GIL全局解释器锁、协程运用、IO模型
GIL全局解释器锁
一.什么是GIL
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程环境中,Python 虚拟机按以下方式执行:
a、设置 GIL;
b、切换到一个线程去运行;
c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0));
d、把线程设置为睡眠状态;
e、解锁 GIL;
d、再次重复以上所有步骤。
在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)编写扩展的程序员可以主动解锁GIL。
在调用外部代码(如C/C++扩展函数)的时候,GIL 将会被锁定,直到这个函数结束为止(由于在这期间没有Python 的字节码被运行,所以不会做线程切换)。
拿到 CPU 权限 -> 拿到 GIL 解释器锁 -> 执行代码
二.为什么要有GIL
在Cpython中GIL全局解释器锁其实也是一把互斥锁,主要用于阻止同一个进程下的多个线程同时被运行(python的多线程无法使用多核优势)
GIL肯定存在于CPython解释器中 主要原因就在于Cpython解释器的内存管理不是线程安全的
内存管理>>>垃圾回收机制
引用计数
标记清除
分代回收
三.验证GIL的存在
from threading import Thread
import time
m = 100
def test():
global m
tmp = m
tmp -= 1
m = tmp
for i in range(100):
t = Thread(target=test)
t.start()
time.sleep(3)
print(m) # 0
"""
同一个进程下的多个线程有GIL的存在不会出现并行的效果 并行的话结果为99 有GIL就是0
但是如果线程内有IO操作还是会造成数据的错乱 这个时候需要我们额外的添加互斥锁
"""
四.总结
1.在Cpython解释器中才有GIL的存在(GIL与解释器有关)
2.GIL本质上其实也是一把互斥锁(并发变串行 牺牲效率保证安全)
3.GIL的存在是由于Cpython解释器中的内存管理不是线程安全的
垃圾回收机制
4.在python中同一个进程下的多个线程无法实现并行(可以并发)
python多线程是否没用
一.多进程性能测试
计算密集型:多进程效率高
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(4):
p=Process(target=work) #耗时5s多
p=Thread(target=work) #耗时18s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
二.多线程性能测试
I/O密集型:多线程效率高
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
print('===>')
if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(400):
# p=Process(target=work) #耗时12s多,大部分时间耗费在创建进程上
p=Thread(target=work) #耗时2s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
三.总结
应用:
多线程用于IO密集型,如:socket,爬虫,web 多进程用于计算密集型,如:金融分析
GIL 解释器锁会在两种情况下释放
1.主动释放
:
遇到 IO 操作或者分配的 CPU 时间片到时间了。
注意,GIL存在的意义在于维护线程安全,x=10涉及到IO操作,如果也被当成普通的IO操作,主动交出GIL,那么一定会出现数据不安全问题,所以x=10一定是被区分对待了。
至于x=10如何实现的被区分对待,这其实很好理解,任何的io操作都是向操作系统发送系统调用,即调用操作系统的某一接口实现的,比如变量赋值操作肯定是调用了一种接口,文件读写操作肯定也是调用了一种接口,网络io也是调用了某一种接口,这就给区分对待提供了实现的依据,即变量赋值操作并不属于主动释放的范畴,这样GIL在线程安全方面才会有所作为
2.被动释放
python3.2之后定义了一个全局变量
/ Python/ceval.c /*
…
