【论文阅读】ConvNeXt:A ConvNet for the 2020s 新时代卷积网络
一、ConvNext Highlight
核心宗旨:基于ResNet-50的结构,参考Swin-Transformer的思想进行现代化改造,知道卷机模型超过trans-based方法的SOTA效果。
启发性结论:架构的优劣差异没有想象中的大,在同样的FLOPs下,不同的模型的性能是接近的。
意义:这篇文章可以作为很好的索引,将一些从卷积网络演进过程中的重要成果收录,适合新手。
二、背景介绍(Related Work)
2.1 一句话回顾ResNet-50
由48层卷积 + 1个maxpool + 1个 avgpool构成。1 个early downsampling的stem + 4个block,每个block的配比是3:4:6:3

2.2 Trans-based?为什么好?
- 为什么Transformer强:归纳偏置小,A Survey of Transformers
- CNN的先验:局部相关性、全局共享性
- RNN的先验:时间依赖
- Trans的先验:只有position、先验小、模型上线高 大数据下表现更好 -> 小数据下只能增加正则项 / 引入结构偏置
- 这么好,为啥前几年在NLP里用,CV领域从20年才开始用
- Trans模型的核心计算在自注意力机制,平方复杂度
- 在NLP领域把 字/词作为最小力度单元,在图像上使用像素作为最小力度单元? -> 复杂度高、单像素信息含量太小
2.3 Trans-based这么好 要怎么用到CV(ViT Swin-T)
- 一个Naive的想法:不把像素当做最小单元,把图像拆成若干小块(称作patch),把小块视作基本单元?
- 上面Naive的想法真的可行!把小patch串起来变成embedding->ViT
- ViT的两个理解视角:
- DNN的视角:把图像切割img2patch,再把patch通过仿射变换 patch2embedding
- CNN的视角:先通过全图的二维卷积(stride = kenerl size),再flatten the feature map
- 更多细节:position embedding可学习, + classification head + 无trans decoder

- 不引入先验的确让模型理论上限更高了,但学习难度也加大了,而且 O(n2)的复杂度还是很难顶 -> Swin-Transformer
- Swin-T核心:采用层次化的设计,将复杂度从O(n^2)降到了O(n)、引入了CNN的局部性先验

三、Convnext又做了哪些事
3.1 超级详尽的实验 和 模型改造
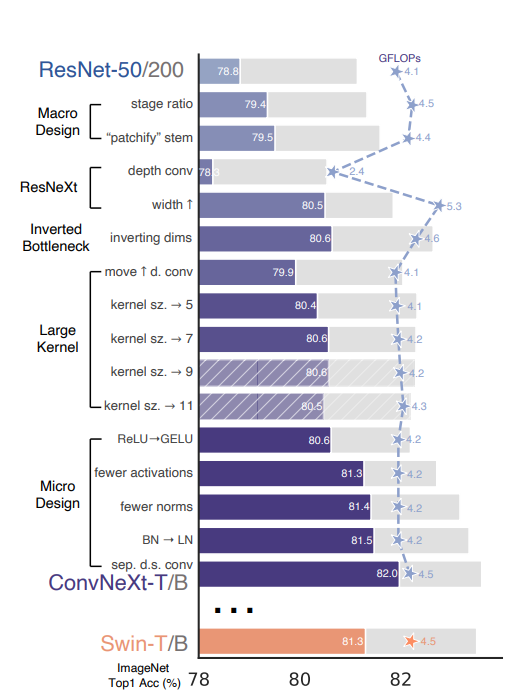
3.2 在实验之前,先在小数据集上获得好的优化器参数
- AdamW, 300epoch,预训练学习率4e-3,weight decay= 0.05,batchsize = 4096;微调学习率 5e-5, weight decay= 1e-8 ,batchsize = 512
- 准确率直接从76.1升到了78.8
3.3 宏观设计
- 修改区块占比:将[3,4,6,3]的区块比例改为了[3,3,9,3] -> 79.4
- RegNet和EfficientNetV2论文中都指出,后面的stages应该占用更多的计算量。
- patchy化:将底层的7*7卷积替换成了4*4 stride=4的卷积,相当于进行原图上的分块 ->79.5
- 深度可分离卷积:参考ResNext的结论,将普通卷积替换成深度可分离卷积(群卷积的一种),参数量降低可以让channel提高到96,达到与Swin-T相同。
- ResNext的指导性建议:use more groups, expand width

- inverted bottleneck:引入了mobilenetV2中的结构,并且探索了更好的setting -> 80.6

- 为了尝试不同的kernel size,调整了卷积的位置(这使得FLOPS降低、精度发生了降低),调整后的结构如figure3-(c)
- 这样调整之后可以实验不同kernel size。Swin-T的窗口是7*7,ConvNext也发现7*7最好
3.4 微观设计
- 更换激活:ReLU替换为GeLU(+0.1)
- 减少激活的数量(+0.7)、减少batchnorm(+0.1),整体设置与Swin-T相同
- 为了跟Swin-T一致,在block开始添加1*1卷积(无效)
- 更换归一化:用LayerNorm替换BatchNorm(+0.1)
- 更换下采样:下采样从 3*3 stride=2,代替为2*2 stride=2(可分离下采样)-> 训练不收敛
- 在stem之后,每个下采样层之前以及global avg pooling之后都增加一个LayerNom (+0.5)

