RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer概述
0.前言
发表时间:NeurlPS2022(2022.10.13)
1.摘要
最近,基于Transformer的网络在语义分割方面取得了令人印象深刻的结果。然而在实时语义分割方面,由于Transformer的计算机制耗时,纯基于cnn的方法仍然在这一领域占主导地位。我们提出了一种高效的实时语义分割双分辨率TransformerRTprorr,它比基于CNN的模型在性能和效率之间实现更好的权衡。为了在GPU这类设备上实现高推理效率,我们的RTformer利用了线性复杂度的GPU友好注意力,并抛弃了多头机制。此外,我们发现交叉分辨率注意通过传播从低分辨率分支获得的高级知识,可以更有效地收集高分辨率分支的全局上下文信息。在主流基准上的大量实验证明了我们提出的RTformer的有效性,它在Cityscapes,CamVid和COCOStuff上取得了最先进的水平,并在ADE20K上显示出了良好的结果。
2.主要贡献
•提出了一种新的RTFormer块,它在GPU类设备上实现了语义分割任务的性能和效率之间更好的权衡。
•提出了一种新的网络架构RTFormer,该架构能够在不降低效率的前提下,深度利用注意力,充分利用全局上下文来改进语义分割。
•RTFormer在Cityscapes、CamVid和COCOStuff上达到了最先进的水平,并在ADE20K上显示出有前景的性能。此外,它为实时语义分割任务的实践提供了一个新的视角。
3.方法
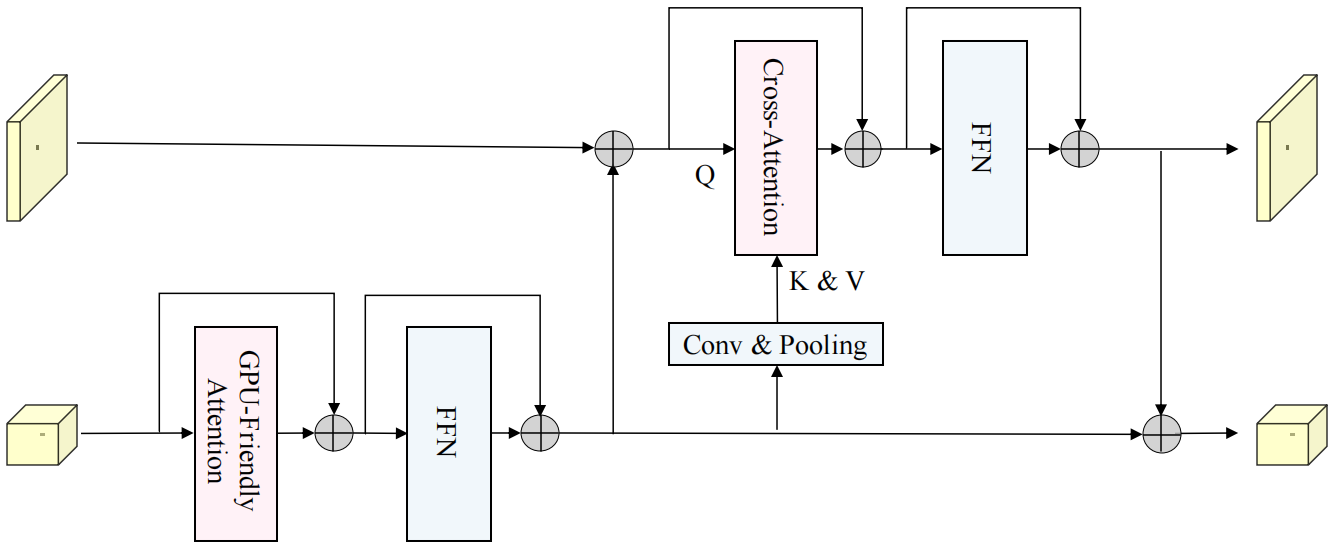
RTFrormerer块包括两个分支,一个分支使用GPU友好型注意力,另一个使用跨分辨率注意力。
GPU友好型注意力是由External Attention(EA)衍生而来的。
EA基于两个外部的,小的,可学习的和共享的存储器,只用两个级联的线性层和归一化层就取代了现有流行的学习架构中的Self-attention,具体来说,通过两个由线性层实现的包含整个数据集特征的记忆单元,维度为Mxd,替换K和V,从而既使得每个样本能与其他样本交互,又减少了计算量。公式表示如下:
