【论文阅读】ConvNeXt:A ConvNet for the 2020s 新时代卷积网络
一、ConvNext Highlight
核心宗旨:基于ResNet-50的结构,参考Swin-Transformer的思想进行现代化改造,知道卷机模型超过trans-based方法的SOTA效果。
启发性结论:架构的优劣差异没有想象中的大,在同样的FLOPs下,不同的模型的性能是接近的。
意义:这篇文章可以作为很好的索引,将一些从卷积网络演进过程中的重要成果收录,适合新手。
二、背景介绍(Related Work)
2.1 一句话回顾ResNet-50
由48层卷积 + 1个maxpool + 1个 avgpool构成。1 个early downsampling的stem + 4个block,每个block的配比是3:4:6:3

2.2 Trans-based?为什么好?
- 为什么Transformer强:归纳偏置小,A Survey of Transformers
- CNN的先验:局部相关性、全局共享性
- RNN的先验:时间依赖
- Trans的先验:只有position、先验小、模型上线高 大数据下表现更好 -> 小数据下只能增加正则项 / 引入结构偏置
- 这么好,为啥前几年在NLP里用,CV领域从20年才开始用
- Trans模型的核心计算在自注意力机制,平方复杂度
- 在NLP领域把 字/词作为最小力度单元,在图像上使用像素作为最小力度单元? -> 复杂度高、单像素信息含量太小
2.3 Trans-based这么好 要怎么用到CV(ViT Swin-T)
- 一个Naive的想法:不把像素当做最小单元,把图像拆成若干小块(称作patch),把小块视作基本单元?
- 上面Naive的想法真的可行!把小patch串起来变成embedding->ViT
- ViT的两个理解视角:
- DNN的视角:把图像切割img2patch,再把patch通过仿射变换 patch2embedding
- CNN的视角:先通过全图的二维卷积(stride = kenerl size),再flatten the feature map
- 更多细节:position embedding可学习, + classification head + 无trans decoder

- 不引入先验的确让模型理论上限更高了,但学习难度也加大了,而且 O(n2)的复杂度还是很难顶 -> Swin-Transformer
- Swin-T核心:采用层次化的设计,将复杂度从O(n^2)降到了O(n)、引入了CNN的局部性先验

三、Convnext又做了哪些事
3.1 超级详尽的实验 和 模型改造
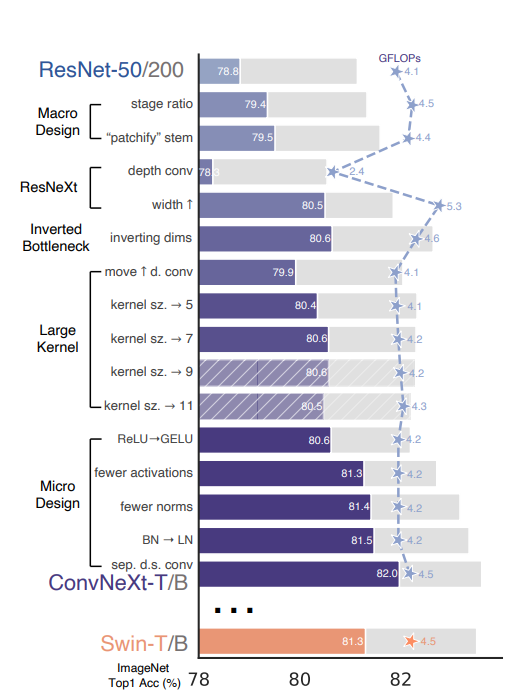
3.2 在实验之前,先在小数据集上获得好的优化器参数
- AdamW, 300epoch,预训练学习率4e-3,weight decay= 0.05,batchsize = 4096;微调学习率 5e-5, weight decay= 1e-8 ,batchsize = 512
- 准确率直接从76.1升到了78.8
3.3 宏观设计
- 修改区块占比:将[3,4,6,3]的区块比例改为了[3,3,9,3] -> 79.4
- RegNet和EfficientNetV2论文中都指出,后面的stages应该占用更多的计算量。
- patchy化:将底层的7*7卷积替换成了4*4 stride=4的卷积,相当于进行原图上的分块 ->79.5
- 深度可分离卷积:参考ResNext的结论,将普通卷积替换成深度可分离卷积(群卷积的一种),参数量降低可以让channel提高到96,达到与Swin-T相同。
- ResNext的指导性建议:use more groups, expand width

- inverted bottleneck:引入了mobilenetV2中的结构,并且探索了更好的setting -> 80.6

- 为了尝试不同的kernel size,调整了卷积的位置(这使得FLOPS降低、精度发生了降低),调整后的结构如figure3-(c)
- 这样调整之后可以实验不同kernel size。Swin-T的窗口是7*7,ConvNext也发现7*7最好
3.4 微观设计
- 更换激活:ReLU替换为GeLU(+0.1)
- 减少激活的数量(+0.7)、减少batchnorm(+0.1),整体设置与Swin-T相同
- 为了跟Swin-T一致,在block开始添加1*1卷积(无效)
- 更换归一化:用LayerNorm替换BatchNorm(+0.1)
- 更换下采样:下采样从 3*3 stride=2,代替为2*2 stride=2(可分离下采样)-> 训练不收敛
- 在stem之后,每个下采样层之前以及global avg pooling之后都增加一个LayerNom (+0.5)

