Hadoop-集群运行
前提:需要在上节Hadoop文件参数配置的基础上完成
步骤一、NameNode 格式化
第一次启动 HDFS 时要进行格式化,否则会缺失 DataNode 进程。另外,只要运行过 HDFS,Hadoop 的工作目录(本书设置为/usr/local/src/hadoop/tmp)就会有数据,如果需要重新格式化,则在格式化之前一定要先删除工作目录下的数据,否则格式化时会出问题。
(master节点)
[root@master ~]# su - hadoop
[hadoop@master ~]$ cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ ./bin/hdfs namenode -format
22/04/01 17:37:26 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.100.10
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.1
……
……
22/04/01 17:37:26 INFO common.Storage: Storage directory /usr/local/src/hadoop/dfs/name has been successfully formatted.
22/04/01 17:37:26 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
22/04/01 17:37:26 INFO util.ExitUtil: Exiting with status 0
22/04/01 17:37:26 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.100.10
************************************************************/
以上出现successfully说明格式化成功
步骤二、启动 NameNode
(master节点)
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode
starting namenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-namenode-master.example.com.out
[hadoop@master hadoop]$ jps
41732 NameNode
41801 Jps
看到NameNode说明成功
步骤三、启动 SecondaryNameNode
(master节点)
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-secondarynamenode-master.example.com.out
[hadoop@master hadoop]$ jps
41732 NameNode
41877 Jps
41834 SecondaryNameNode
看到SecondaryNameNode说明成功
步骤四、slave 启动 DataNode
(slave1和slave2节点)
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave1.example.com.out
[hadoop@slave1 ~]$ jps
41552 DataNode
41627 Jps
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /usr/local/src/hadoop/logs/hadoop-hadoop-datanode-slave2.example.com.out
[hadoop@slave2 ~]$ jps
4161 DataNode
4236 Jps
看到DataNode说明成功
步骤五、查看 HDFS 的报告
(master节点)
[hadoop@master hadoop]$ hdfs dfsadmin -report
Configured Capacity: 34879832064 (32.48 GB)
Present Capacity: 26675437568 (24.84 GB)
DFS Remaining: 26675429376 (24.84 GB)
DFS Used: 8192 (8 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.100.20:50010 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 16640901120 (15.50 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 4275404800 (3.98 GB)
DFS Remaining: 12365492224 (11.52 GB)
DFS Used%: 0.00%
DFS Remaining%: 74.31%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 01 17:41:17 CST 2022
Name: 192.168.100.30:50010 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 3928989696 (3.66 GB)
DFS Remaining: 14309937152 (13.33 GB)
DFS Used%: 0.00%
DFS Remaining%: 78.46%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Apr 01 17:41:17 CST 2022
步骤六、浏览器查看节点状态
需要在windows真机上执行
1、进入C:\Windows\sytstem32\drivers\etc\
2、把此目录下的hosts文件拖到桌面上
3、右键打开此文件加入IP与主机名的映射关系
192.168.100.10 master master.example.com
192.168.100.20 slave1 slave1.example.com
192.168.100.30 slave2 slave2.example.com
4、保存后拖回原位置
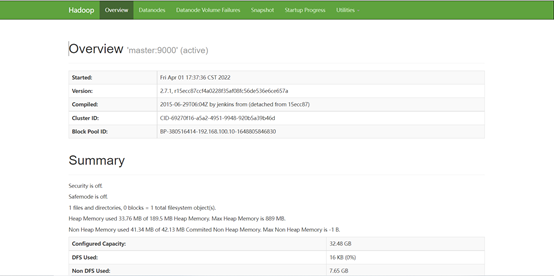
在浏览器访问:http://master:50070,可以查看NameNode和DataNode 信息
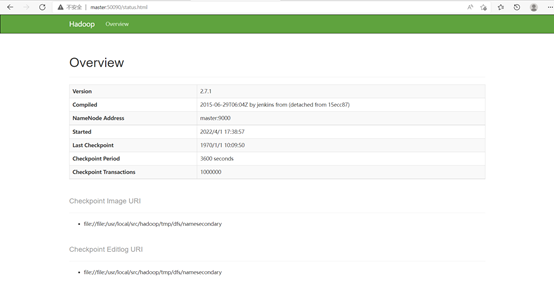
在浏览器访问: http://master:50090,可以查看 SecondaryNameNode 信息
步骤七、配置免密登录
启动 HDFS之前需要配置 SSH 免密码登录,否则在启动过程中系统将多次要求确认连接和输入 Hadoop 用户密码。
(master节点)
[hadoop@master ~]$ ssh-keygen -t rsa
……
[hadoop@master ~]$ ssh-copy-id slave1
……
[hadoop@master ~]$ ssh-copy-id slave2
……
[hadoop@master ~]$ ssh-copy-id master
……
步骤八、启动dfs 和 yarn