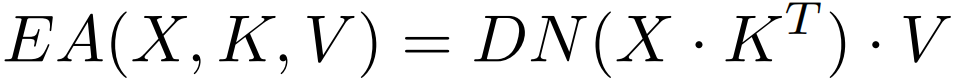
图中H表示头数,EA使用了多头机制,虽然通过共享K'和V'加快了计算速度,但是矩阵乘法操作依旧存在。DN表示double-normalization,分别对行和列进行归一化。
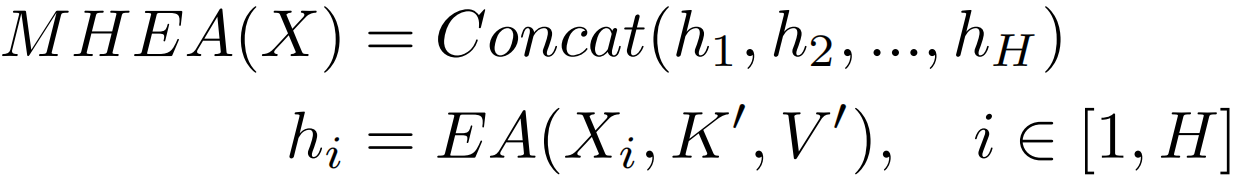
为了减少多头机制带来的计算量,作者提出了GPU-Friendly Attention,公式为:
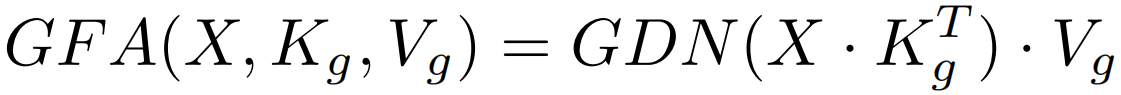
其中Kg,Vg ∈RMg×d,Mg = M × H, GDN表示分组双归一化,将原双归一化的第二次归一化分成H组,EA和GFA对比如下图:
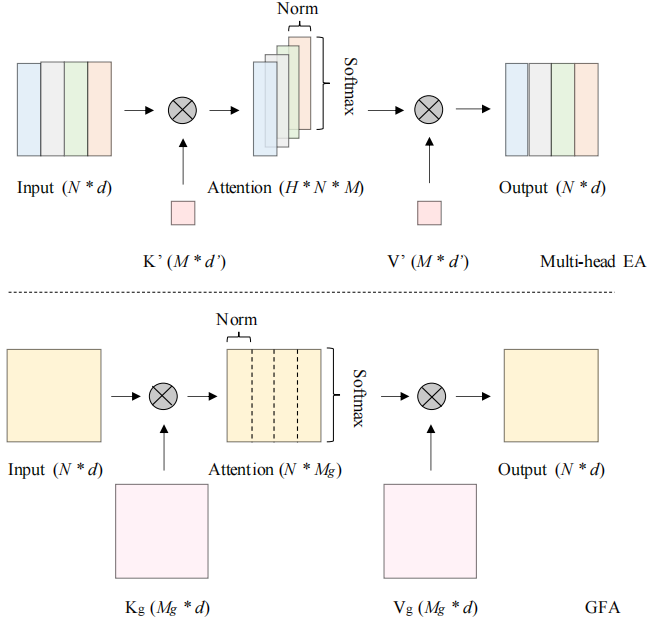
GFA有两个主要的改进。一方面,它能集成矩阵乘法,这对于gpu类设备来说是相当友好的。得益于此,可以将外部参数的大小从(M, d')扩大到(Mg, d),因此可以调优更多的参数来提高性能。另一方面,利用分组双归一化,在一定程度上保持了多头机制的优越性。为了直观理解,可以认为GFA也生成了H个不同的注意力图来捕捉不同的token之间的关系,但相似度计算涉及了更多的特征元素,且所有的注意力图都对最终的输出有贡献。
跨分辨率注意力 多分辨率融合已被证明对密集预测任务是有效的。而对于多分辨率架构的设计,可以直观地将GFA独立应用于不同分辨率的分支,并在执行卷积模块或注意力模块后交换特征。但在高分辨率分支中,像素更关注局部信息,而非高层次的全局上下文。因此,作者认为直接将注意力转移到高分辨率特征图上学习全局上下文是不够有效的。为了更有效地获取全局上下文,提出了跨分辨率注意力机制,旨在充分利用从低分辨率分支中学习到的高层语义信息。如下图所示,计算公式如下:
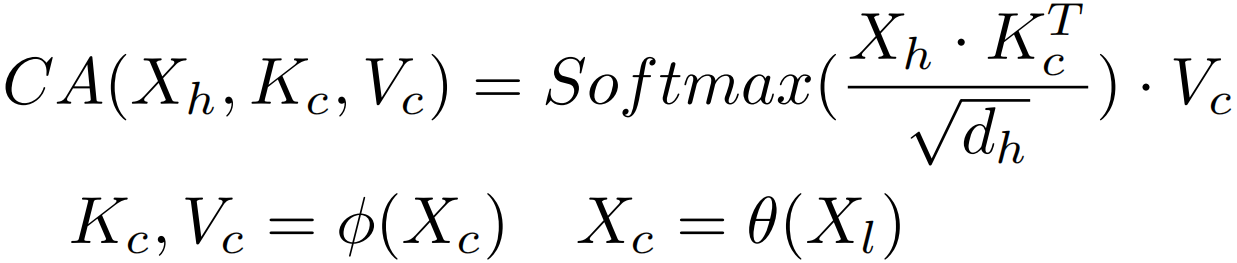
