elasticSearch(六)--全文搜索
数据案例

1、匹配查询
a、单词查询

执行match步骤:
·检查field类型:title字段为(analyzed)字符串,所以搜索时,title需要被分析。
·分析查询字符串:QUICK! 经过标准分析器分后为quick
·找到匹配文档:再倒排索引中找到quick,并返回包含该词的文档(1,2,3)
·为每个文档打分:查询综合考虑词频( 每篇文档 title 字段包含 quick 的次数) 、 逆文档频率( 在全部文档中 title 字段包含 quick 的次数) 、
包含 quick 的字段长度( 长度越短越相关) 来计算每篇文档的相关性得分 _score
b、多词查询


<1> 文档4的相关度最高, 因为包含两个"brown"和一个"dog"。
<2> 文档2和3都包含一个"brown"和一个"dog", 且'title'字段长度相同, 所以相关度相等。
<3> 文档1只包含一个"brown", 不包含"dog", 所以相关度最低。
因为 match 查询需要查询两个关键词: "brown" 和 "dog" , 在内部会执行两个 term 查询并
综合二者的结果得到最终的结果。 match 的实现方式是将两个 term 查询放入一个 bool 查询, bool 查询在之前的章节已经介绍过。
重要的一点是, 'title' 字段包含至少一个查询关键字的文档都被认为是符合查询条件的。匹配的单词数越多, 文档的相关度越高。
提高精度
默认匹配结果为或的关系,如brown dog 搜索结果为包含brown或者dog的文档
match查询接受operator参数提高精度。默认operator=or
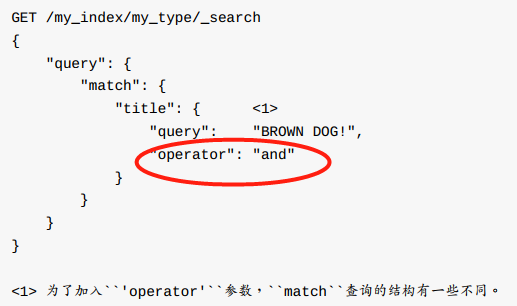
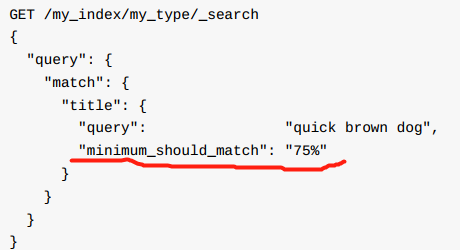
match 查询有 'minimum_should_match' 参数, 参数值表示被视为相关的文档必须匹配的关键词个数。 参数值可以设为整数, 也可以设置为百分数。
因为不能提前确定用户输入的查询关键词个数, 使用百分数也很合理
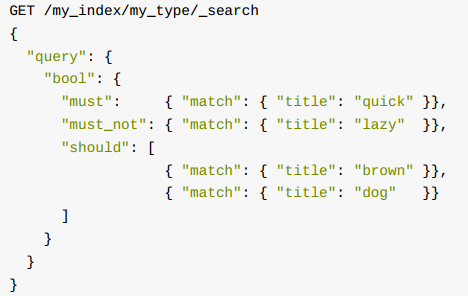
2、组合查询
计算得分
把所有符合 must 和 should 的子句得分加起来, 然后除以 must 和 should 子句的总数为每个文档计算相关性得分。
must_not 子句并不影响得分; 他们存在的意义是排除已经被包含的文档。
精度控制
所有的 must 子句必须匹配, 并且所有的 must_not 子句必须不匹配, 但是多少 should 子句应该匹配呢? 默认的, 不需要匹配任何 should 子句,
一种情况例外: 如果没有 must 子句,就必须至少匹配一个 should 子句。像我们控制 match 查询的精度一样,
我们也可以通过 minimum_should_match 参数控制多少 should 子句需要被匹配, 这个参数可以是正整数, 也可以是百分比。