(master节点)
[hadoop@master ~]$ stop-dfs.sh
……
[hadoop@master ~]$ start-dfs.sh
……
[hadoop@master ~]$ start-yarn.sh
……
[hadoop@master ~]$ jps
45284 SecondaryNameNode
45702 Jps
45080 NameNode
45435 ResourceManager
(slave1和slave2节点)
[hadoop@slave1 ~]$ jps
42986 DataNode
43213 Jps
43102 NodeManager
[hadoop@slave2 ~]$ jps
42986 DataNode
43213 Jps
43102 NodeManager
在master上看到ResourceManager,并且在slave上看到NodeManager就说明启动成功
步骤九、运行WordCount测试
运行 MapReduce 程序,需要先在 HDFS 文件系统中创建数据输入目录,存放输入数据。
注意:创建的/input 目录是在 HDFS 文件系统中,只能用 HDFS 命令查看和操作。
(master节点)
[hadoop@master ~]$ hdfs dfs -mkdir /input
[hadoop@master ~]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2022-04-01 19:50 /input
[hadoop@master ~]$ mkdir ~/input
[hadoop@master ~]$ vi input/data.txt
Hello World
Hello Hadoop
Hello Huasan
将输入数据文件复制到 HDFS 的/input 目录中
[hadoop@master ~]$ hdfs dfs -put ~/input/data.txt /input
[hadoop@master ~]$ hdfs dfs -cat /input/data.txt
Hello World
Hello Hadoop
Hello Huasan
运行 WordCount
注意:数据输出目录/output不能提前创建,否则会报错
(master节点)
[hadoop@master ~]$ hadoop jar /usr/local/src/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/data.txt /output
22/04/01 19:58:10 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
22/04/01 19:58:10 INFO input.FileInputFormat: Total input paths to process : 1
22/04/01 19:58:10 INFO mapreduce.JobSubmitter: number of splits:1
22/04/01 19:58:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1648813571523_0001
22/04/01 19:58:11 INFO impl.YarnClientImpl: Submitted application application_1648813571523_0001
22/04/01 19:58:11 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1648813571523_0001/
22/04/01 19:58:11 INFO mapreduce.Job: Running job: job_1648813571523_0001
22/04/01 19:58:17 INFO mapreduce.Job: Job job_1648813571523_0001 running in uber mode : false
22/04/01 19:58:17 INFO mapreduce.Job: map 0% reduce 0%
22/04/01 19:58:20 INFO mapreduce.Job: map 100% reduce 0%
22/04/01 19:58:25 INFO mapreduce.Job: map 100% reduce 100%
22/04/01 19:58:26 INFO mapreduce.Job: Job job_1648813571523_0001 completed successfully
22/04/01 19:58:26 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=56
……
出现successfully说明运行成功
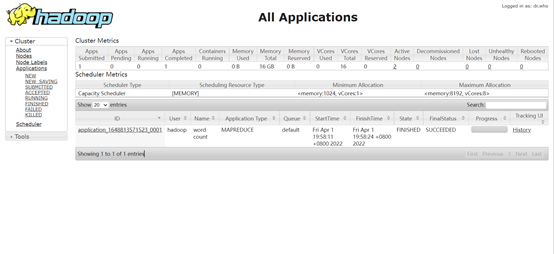
在浏览器访问: http://master:8088,可以看到运行成功
在浏览器访问: http://master:50070,在 Utilities 菜单中选择 Browse the file system,可以查看 HDFS 文件系统内容。
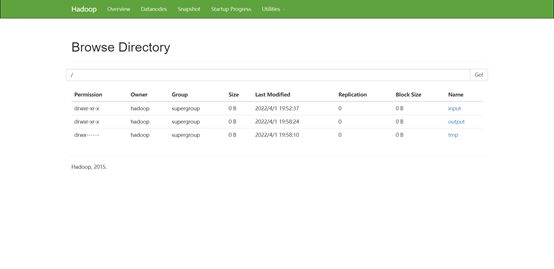
查看 output 目录,文件_SUCCESS 表示处理成功,处理的结果存放在 part-r-00000 文件中。
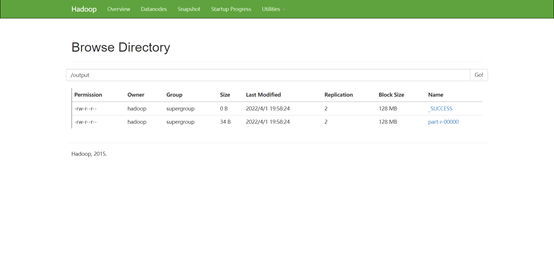
也可以直接使用命令查看 part-r-00000 文件内容
(master节点)
[hadoop@master ~]$ hdfs dfs -cat /output/part-r-00000
Hadoop 1
Hello 3
Huasan 1
World 1
步骤十、停止 Hadoop
使用stop-all.sh一条命令就可以全部停止
(master节点)
[hadoop@master ~]$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
192.168.100.30: stopping datanode
192.168.100.20: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
192.168.100.20: stopping nodemanager
192.168.100.30: stopping nodemanager
192.168.100.20: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
192.168.100.30: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
查看 JAVA 进程
[hadoop@master ~]$ jps
46683 Jps
[hadoop@slave1 ~]$ jps
43713 Jps
[hadoop@slave2 ~]$ jps
41702 Jps
声明:未经许可,不得转载
Hadoop-集群运行的更多相关文章
- Hadoop集群运行JNI程序
要在Hadoop集群运行上运行JNI程序,首先要在单机上调试程序直到可以正确运行JNI程序,之后移植到Hadoop集群就是水到渠成的事情. Hadoop运行程序的方式是通过jar包,所以我们需要将所有 ...
