PostgreSQL 数组类型使用详解
PostgreSQL 数组类型使用详解
PostgreSQL 数组类型使用详解
可能大家对 PostgreSQL 这个关系型数据库不太熟悉,因为大部分人最熟悉的,公司用的最多的是 MySQL
我们先对 PostgreSQL 数据库 (下面简称 PG)简单的介绍一下,以后有机会,再单独写一篇专门介绍 pgSql 的文章
The World's Most Advanced Open Source Relational Database
这是 PG 官网对自己的介绍,是的,你没有看错,“世界上最先进的开源关系型数据库”。一段严重违反我国广告法的话,上一个敢那么叫嚣的技术是 PHP,“世界上最好的语言”,然后这句话就成了码农界最广为人知的梗,存在于各种笑料中。
不过 PG 并没有因为这样明目张胆地自吹自擂而遭到什么抨击或调侃,事实上,无论在务实的码农界,抑或是讲究章法的学术界,人们对 PG 都是赞许有加,PG 是完全当得起这句话的。
下面列出一些 PostgreSQL 的特点
PostgreSQL 是一种功能非常齐全关系型数据库,由加州大学计算机系开发
PostgreSQL 开源协议是类 BSD 的自有协议 ,这是一种非常友好的协议,不论是商用还是自用,或者修改代码再起个名拿来卖钱,都没有任何风险
PostgreSQL 支持的数据类型非常多,除了常用的,还有
枚举类型,几何类型,UUID类型,json类型,数组类型等,其中数组类型也是本篇文章的目的,介绍其中数组类型的使用PostgreSQL 成立时对标的数据库是
Oracle数据库,所有 PostgreSQL 的功能和性能是非常强的。PostgreSQL 对复杂 SQL 的执行,要好于 MySql
..................
还有很多的特性,这里只简单的写几个,上面的几个特点也是我非常在意的,之所 www.helloworld.net 此次改版把 Mysql 换成了 PostgreSQL , 就是有这些原因。
之前很多人问过,hellworld开发者社区 改版用到了哪些技术栈,其中之一,就是把 Mysql 换成了 PostgreSQL
在改版的过程中,所有的表全部重新设计,这对于后端来说,是一个极其需要勇气的决定,好在我们坚持下来了
在改的过程中,其中有这样一个场景:
一篇博客,有多个标签 ,比如 一个博客,有多线程 , 并发 , 线程池 这三个标签
对于这样的需求,我们可以分析一下
- 一篇博客,有多个标签
- 一个标签,也可有对应多篇博客
这样就形成了 多对多 的关系,建表的话,就会有一张关联表,大部分会想到这样建表
博客表: blog
标签表: tag
标签博客表: tag_blog
其中各表的字段,如下(简单起见,只列出最少的列):
blog 表:
- id 数字类型,博客的 id, 自增长的主键
- title 字符串类型,博客的标题
tag 表:
- id 数字类型,标签的 id , 自增长的主键
- name 字符串类型,标签的名字
tag_blog :
- id 数字类型, 自增长的主键
- tag_id 标签 id (对应 tag 表中的 id)
- blog_id 博客 id (对应 blog 表中的 id)
上面这个博客标签需求,需要 3 张表,我们知道,PostgreSQL 的列的类型是支持数组类型的
我们是不是可以优化一下上面的需求,把 3 张表变成 1 张表
只保留一张 blog 表,在 blog 表中增加一列 tags , 类似就是 text[ ]
新的博客表字段如下:
blog 表:
- id 数字类型 (bigint),博客的 id, 自增长的主键
- title 字符串类型 (text),博客的标题
- tags 字符串数组类型 (text [] )
为了方便大家测试,建表 SQL 如下
CREATE TABLE IF NOT EXISTS public.blog
(
id bigint NOT NULL DEFAULT nextval('blog_id_seq'::regclass),
title text COLLATE pg_catalog."default",
tags text[] COLLATE pg_catalog."default",
CONSTRAINT blog_pkey PRIMARY KEY (id)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.blog
OWNER to postgres;