*static volatile int gil_drop_request = 0;
注意当只有一个线程时,该线程会一直运行,不会释放GIL,当有多个线程时
例如thead1,thread2
如果thread1一直没有主动释放掉GIL,那肯定不会让他一直运行下去啊
实际上在thread1运行的过程时,thread2就会执行一个cv_wait(gil,TIMEOUT)的函数
(默认TIMEOUT值为5milliseconds,但是可以修改),一旦到了时间,就会将全局变量
gil_drop_request = 1;,线程thread1就会被强制释放GIL,然后线程thread2开始运行并
返回一个ack给线程thread1,线程thread1开始调用cv_wait(gil,TIMEOUT
死锁现象
不要过多的用锁
from threading import Thread, Lock
import time
A = Lock()
B = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A.acquire()
print('%s 抢到了A锁' % self.name) # current_thread().name 获取线程名称
B.acquire()
print('%s 抢到了B锁' % self.name)
time.sleep(1)
B.release()
print('%s 释放了B锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
def func2(self):
B.acquire()
print('%s 抢到了B锁' % self.name)
A.acquire()
print('%s 抢到了A锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
B.release()
print('%s 释放了B锁' % self.name)
for i in range(10):
obj = MyThread()
obj.start()
"""就算知道锁的特性及使用方式 也不要轻易的使用 因为容易产生死锁现象"""
进程池与线程池
池:为了保证计算机硬件安全的情况下提升程序的运行效率
硬件的发展更不上软件的更新速度
进程池:
提前开设好一堆进程,只需要朝池子中提交任务,任务会自动分配给空闲的进程处理,并且池子中的进程创建好了之后就不会更替
线程池:
提前开设好一堆线程,只需要朝池子中提交任务,任务会自动分配给空闲的线程处理,并且池子中的线程创建好了之后就不会更替
进程池与线程池基本使用
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
import os
# 创建进程池与线程池
# pool = ThreadPoolExecutor(5) # 可以自定义线程数 也可以采用默认策略
pool = ProcessPoolExecutor(5) # 可以自定义线程数 也可以采用默认策略
# 定义一个任务
def task(n):
print(n, os.getpid())
time.sleep(2)
return '>>>:%s' % n ** 2
# 定义一个回调函数:异步提交完之后有结果自动调用该函数
def call_back(a):
print('异步回调函数:%s' % a.result()) # 对象点result才是上一个函数的返回结果
# 朝线程池中提交任务
# obj_list = []
for i in range(20):
pool.submit(task, i).add_done_callback(call_back) # 异步提交
# obj_list.append(res)
"""
同步:提交完任务之后原地等待任务的返回结果 期间不做任何事
异步:提交完任务之后不愿地等待任务的返回结果 结果由异步回调机制自动反馈
"""
# 等待线程池中所有的任务执行完毕之后 再获取各自任务的结果
# pool.shutdown()
# for i in obj_list:
# print(i.result()) # 获取任务的执行结果 同步
在windows电脑中如果是进程池的使用也需要在__main__下面
协程理论与实操
正常案例
进程
资源单位
线程
工作单位
协程
是程序员单方面意淫出来的名词>>>:单线程下实现并发