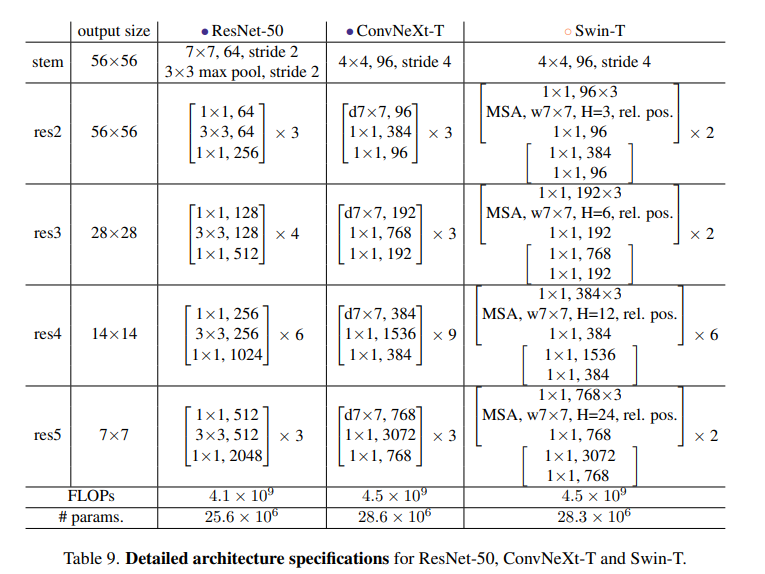
3.4 最终的模型
四、实验结论
五、碎碎念
最近我们有一篇工作也是设计了一个全卷积的网络,也是用了深度可分离、inverted bottleneck、LN代替BN,但远远没有这篇论文做得细致。实验过程中遇到的难收敛问题或许是更值得探索的内容,可惜志不在此,希望学弟能够更细致得探索吧。
【论文阅读】ConvNeXt:A ConvNet for the 2020s 新时代卷积网络的更多相关文章
- CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
前言 本文深入探讨了如何设计神经网络.如何使得训练神经网络具有更加优异的效果,以及思考网络设计的物理意义. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘 ...
- 论文阅读(XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification )
目录 XiangBai--[PAMI2018]ASTER_An Attentional Scene Text Recognizer with Flexible Rectification 作者和论文 ...
- Action4D:人群和杂物中的在线动作识别:CVPR209论文阅读
Action4D:人群和杂物中的在线动作识别:CVPR209论文阅读 Action4D: Online Action Recognition in the Crowd and Clutter 论文链接 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记(一)FCN
本文先对FCN的会议论文进行了粗略的翻译,使读者能够对论文的结构有个大概的了解(包括解决的问题是什么,提出了哪些方案,得到了什么结果).然后,给出了几篇博文的连接,对文中未铺开解释的或不易理解的内容作 ...
随机推荐
- python3 爬虫 Scrapy库学习1
1生成项目:生成项目文件夹 scrapy startproject 项目名 2生成爬虫文件 scrapy genspider 爬虫名 指定域名 3进入items文件可以输入自己想要爬取的内容比如 te ...
- 使用过滤器获取系统目录或文件名(java.io)
import java.io.File;import java.io.FilenameFilter; File[] file = new File("D:\\"); //使用Fil ...
- Jenkins+Docker+Git 自动化部署
Jenkins+Docker+Git 自动化部署图文教程 https://blog.csdn.net/qq_38252039/article/details/89791247 前言: 通过几天的学习和 ...
- Struts2的功能扩展点有哪些?
l Interceptor及其相关子类 l TypeConverter及其相关子类 l Validator及其相关子类 l Result及其相关子类 l ObjectFactory及其相关子类
- idea使用maven工程创建web项目并支持jsp
主要要再pom文件里面添加依赖: <!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api --> & ...
- Idea中使用Lombok 编译报找不到符号
1.问题描述 项目中使用了lombok,但是在idea编译过程是出现找不到符号.报错如下图所示: file @Data @ApiModel(value = "HeadTeacherVO& ...
- memcached 最大的优势是什么?
Memcached 最大的好处就是它带来了极佳的水平可扩展性,特别是在一个巨大的 系统中.由于客户端自己做了一次哈希,那么我们很容易增加大量 memcached 到集群中.memcached 之间没有 ...
- RabbitMQ踩坑记
之前我们给我们的系统加了一个使用SpringAOP+RabbitMQ+WebSocket进行实时消息通知功能(https://www.cnblogs.com/little-sheep/p/993488 ...
- vue2与vue3的区别
template <template> <div class="wrap"> <div>{{ num }}</div> <Bu ...
- poj_3253_priority queue
描述 农夫约翰想要修篱墙,他需要N块木板,第i块板长Li.然后他买了一块很长的板子,足够他分成N块.忽略每次锯板子带来的损失. 约翰忘记买锯子了,于是像Don借.Don要收费,每次锯一下,就要收一次板 ...