下面我们针对 tags 字段作一些基本操作
数组类型的基本操作
1 查询
现在表中没有数据,我们查询一下看看
select * from blog
结果如下: 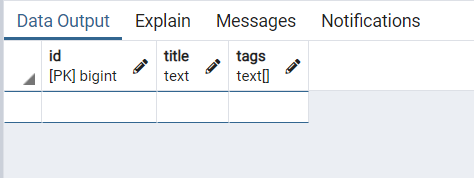
2 插入数据
插入一条记录,标题是 www.helloworld.net , 对应的标签有 3 个,分别是 helloworld , 技术 , 社区
insert into blog (title,tags) values('www.helloworld.net','{"helloworld","技术","社区"}')
再次查询
select * from blog
结果如下: 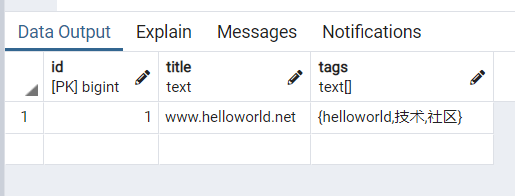
可以看到,已经有了一条数据了,tags 数组里面有 3 个元素,分别是 helloworld , 技术 , 社区
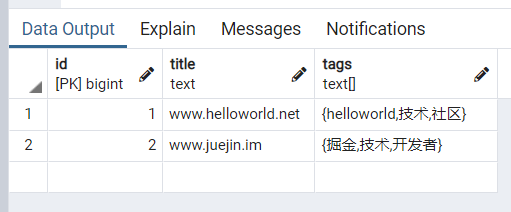
我们再次插入两条数据,方便我们测试
insert into blog (title,tags) values('www.juejin.im','{"掘金","技术","开发者"}');
insert into blog (title,tags) values('www.oschina.net','{"开源中国","oschina","开源"}');
查询结果如下:

3 条件查询
3.1 查询标签中有 技术标签的博客,语法 select * from blog where 'xx' = any(数组字段)
sql 语句如下
select * from blog where '技术'= any(tags)
查询结果如下:
3.2 查询标签中有 helloworld 标签或者有 开源中国标签的博客
sql 语句如下:
select * from blog where 'helloworld'= any(tags) or '开源中国' = any(tags)
结果如下: 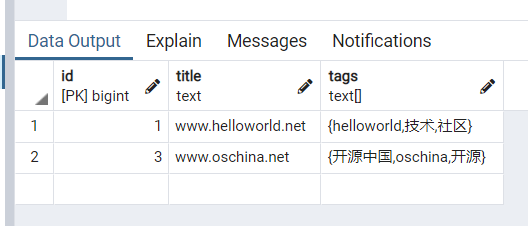
4 更新
4.1 更新标签的名称
我们将 id = 1 的记录的 tags 数组中, 社区改成开发者社区
注意:pg 中数组类型,索引是从 1 开始,我们将 id = 1 的记录,社区元素索引为 3,修改语法为: update 表名 set 字段[index] = 'xx' where id=1
sql 如下:
update blog set tags[3] = '开发者社区' where id=1
再次查询,结果如下:
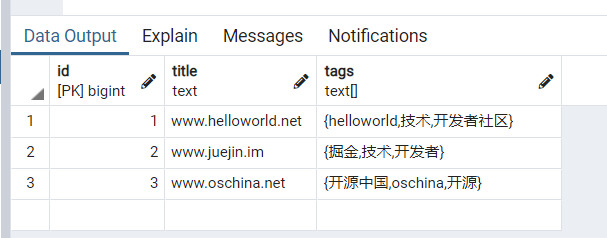
可以发现,通过 tags[3] = '开发者社区' ,成功的把 社区修改成了 开发者社区
4.2 添加一个标签
我们把 id=1 的记录,标签再增加一个 程序员标签
可以使用 PostgreSQL 的 array_append 函数
使用方法如下:
sql 写法如下:
update blog set tags = array_append(tags, '程序员'::text) where id=1
再次查询结果如下:
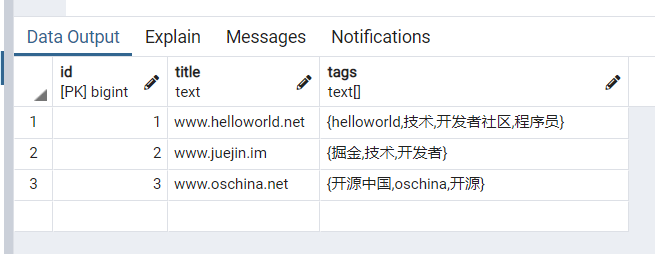
5 删除
我们删除标签
把 id= 3 的记录中的标签,删除开源
sql 如下:
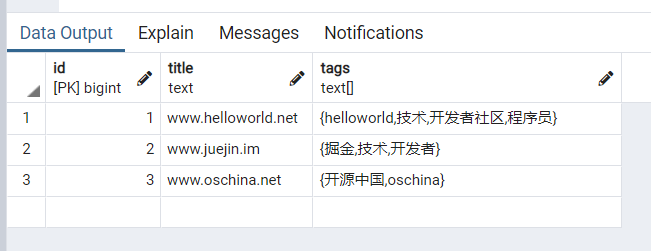
update blog set tags = array_remove(tags, '开源'::text) where id=3
执行后,再次查询,如下:
总结
以上就是关于 PostgreSQL 的数组类型的常见的用法,至于其它的用法,大家可以看一下官方文档,再结合本例的 SQL 写法
应该很容易就能掌握,博主的环境都是搭建在cnaaa服务器上的。
以上的需求,其实实际应用中并不是适合用数组类型解决,数组适合的场景,操作,交互不多,不太重要,可以用。
此例只是方便说明用法,具体实际中怎么用,大家还需要结合自己的业务需求,灵活选择
PostgreSQL 数组类型使用详解的更多相关文章
- JS类型转换规则详解
JS类型转换规则详解 一.总结 一句话总结:JS强制类型转换中的类型名强制类型转换和其它语言不同,是类型类的构造方法,Number(mix) 一句话总结(JS类型本质):因为js是弱类型语言,所以它相 ...