# CPU被剥夺的条件
1.程序长时间占用
2.程序进入IO操作
# 并发
切换+保存状态
以往学习的是:多个任务(进程、线程)来回切换
# 欺骗CPU的行为
单线程下我们如果能够自己检测IO操作并且自己实现代码层面的切换
那么对于CPU而言我们这个程序就没有IO操作,CPU会尽可能的被占用
"""代码层面"""
第三方gevent模块:能够自主监测IO行为并切换
from gevent import monkey;monkey.patch_all() # 固定代码格式加上之后才能检测所有的IO行为
from gevent import spawn
import time
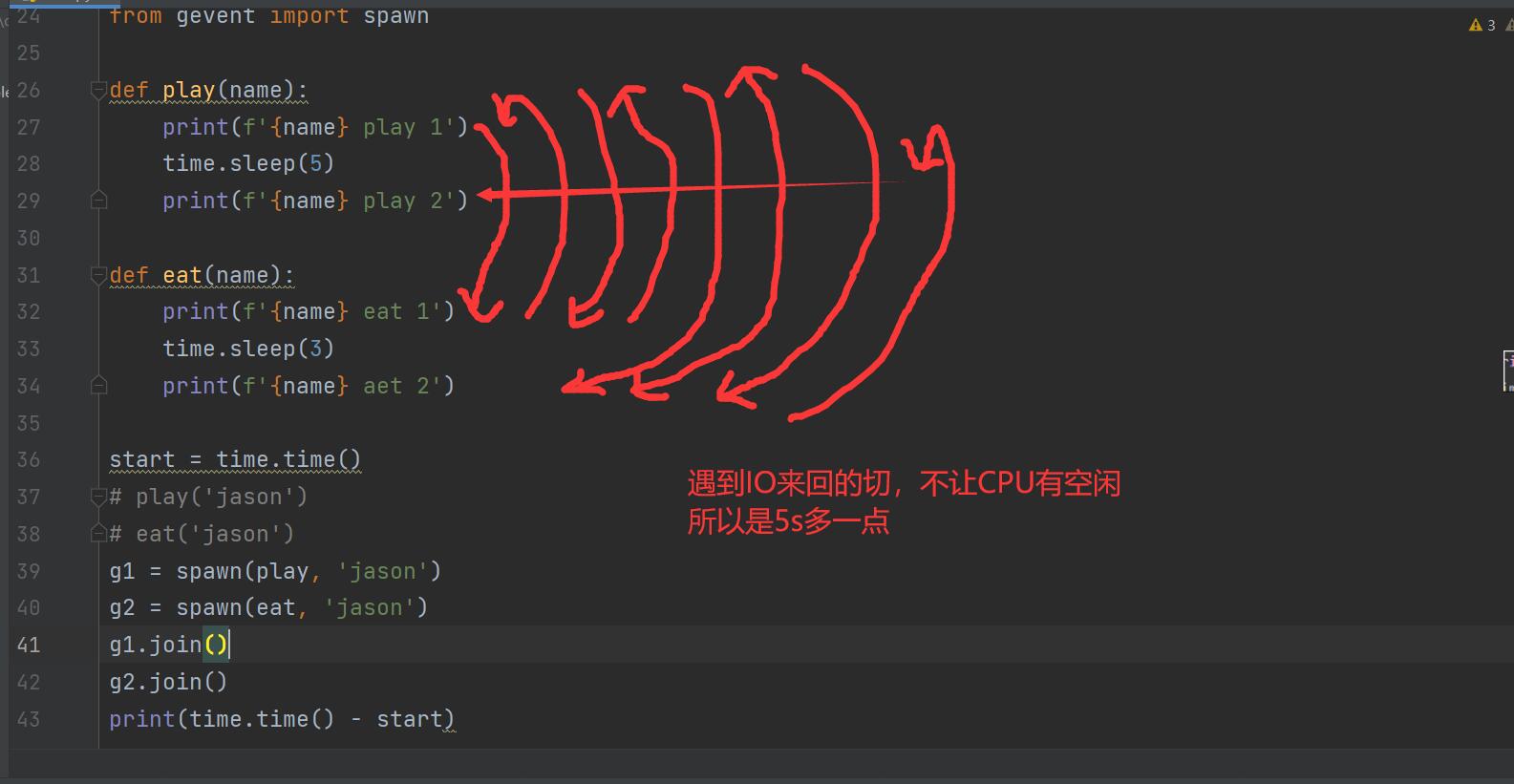
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
# play('jason') # 正常的同步调用
# eat('jason') # 正常的同步调用 正常情况下两个函数运行完的时间为8s
g1 = spawn(play, 'jason') # 异步提交
g2 = spawn(eat, 'jason') # 异步提交
g1.join()
g2.join() # 等待被监测的任务运行完毕
print('主', time.time() - start) # 单线程下实现并发,提升效率 加协程后是5s
协程实现TCP服务端并发的效果
# 并发效果:一个服务端可以同时服务多个客户端
# 服务端
from gevent import monkey;monkey.patch_all()
from gevent import spawn
import socket,random
def talk(sock):
while True:
try:
data = sock.recv(1024)
print(data.decode('utf8'))
sock.send(data + '你好.'.encode('utf8'))
except ConnectionResetError as e:
print(e)
break
def servers():
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
print(random.randint(1,10))
sock, addr = server.accept()
spawn(talk, sock)
servers()
# 客户端开设几百个线程发消息即可
"""
最牛逼的情况:多进程下开设多线程 多线程下开设协程
我们以后可能自己动手写的不多 一般都是使用别人封装好的模块或框架
"""
IO模型
IO模型简介
"""理论为主 代码实现大部分为伪代码(没有实际含义 仅为验证参考)"""
IO模型研究的主要是网络IO(linux系统)
# 基本关键字
同步(synchronous) 大部分情况下会采用缩写的形式 sync
异步(asynchronous) async
阻塞(blocking)
非阻塞(non-blocking)
# 研究的方向
Stevens在文章中一共比较了五种IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
* asynchronous IO 异步IO
由signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model
四种IO模型简介
# 1.阻塞IO
最为常见的一种IO模型 有两个等待的阶段(wait for data、copy data)
# 2.非阻塞IO
系统调用阶段变为了非阻塞(轮训) 有一个等待的阶段(copy data)
轮训的阶段是比较消耗资源的
# 3.多路复用IO
利用select或者epoll来监管多个程序 一旦某个程序需要的数据存在于内存中了 那么立刻通知该程序去取即可
# 4.异步IO
只需要发起一次系统调用 之后无需频繁发送 有结果并准备好之后会通过异步回调机制反馈给调用者
GIL全局解释器锁、协程运用、IO模型的更多相关文章
- python GIL全局解释器锁,多线程多进程效率比较,进程池,协程,TCP服务端实现协程
GIL全局解释器锁 ''' python解释器: - Cpython C语言 - Jpython java ... 1.GIL: 全局解释器锁 - 翻译: 在同一个进程下开启的多线程,同一时刻只能有一 ...