其中Xh, Xl分别表示高分辨率分支和低分辨率分支上的特征映射,φ是一组包括splitting,permutation和reshaping的矩阵操作,dh表示高分辨率分支的特征维数。Xc为交叉特征,θ函数由池化层和卷积层组成,Xc的空间大小表示从xl生成的token数。在实验上,只在注意力图的最后一个轴上使用softmax进行归一化,因为当key和value不是外部参数时,单个softmax比双归一化性能更好。此外,为了计算性能,这里没有使用多头机制。
Feed Forward Network 在以前的基于Transformer的分割方法中,前馈网络(FFN)通常由两个MLP层和一个深度3×3卷积层组成,其中深度3×3卷积用于补充位置编码或增强局部性。此外,两个MLP层将隐藏维度扩展为输入维度的2到4倍。这种类型的FFN可以用相对较少的参数获得更好的性能。但在应该考虑类GPU设备上的延迟的情况下,FFN的典型结构不是很有效。为了平衡性能和效率,在RTFormer块的FFN中采用了两个3×3卷积层,而没有进行维数扩展。与典型的FFN配置相比,它显示了更好的结果。
RTFrormerer块如下。对于低分辨率,采用GPU友好型注意来捕获高层次的全局上下文。对于高分辨率,使用跨分辨率注意力,将从低分辨率分支学习到的高层全局上下文传播到每个高分辨率像素,并通过stage布局将更有代表性的特征从低分辨率分支提供给交叉分辨率注意力。它从低分辨率分支中提取K和V。此外,用两个3×3卷积层组成FFN。
RTFrormer体系结构说明。将RTFrormer块放置在最后两个阶段,用粉色块表示,在早期阶段使用卷积块,用蓝色块表示。此外,利用DDRNet的成功经验,添加了一个针对分割头的DAPPM(Deep Aggregation Pyramid Pooling Module)模块。
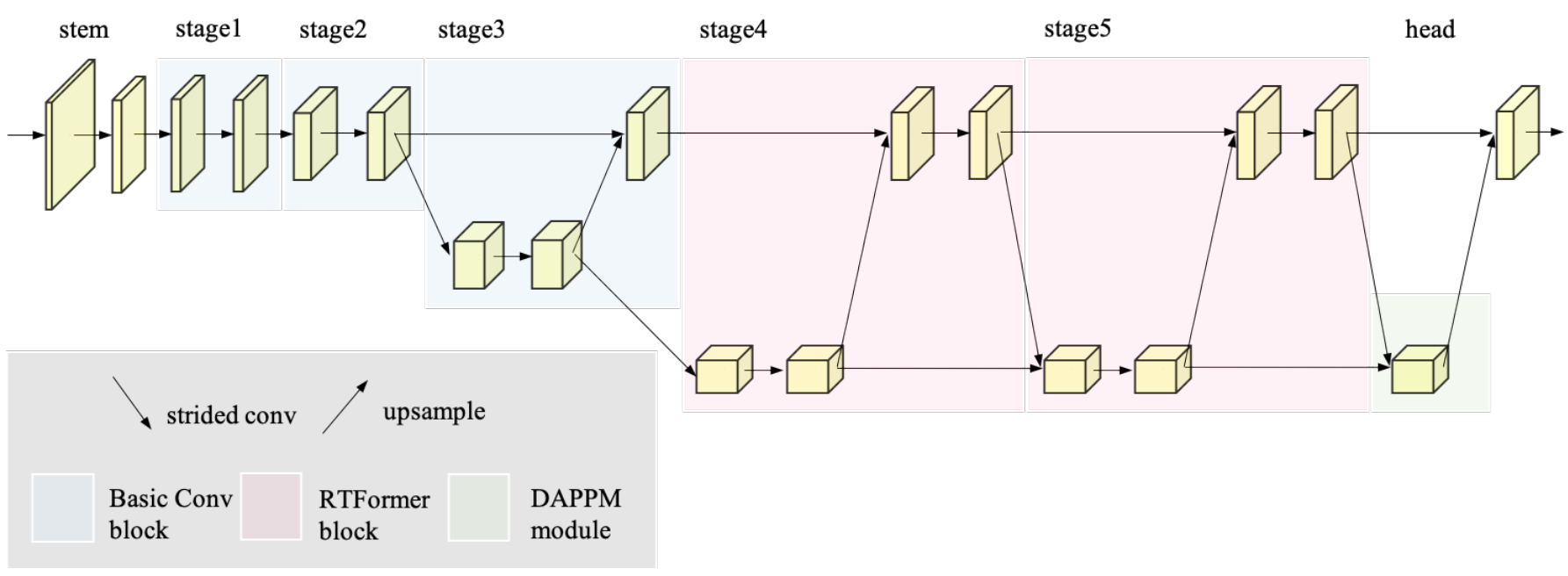
为了提取高分辨率特征图所需的足够的局部信息,将卷积层与RTFormer块相结合来构造RTFormer。具体来说,让RTFormer从一个由两个3×3卷积层组成的stem块开始,用几个连续的基本残差块组成前两个阶段。然后,从第3阶段开始,使用双分辨率模块,实现高分辨率和低分辨率分支之间的特征交换。对于最后三个阶段的高分辨率分支,特征stride保持为8不变,而对于低分辨率分支,则特征stride分别为16、32、32。特别是,将双分辨率模块安排为阶梯式布局,以借助低分辨率分支的输出增强高分辨率特征的语义表示。最重要的是,用提出的RTFormer块构造了stage4和stage5,如图2所示,用于有效的全局上下文建模,而stage3仍然由基本残差块组成。
