曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位?
如何计算,一对key/value应该放在哪个哈希桶
大家都知道,hashmap底层是数组+链表(不讨论红黑树的情况),其中,这个数组,我们一般叫做哈希桶,大家如果去看jdk的源码,会发现里面有一些变量,叫做bin,这个bin,就是桶的意思,结合语境,就是哈希桶。
这里举个例子,假设一个hashmap的数组长度为4(0000 0100),那么该hashmap就有4个哈希桶,分别为bucket[0]、bucket[1]、bucket[2]、bucket[3]。
现在有两个node,hashcode分别是1(0000 0001),5(0000 0101). 我们当然知道,这两个node,都应该放入第一个桶,毕竟1 mod 4,5 mod 4的结果,都是1。
但是,在代码里,可不是用取模的方法来计算的,而是使用下面的方式:
int entryNodeIndex = (tableLength - 1) & hash;
应该说,在tableLength的值,为2的n次幂的时候,两者是等价的,但是因为位运算的效率更高,因此,代码一般都使用位运算,替代取模运算。
下面我们看看具体怎么计算:
此处,tableLength即为哈希表的长度,此处为4. 4 - 1为3,3的二进制表示为:
0000 0011
那么,和我们的1(0000 0001)相与:
0000 0001 -------- 1
0000 0011 -------- 3(tableLength - 1)
相与(同为1,则为1;否则为0)
0000 0001 -------- 1
结果为1,所以,应该放在第1个哈希桶,即数组下标为1的node。
接下来,看看5这个hashcode的节点要放在什么位置,是怎么计算:
0000 0101 -------- 5
0000 0011 -------- 3(tableLength - 1)
相与(同为1,则为1;否则为0)后结果:
0000 0001 -------- 1
扩容时,是怎么对一个hash桶进行transfer的
此处,具体的整个transfer的细节,我们本讲不会涉及太多,不过,大体的逻辑,我们可以来想一想。
以前面为例,哈希表一共4个桶,其中bucket[1]里面,存放了两个元素,假设是a、b,其hashcode分别是1,5.
现在,假设我们要扩容,一般来说,扩容的时候,都是新建一个bucket数组,其容量为旧表的一倍,这里旧表为4,那新表就是8.
那,新表建立起来了,旧表里的元素,就得搬到新表里面去,等所有元素都搬到新表了,就会把新表和旧表的指针交换。如下:
java.util.concurrent.ConcurrentHashMap#transfer
private transient volatile Node<K,V>[] nextTable;
transient volatile Node<K,V>[] table;
if (finishing) {
// 1
nextTable = null;
// 2
table = nextTab;
// 3
sizeCtl = (tabLength << 1) - (tabLength >>> 1);
return;
}
1处,将field:nextTable(也就是新表)设为null,扩容完了,这个field就会设为null
2处,将局部变量nextTab,赋值给table,这个局部变量nextTab里,就是当前已经扩容完毕的新表
3处,修改表的sizeCtl为:假设此处tabLength为4,tabLength << 1 左移1位,就是8;tabLength >>> 1,右移一位,就是2,。8 - 2 = 6,正好就等于 8(新表容量) * 0.75。
所以,这里的sizeCtl就是,新表容量 * 负载因子,超过这个容量,基本就会触发扩容。
ok,接着说,我们要怎么从旧表往新表搬呢? 那以前面的bucket[1]举例,遍历这个链表,计算各个node,应该放到新表的什么位置,不就完了吗?是的,理论上这么写就完事了。
但是,我们会怎么写呢?
用hashcode对新bucket数组的长度取余吗?
jdk对效率的追求那么高,肯定不会这么写的,我们看看,它怎么写的:
java.util.concurrent.ConcurrentHashMap#transfer
// 1
for (Node<K,V> p = entryNode; p != null; p = p.next) {
// 2
int ph = p.hash;
K pk = p.key;
V pv = p.val;
// 3
if ((ph & tabLength) == 0){
lowEntryNode = new Node<K,V>(ph, pk, pv, lowEntryNode);
}
else{
highEntryNode = new Node<K,V>(ph, pk, pv, highEntryNode);
}
}
1处,即遍历旧的哈希表的某个哈希桶,假设就是遍历前面的bucket[1],里面有a/b两个元素,hashcode分别为1,5那个。
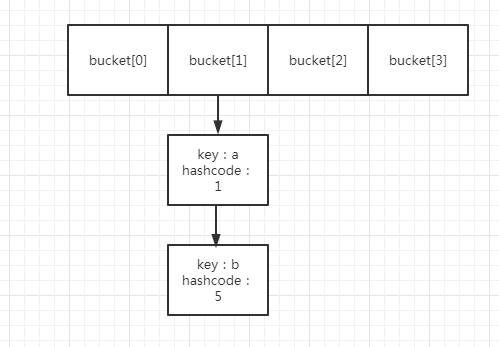
2处,获取该节点的hashcode,此处分别为1,5
3处,如果hashcode 和 旧表长度相与,结果为0,则,将该节点使用头插法,插入新表的低位;如果结果不为0,则放入高位。
ok,什么是高位,什么是低位。扩容后,新的bucket数组,长度为8,那么,前面bucket[1]中的两个元素,将分别放入bucket[1]和bucket[5].