结果集仅包含 title 字段中有 "brown" 和 "fox" , "brown" 和 "dog" , 或 "fox" 和 "dog" 的文档。 如果一个文档包含上述三个条件, 那么它的相关性就会比其他仅包含三者中的两个条件的文档要高
elasticSearch(六)--全文搜索的更多相关文章
- Elasticsearch构建全文搜索系统
目录 前言 一.安装 1.安装elasticsearch 2.启动集群cluster 3.安装管理界面elasticsearch-head 4.安装分词插件elasticsearch-analysis ...
- Flask 教程 第十六章:全文搜索
本文翻译自The Flask Mega-Tutorial Part XVI: Full-Text Search 这是Flask Mega-Tutorial系列的第十六部分,我将在其中为Microblo ...
- 全文搜索之 Elasticsearch
概述 Elasticsearch (ES)是一个基于 Lucene 的开源搜索引擎,它不但稳定.可靠.快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的. 特性 安装方便:没有其他依赖,下载 ...
- Elasticsearch全文搜索——adout
现在尝试下稍微高级点儿的全文搜索——一项传统数据库确实很难搞定的任务. 搜索下所有喜欢攀岩(rock climbing)的雇员: curl -XGET 'localhost:9200/megacorp ...
- 在 Laravel 项目中使用 Elasticsearch 做引擎,scout 全文搜索(小白出品, 绝对白话)
项目中需要搜索, 所以从零开始学习大家都在用的搜索神器 elasiticsearch. 刚开始 google 的时候, 搜到好多经验贴和视频(中文的, 英文的), 但是由于是第一次接触, 一点概念都没 ...
- 使用ElasticSearch服务从MySQL同步数据实现搜索即时提示与全文搜索功能
最近用了几天时间为公司项目集成了全文搜索引擎,项目初步目标是用于搜索框的即时提示.数据需要从MySQL中同步过来,因为数据不小,因此需要考虑初次同步后进行持续的增量同步.这里用到的开源服务就是Elas ...
- ASP.NET Web API + Elasticsearch 6.x 快速做个全文搜索
最近想做个全文搜索,设想用 ASP.NET Web API + Elasticsearch 6.x 来实现. 网上搜了下 Elasticsearch 的资料,大部分是讲 linux 平台下如何用 ja ...
- ElasticSearch 2 (14) - 深入搜索系列之全文搜索
ElasticSearch 2 (14) - 深入搜索系列之全文搜索 摘要 在看过结构化搜索之后,我们看看怎样在全文字段中查找相关度最高的文档. 全文搜索两个最重要的方面是: 相关(relevance ...
- ElasticSearch 结构化搜索全文
1.介绍 上篇介绍了搜索结构化数据的简单应用示例,现在来探寻 全文搜索(full-text search) :怎样在全文字段中搜索到最相关的文档. 全文搜索两个最重要的方面是: 相关性(Relevan ...
- 可以执行全文搜索的原因 Elasticsearch full-text search Kibana RESTful API with JSON over HTTP elasticsearch_action es 模糊查询
https://www.elastic.co/guide/en/elasticsearch/guide/current/getting-started.html Elasticsearch is a ...
随机推荐
- 爬小说_BeautifulSoup解析_easy
title: 爬小说_BeautifulSoup解析_easy author: 杨晓东 permalink: 爬小说_BeautifulSoup解析_easy date: 2021-10-02 11: ...
- MySQL的Temporary Files存放路径
在Linux环境中MySQL用TMPDIR环境变量来设置temporary files的路径,如果没有设置,MySQL会用系统默认 /tmp, /var/tmp或/usr/tmp. 1.当排序时(OR ...
- Python 常用小例子
作者原文 https://mp.weixin.qq.com/s/eFYDW20YPynjsW_jcp-QWw 内置函数(63个) 1 abs() 绝对值或复数的模 In [1]: abs(-6) Ou ...
- gitlab中CI/CD过程中的坑
先上观点,azure的pipeline比gitlab ce版好用,gitlab收费版没有用过. 在.gitlab-ci.yml中的特殊字符处理: 解决方法: cmd="[$var1] &am ...
- java double/float转BigDecimal,精度问题
double/float 转BigDecimal,会有精度问题.所以需要转String类型,然后再转BigDecimal
- 发送邮件找回密码采用outlook的 pop和smtp方式、qq邮箱smtp
一.outlook的pop方式,并指定发送人邮箱地址: 需要引入dll:Microsoft.Office.Interop.Outlook Outlook.Application olApp = new ...
- Oracle查看用户占用的表空间大小
SELECT owner, tablespace_name, ROUND (SUM (BYTES) / 1024 / 1024, 2) "USED(M)" FROM dba_seg ...
- golang 数组(array)
1. 概念 golang中的数组是具有固定长度及相同数据类型的序列集合 2. 初始化数组 var 数组名 [数组大小]数据类型 package main import "fmt" ...
- 浅谈storm
storm分布式,可容错的实时计算框架,低延迟能做到毫秒级的响应,storm进程是常驻内存,Hadoop是不断启停的,storm中的数据不经过磁盘,都在内存中,处理完成后就没有了,但是可以写到数据库中 ...
- PHP_单例模式、实例代码
在PHP中实例化一个对象,就会新开辟一个新内存空间,当一些业务要实例化多个对象时,会占用大量内存.这个问题可以用单例模式解决. 我们实例化对象可以直接new出来,也可以通过类中的构造函数 __con ...