4.结论
在本文中,我们提出了可以有效地捕获全局上下文,以提高实时语义分割性能的RTFormer。大量的实验表明,我们的方法不仅在通用的实时分割数据集上取得了最新的结果,而且在具有挑战性的一般语义分割数据集上表现出了优越的性能。由于前者的效率,我们希望我们的方法可以鼓励新的实时语义分割设计。一个限制是,虽然我们的RTFormer Slim只有4.8M参数,但边缘设备芯片可能需要更高的参数效率。我们把它留给以后的工作吧。
5.补充
DAPPM(Deep Aggregation Pyramid Pooling Module)模块结构如下:
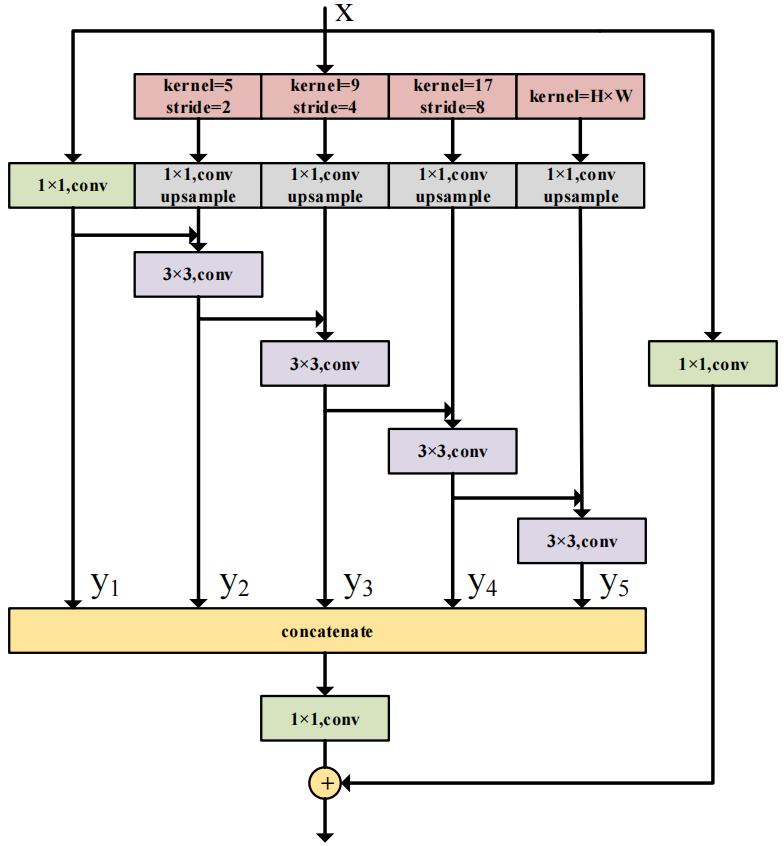
用于进一步从低分辨率的特征图中提取上下文信息。以层次-残差的方式融合不同尺度的上下文信息。
RTFormer: Efficient Design for Real-Time Semantic Segmentation with Transformer概述的更多相关文章
- Review of Semantic Segmentation with Deep Learning
In this post, I review the literature on semantic segmentation. Most research on semantic segmentati ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- Fully Convolutional Networks for Semantic Segmentation 译文
Fully Convolutional Networks for Semantic Segmentation 译文 Abstract Convolutional networks are powe ...