- 编写hadoop程序,并打包jar到hadoop集群运行
windows环境下编写hadoop程序 新建:File->new->Project->Maven->next GroupId 和ArtifactId 随便写(还是建议规范点) ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- 编写hadoop程序并打成jar包上传到hadoop集群运行
准备工作: 1. hadoop集群(我用的是hadoop-2.7.3版本),这里hadoop有两种:1是编译好的hadoop-2.7.3:2是源代码hadoop-2.7.3-src: 2. 自己的机器 ...
- 攻城狮在路上(陆)-- 提交运行MapReduce程序到hadoop集群运行
此种方式不能直接在eclipse中调试代码. 首先需要在src下放置服务器上的hadoop配置文件:core-site.xml\yarn-site.xml\hdfs-site.xml\mapred-s ...
- hadoop集群运行jps命令以后Datanode节点未启动的解决办法
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而da ...
- hadoop集群运行dedup实现去重功能
一.配置开发环境1.我们用到的IDE是eclipse.要用它进行hadoop编程,要给eclipse安装hadoop自带的插件.(有的版本以源码提供插件,需要用户根据需要自己编译)2.用到的eclip ...
- Hadoop集群运行
在Hadoop文件参数配置完成之后 在master上操作 su - hadoop cd /usr/local/src/hadoop/ ./bin/hdfs namenode -format hadoo ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- 大数据系列(1)——Hadoop集群坏境搭建配置
前言 关于时下最热的技术潮流,无疑大数据是首当其中最热的一个技术点,关于大数据的概念和方法论铺天盖地的到处宣扬,但其实很多公司或者技术人员也不能详细的讲解其真正的含义或者就没找到能被落地实施的可行性方 ...
随机推荐
- python的数据结构和基本语法
1.支持的数据类型 str(字符串类型).int(整型).flout(浮点型).bool(逻辑值).complex(复数[数学上的]).bytes(字节型).list(列表).tuple(元组[不可以 ...
- htm5基本学习
HTML学习 1.HTML概念 1.1.HTML是什么 Hyper Text Markup Language (超文本标记语言)包括:文字.图片.音频.视频.动画等. 1.2.HTML优势 所有浏览器 ...
- 初探JVM字节码
作者: LemonNan 原文地址: https://juejin.im/post/6885658003811827725 代码地址: https://github.com/LemonLmNan/By ...
- Java GUI 实现发送邮件以及附件
实现代码: 注意点: 需要的jar包:JavaMail API 和Java Activation Framework (JAF) ,下载可参考菜鸟教程 默认使用QQ邮箱发送,需要设置授权,设置--&g ...
- ArcGIS进行容积率计算
空间分析--题目2 容积率(Plot Ratio/Floor Area Ratio/Volume Fraction)又称建筑面积毛密度,是指一个小区的地上总建筑面积与用地面积的比率.对于开发商来说,容 ...
- Android系统编程入门系列之硬件交互——通信硬件电信SIM卡
现在的SIM卡通常具备基站定位.语音通话.短信消息.网络流量这四大功能,而在移动端是无法对SIM卡使用基站定位功能的,所以这里只介绍移动端如何使用SIM卡实现语音通话.短信消息.数据流量三个功能. 语 ...
- Redis(一):基本数据类型与底层存储结构
最近在整理有关redis的相关知识,对于redis的基本数据类型以及其底层的存储结构简要的进行汇总和备注(主要为面试用) Redis对外提供的基本数据类型主要为五类,分别是 STRING:可以存储字符 ...
- ssm配置推荐
1.JDK 1.8 2.Mysql 5.7 3.Maven 3.6.1
- ctf之Flask_fileUpload
启动环境,显示如图: 直接f12产看源码信息: 大致意思是:使用python编写文件然后以图片格式上传系统会以ipython格式解析,就可获取flag. 编写python代码: import os o ...
- @Transactional注解的失效场景
一口气说出 6种,@Transactional注解的失效场景 计算机java编程 发布时间: 20-03-1912:35优质科技领域创作者 引言 昨天公众号粉丝咨询了一个问题,说自己之前面试被问@Tr ...