载 3.2 RPC ...
- Redis 中常见的集群部署方案
Redis 的高可用集群 前言 几种常用的集群方案 主从集群模式 全量同步 增量同步 哨兵机制 什么是哨兵机制 如何保证选主的准确性 如何选主 选举主节点的规则 哨兵进行主节点切换 切片集群 Redi ...
- java操作redis集群配置[可配置密码]和工具类(比较好用)
转: java操作redis集群配置[可配置密码]和工具类 java操作redis集群配置[可配置密码]和工具类 <dependency> <groupId>red ...
随机推荐
- 【bzoj1758】[Wc2010]重建计划
Description Input 第一行包含一个正整数N,表示X国的城市个数. 第二行包含两个正整数L和U,表示政策要求的第一期重建方案中修建道路数的上下限 接下来的N-1行描述重建小组的原有方案, ...
- BZOJ_4627_[BeiJing2016]回转寿司_离散化+树状数组
BZOJ_4627_[BeiJing2016]回转寿司_离散化+树状数组 Description 酷爱日料的小Z经常光顾学校东门外的回转寿司店.在这里,一盘盘寿司通过传送带依次呈现在小Z眼前.不同的寿 ...
- [NOIP2016]愤怒的小鸟 D2 T3
Description Kiana最近沉迷于一款神奇的游戏无法自拔. 简单来说,这款游戏是在一个平面上进行的. 有一架弹弓位于(0,0)处,每次Kiana可以用它向第一象限发射一只红色的小鸟,小鸟们的 ...
- 【已解决】【Mac】 运行adb提示command not found,需要配置adb环境
问题:运行adb提示command not found 解决措施: 1.下载安装:android-sdk-macosx 下载路径:http://down.tech.sina.com.cn/page/ ...
- numpy C语言源代码调试(三)
鉴于ddd过于简陋,希望找一个新一些的调试工具,看到有很多人推荐gdbgui,这是一个非常新的调试工具,前端使用浏览器,现在采用这一架构的软件越来越多,可以完全不必依赖庞大的gui类库,安装使用比较方 ...
- 《前端之路》之 webpack 4.0+ 的应用构建
目录 一.版本 二.webpack 的主体概念 2-1.入口 2-1-1.单页面入口 2-1-2.多页面应用的入口 2-2.输出 2-3.loader 2-4.plugins 三.如何使用 3-1 关 ...
- com.mysql.jdbc.Driver 和 com.mysql.cj.jdbc.Driver的区别
com.mysql.jdbc.Driver 是 mysql-connector-java 5中的,com.mysql.cj.jdbc.Driver 是 mysql-connector-java 6中的 ...
- 由浅入深讲解责任链模式,理解Tomcat的Filter过滤器
本文将从简单的场景引入, 逐步优化, 最后给出具体的责任链设计模式实现. 场景引入 首先我们考虑这样一个场景: 论坛上用户要发帖子, 但是用户的想法是丰富多变的, 他们可能正常地发帖, 可能会在网页中 ...
- 11个不常被提及的JavaScript小技巧
这次我们主要来分享11个在日常教程中不常被提及的JavaScript小技巧,他们往往在我们的日常工作中经常出现,但是我们又很容易忽略. 1.过滤唯一值 Set类型是在 ES6中新增的,它类似于数组,但 ...
- JavaScript函数定义 ,参数调用
一.JavaScript函数函数: 函数就是一种封装,由事件驱动的或者当它被调用时执行的可重复使用的代码块.定义函数:function 函数名(){函数体;}数不会自动执行,需要被调用才可以执行函数名 ...