- 论文笔记之:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation xx
- 论文笔记之:Instance-aware Semantic Segmentation via Multi-task Network Cascades
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai Kaiming He Jian Sun ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- 论文笔记(3):STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation
论文题目是STC,即Simple to Complex的一个框架,使用弱标签(image label)来解决密集估计(语义分割)问题. 2014年末以来,半监督的语义分割层出不穷,究其原因还是因为pi ...
- 论文阅读 | A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
paper链接:https://arxiv.org/pdf/1812.09953.pdf code链接:https://github.com/YangZhang4065/AdaptationSeg 摘 ...
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
随机推荐
- django.core.exceptions.ImproperlyConfigured: Field name `tester_id` is not valid for model `WebCase`.
代码: class WebCase(models.Model): id = models.AutoField(primary_key=True) casename = models.CharField ...
- vue 点击按钮添加一行dom节点
如图,最近项目需求,点击添加一行dom节点,包含下拉框和input输入框 ,下面展示一下代码 <ul class="sales-menuItem-ul"> <li ...
- 3、swagger调试
Swagger: 1.将项目中所有的接口展现在页面上,这样后端程序员就不需要专门为前端使用者编写专门的接口文档: 2.当接口更新之后,只需要修改代码中的Swagger描述就可以实时生成新的接口文档了, ...
- 基于jQuery的三种AJAX请求
基于jQuery的三种AJAX请求 1. 介绍 get请求 通常用于 获取服务端资源(向服务器要资源) 例如:根据URL地址,从服务器获取HTML文件.CSS文件.JS文件.图片文件.数据资源等. ...
- [seaborn] seaborn学习笔记8-避免过度绘图Avoid Overplotting
8 避免过度绘图Avoid Overplotting(代码下载) 过度绘图是散点图及几天常见图表中最常见的问题之一.如下图所示当数据集很大时,散点图的点会重叠,使得图形变得不可读.在这篇文章中,提出了 ...
- JAVA中使用最广泛的本地缓存?Ehcache的自信从何而来2 —— Ehcache的各种项目集成与使用初体验
大家好,又见面了. 本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面.如果感兴趣,欢迎关注以获取后续更新. 在上一篇文章<JAVA中使用最广 ...
- 腾讯出品小程序自动化测试框架【Minium】系列(一)环境搭建之第一个测试程序
一.什么是Minium? minium是为小程序专门开发的自动化框架,使用minium可以进行小程序UI自动化测试. 当然,它的能力不仅仅局限于UI自动化, 比如: 使用minium来进行函数的moc ...
- 企业应用架构研究系列十三:整合EFCore&Dapper 通用ORM框架EFDapper
EntityFrameworkCore是微软官网提供的ORM框架,是轻量化.可扩展.开源和跨平台的数据访问技术框架,但是在.Net 开发圈的评论却褒贬不一.很多人认为EFCore 执行的效能比较差,很 ...
- printf()和scanf()的*修飾符
如果你不想預先設置字段的寬度,想通過程序來進行設定,則可以可以使用"*"來進行修飾字段的寬度,前提是在程序中要包含"*"和參數對應的值(比如%*d,那麽參數應該 ...
- maven打包出现Failed to execute goal xxx.plugins:maven-compiler-plugin:3.7.0:compile.......:Fatal error compiling解决方法
起初在给项目打包时出现了这个错: 网上查了很多资料,都说JDK配置不对,我检查了一下,发现明明都一样. 为了获取更详细的报错信息,我决定用命令行的打包方式来编译: cd进去要打包的这个目录,用命令行的 ...