- GIL全局解释器锁及协程
GIL全局解释器锁 1.什么是GIL全局解释器锁 GIL本质是一把互斥锁,相当于执行权限,每个进程内都会存在一把GIL同一进程内的多线程,必须抢到GIL之后才能使用Cpython解释器来执行自己的代码 ...
- 进程、线程与GIL全局解释器锁详解
进程与线程的关系: . 线程是最小的调度单位 . 进程是最小的管理单元 . 一个进程必须至少一个线程 . 没有线程,进程也就不复存在 线程特点: 线程的并发是利用cpu上下文的切换(是并发,不是并行) ...
- 网络编程之多线程——GIL全局解释器锁
网络编程之多线程--GIL全局解释器锁 一.引子 定义: In CPython, the global interpreter lock, or GIL, is a mutex that preven ...
- 并发编程~~~多线程~~~守护线程, 互斥锁, 死锁现象与递归锁, 信号量 (Semaphore), GIL全局解释器锁
一 守护线程 from threading import Thread import time def foo(): print(123) time.sleep(1) print('end123') ...
- python 之 并发编程(守护线程与守护进程的区别、线程互斥锁、死锁现象与递归锁、信号量、GIL全局解释器锁)
9.94 守护线程与守护进程的区别 1.对主进程来说,运行完毕指的是主进程代码运行完毕2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕详细解释:1.主 ...
- python多线程和GIL全局解释器锁
1.线程 线程被称为轻量级进程,是最小执行单元,系统调度的单位.线程切换需要的资源一般,效率一般. 2.多线程 在单个程序中同时运行多个线程完成不同的工作,称为多线程 3.并 ...
- Python之路-python(paramiko,进程和线程的区别,GIL全局解释器锁,线程)
一.paramiko 二.进程.与线程区别 三.python GIL全局解释器锁 四.线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Event事件 queue队列 生 ...
- Python自动化 【第九篇】:Python基础-线程、进程及python GIL全局解释器锁
本节内容: 进程与线程区别 线程 a) 语法 b) join c) 线程锁之Lock\Rlock\信号量 d) 将线程变为守护进程 e) Event事件 f) queue队列 g) 生 ...
随机推荐
- oracle数据库导入导出语句
一.导出: 导出语句: expdp sanyayun/sanyayun@syerpdb directory=DMP dumpfile=fooderp.dmp content=all SCHEMAS=s ...
- VMware15安装 CentOS7 步骤
- [apue] linux 文件系统那些事儿
前言 说到 linux 的文件系统,好多人第一印象是 ext2/ext3/ext4 等具体的文件系统,本文不涉及这些,因为研究具体的文件系统难免会陷入细节,甚至拉大段的源码做分析,反而不能从宏观的角度 ...
- 爬虫简介与requests模块
爬虫简介与requests模块 一 爬虫简介 概述 网络爬虫是一种按照一定规则,通过网页的链接地址来寻找网页的,从网站某一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这 ...
- Redis运维实战之集群中的脑裂
1.对于分布式Redis主从集群来说,什么是脑裂? 所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求.而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客 ...
- 什么是root帐户?
root帐户就像一个系统管理员帐户,允许你完全控制系统.你可以在此处创建和维护用户帐户,为每个帐户分配不同的权限.每次安装Linux时都是默认帐户.
- 最长公共子序列(LCS动态规划)?
// dp[i][j] 计算去最大长度,记住口诀:相等左上角加一,不等取上或左最大值function LCS(str1, str2){ var rows = str1.split(&q ...
- SpringBoot项目集成swagger报NumberFormatException: For input string: ""
java.lang.NumberFormatException: For input string: "" at java.lang.NumberFormatException.f ...
- System.getenv和getProperty的区别
/** * System.getenv()是获取---环境变量(environment variables), * 系统层面的,好比我linux系统里的.bash_profile文件里面的变量 * 返 ...
- 详解AOP——用配置文件的方式实现AOP
AOP概念 1.AOP:面向切面(方面)编程,扩展功能不修改源代码实现 AOP原理 AOP采用横向抽取机制,取代了传统纵向继承体系重复性代码 传统的纵向抽取机制: 横向抽取机制: AOP操作术语 1. ...