3.4 最终的模型
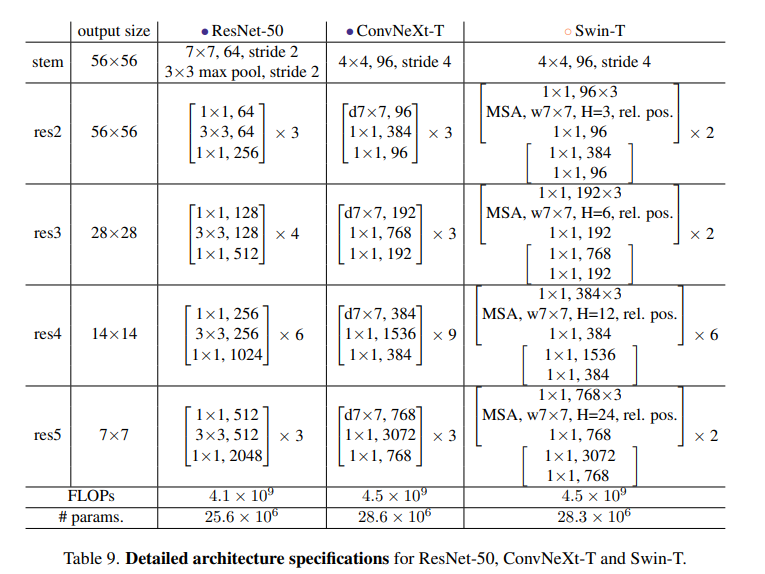
四、实验结论
五、碎碎念
最近我们有一篇工作也是设计了一个全卷积的网络,也是用了深度可分离、inverted bottleneck、LN代替BN,但远远没有这篇论文做得细致。实验过程中遇到的难收敛问题或许是更值得探索的内容,可惜志不在此,希望学弟能够更细致得探索吧。
【论文阅读】ConvNeXt:A ConvNet for the 2020s 新时代卷积网络的更多相关文章
- CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
前言 本文深入探讨了如何设计神经网络.如何使得训练神经网络具有更加优异的效果,以及思考网络设计的物理意义. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘 ...
- 论文阅读(XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification )
目录 XiangBai--[PAMI2018]ASTER_An Attentional Scene Text Recognizer with Flexible Rectification 作者和论文 ...
- Action4D:人群和杂物中的在线动作识别:CVPR209论文阅读
Action4D:人群和杂物中的在线动作识别:CVPR209论文阅读 Action4D: Online Action Recognition in the Crowd and Clutter 论文链接 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记(一)FCN
本文先对FCN的会议论文进行了粗略的翻译,使读者能够对论文的结构有个大概的了解(包括解决的问题是什么,提出了哪些方案,得到了什么结果).然后,给出了几篇博文的连接,对文中未铺开解释的或不易理解的内容作 ...
随机推荐
- zookeeper有几种部署模式? zookeeper 怎么保证主从节点的状态同步?
一.zookeeper的三种部署模式 Zookeeper 有三种部署模式分别是单机模式.伪集群模式.集群模式.这三种模式在不同的场景下使用: 单机部署:一般用来检验 Zookeeper 基础功能,熟悉 ...
- 面试问题之C++语言:类模板声明与定义为何不能分开
C++中每个对象所占用的空间大小,是在编译的时候就确定的,在模板类没有真正的被使用之前,编译器是无法知道,模板类中使用模板类型的对象的所占用的空间的大小的.只有模板被真正使用的时候,编译器才知道,模板 ...
- jsp:useBean报错The value for the useBean class attribute X is invalid
一.解决方法 1.先检查<jsp:useBean id="dog" class="cn.edu.dgut.el.tools.Dog" scope=&quo ...
- 二十、生成BOM表
- JS练习实例--编写经典小游戏俄罗斯方块
最近在学习JavaScript,想编一些实例练练手,之前编了个贪吃蛇,但是实现时没有注意使用面向对象的思想,实现起来也比较简单所以就不总结了,今天就总结下俄罗斯方块小游戏的思路和实现吧(需要下载代码也 ...
- IDEA安装配置Scala环境
这里有详细步骤:windows上 IntelliJ IDEA安装scala环境 详细 初学
- Java/C++实现观察者模式--股票价格
当股票的价格上涨或下降5%时,会通知持有该股票的股民,当股民听到价格上涨的消息时会买股票,当价格下降时会大哭一场. 类图: Java代码: public class Investor implemen ...
- tomcat启动报错:A child container failed during start
环境:maven3.3.9+jdk1.8+tomcat8.5 错误详细描述: 严重: A child container failed during start java.util.concurren ...
- Java中数组的定义与使用(代码+例子)
学习目标: 掌握一维数组的使用 学习内容: 1.一维数组的定义 数组(Array),是把具有 相同类型 的多个常量值 有序组织 起来的一种数据形式.这些按一定顺序排列的多个数据称为数组.而数组中的每一 ...
- nodejs教程---基于expressJs框架,实现文件上传(upload)?
文件上传功能在nodejs初期是一件很难实现的功能,之后出现了formidable勉强能解决这个问题,但是express框架出现之后基于这个框架开发的中间件有更好的方法来处理文件上传,这个中间件就是m ...