- 005-Scala数组操作实战详解
005-Scala数组操作实战详解 Worksheet的使用 交互式命令执行平台 记得每次要保存才会出相应的结果 数组的基本操作 数组的下标是从0开始和Tuple不同 缓冲数组ArrayBuffer( ...
- Linux Shell数组常用操作详解
Linux Shell数组常用操作详解 1数组定义: declare -a 数组名 数组名=(元素1 元素2 元素3 ) declare -a array array=( ) 数组用小括号括起,数组元 ...
- Scala 深入浅出实战经典 第54讲:Scala中复合类型实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第53讲:Scala中结构类型实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- 干货 | Elasticsearch Nested类型深入详解(转)
https://blog.csdn.net/laoyang360/article/details/82950393 0.概要在Elasticsearch实战场景中,我们或多或少会遇到嵌套文档的组合形式 ...
- 干货 | Elasticsearch Nested类型深入详解
在Elasticsearch实战场景中,我们或多或少会遇到嵌套文档的组合形式,反映在ES中称为父子文档. 父子文档的实现,至少包含以下两种方式: 1)父子文档 父子文档在5.X版本中通过parent- ...
- Struts2中 Result类型配置详解
一个result代表了一个可能的输出.当Action类的方法执行完成时,它返回一个字符串类型的结果码,框架根据这个结果码选择对应的result,向用户输出.在com.opensymphony.xwor ...
- JavaScript中数组Array方法详解
ECMAScript 3在Array.prototype中定义了一些很有用的操作数组的函数,这意味着这些函数作为任何数组的方法都是可用的. 1.Array.join()方法 Array.join()方 ...
- PostgreSQL 数组类型
PostgreSQL 支持表的字段使用定长或可变长度的一维或多维数组,数组的类型可以是任何数据库内建的类型.用户自定义的类型.枚举类型, 以及组合类型.但目前还不支持 domain 类型. 数组类型的 ...
随机推荐
- android 集成友盟实现 第三方分享 登录(qq,新浪,微信)
其实友盟的文档写的非常详细了,在这只是记录一下开发过程中遇到过的坑. 开发流程,先到友盟的官网注册账号创建应用,友盟的文档地址:http://dev.umeng.com/social/android/ ...
- Django 知识点总结
知识点总结 一.URL: 1.在python 正则表达式中,正则表达式命名组的语法是(?P<name>pattern),其中命名组中的命名就是name,并且pattern 是某些匹配的模式 ...
- git 代码强制回滚操作整理(线上线下一起)
线上代码强制回滚操作,这边整理了一下 1.到线上 执行 git reset --hard xxxxxxxxxxx(更新前的一个版本)2.本地执行 和上面一样 git reset --hard xxxx ...
- .NET Core3.1升级.NET5 oracle连接报错
如果报以下错误 The type initializer for 'OracleInternal.ServiceObjects.OracleConnectionImpl' threw an excep ...
- locust socektio协议压测
# -*-coding:UTF-8 -*- from locust import HttpLocust, TaskSet, task, TaskSequence, Locust, events imp ...
- JS篇(010)-JavaScript 继承的方式和优缺点
答案:六种方式 一.原型链继承 缺点: 引用类型的属性被所有实例共享 在创建 Child 的实例时,不能向 Parent 传参 二.借用构造函数(经典继承) 优点: 避免了引用类型的属性被所有实例共享 ...
- 自定义go语言日志输出
自定义输出符合下列需求: 1.含两类日志输出方式:调试模式下输出到控制台:生产环境输出到日志文件 2.调用不同的函数/方法构造不同的输出方式,后续只需调用日志级别对应的函数即可输出该级别日志 工具构造 ...
- kafka常用命令(zookeeper与bootstrap-server)
在 0.9.0.0 之后的 Kafka,出现了几个新变动,一个是在 Server 端增加了 GroupCoordinator 这个角色,另一个较大的变动是将 topic 的 offset 信息由之前存 ...
- 在Windows系统上安装和配置Jenkins自动发布
一.安装jenkins的流程转载于: https://www.jianshu.com/p/de9c4f5ae7fa 二.在window中执行批处理文件bat或者powershell可以成功,但是Jen ...
- 莫凡PYthon之keras 1
莫凡PYthon 1 kearsregressionpython Regressor 回归 用神经网络去拟合数据. 主要代码 """ Regressor 回归 " ...