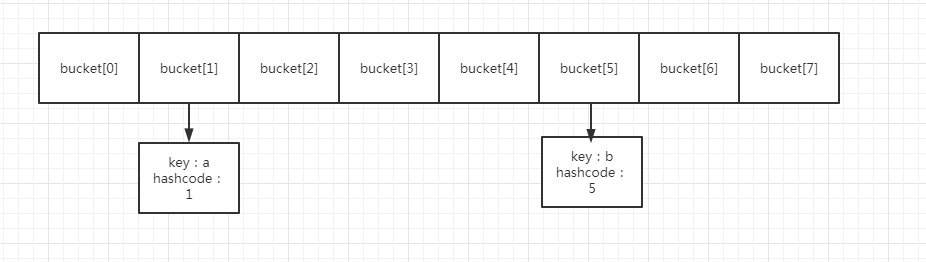
ok,这里的bucket[1]就是低位,bucket[5]为高位。
首先,大家要知道,hashmap中,容量总是2的n次方,请牢牢记住这句话。
为什么要这么做?你想想,这样是不是扩容很方便?
以前,hashcode 为1,5的,都在bucket[1];而现在,扩容为8后,hashcode为1的,还是在newbucket[1],hashcode为5的,则在newbucket[5];这样的话,是不是有一半的元素,根本不用动?
这就是我觉得的,最大的好处;另外呢,运算也比较方便,都可以使用位运算代替,效率更高。
好的,那我们现在问题来了,下面这句的原理是什么?
if ((ph & tabLength) == 0){
lowEntryNode = new Node<K,V>(ph, pk, pv, lowEntryNode);
} else{
highEntryNode = new Node<K,V>(ph, pk, pv, highEntryNode);
}
为啥,hashcode & 旧哈希表的容量, 结果为0的,扩容后,就会在低位,也就是维持位置不变呢?而结果不为0的,扩容后,位置在高位呢?
背后的位运算原理(大白话)
代码里用的如下判断,满足这个条件,去低位;否则,去高位。
if ((ph & tabLength) == 0)
还是用前面的例子,假设当前元素为a,hashcode为1,和哈希桶大小4,去进行与运算。
0000 0001 ---- 1
0000 0100 ---- 旧哈希表容量4
&运算(同为1则为1,否则为0)
结果:
0000 0000 ---- 结果为0
ok,这里算出来,结果为0;什么情况下,结果会为0呢?
那我们现在开始倒推,什么样的数,和 0000 0100 相与,结果会为0?
???? ???? ----
0000 0100 ---- 旧哈希表容量
&运算(同为1则为1,否则为0)
结果:
0000 0000 ---- 结果为0
因为与运算的规则是,同为1,则为1;否则都为0。那么,我们这个例子里,旧哈希表容量为 0000 0100,假设表示为2的n次方,此处n为2,我们仅有第三位(第n+1)为1,那如果对方这一位为0,那结果中的这一位,就会为0,那么,整个数,就为0.
所以,我们的结论是:假设哈希表容量,为2的n次方,表示为二进制后,第n+1位为1;那么,只要我们节点的hashcode,在第n+1位上为0,则最终结果是0.
反之,如果我们节点的hashcode,在第n+1位为1,则最终结果不会是0.
比如,hashcode为5的时候,会是什么样子?
0000 0101 ---- 5
0000 0100 ---- 旧哈希表容量
&运算(同为1则为1,否则为0)
结果:
0000 0100 ---- 结果为4
此时,5这个hashcode,在第n+1位上为1,所以结果不为0。
至此,我们离答案好像还很远。ok,不慌,继续。
假设现在扩容了,新bucket数组,长度为8.
a元素,hashcode依然是1,a元素应该放到新bucket数组的哪个bucket里呢?
我们用前面说的这个算法来计算:
int entryNodeIndex = (tableLength - 1) & hash;
0000 0001 ---- 1
0000 0111 ---- 8 - 1 = 7
&运算(同为1则为1,否则为0)
结果:
0000 0001 ---- 结果为1
结果没错,确实应该放到新bucket[1],但怎么推论出来呢?
// 1
if ((ph & tabLength) == 0){
// 2
lowEntryNode = new Node<K,V>(ph, pk, pv, lowEntryNode);
}
也就是说,假设一个数,满足1处的条件:(ph & tabLength) == 0,那怎么推论出2呢,即应该在低位呢?
ok,条件1,前面分析了,可以得出:
这个数,第n+1位为0.
接下来,看看数组长度 - 1这个数。
| 数组长度 | 2的n次方 | 二进制表示 | 1出现的位置 | 数组长度-1 | 数组长度-1的二进制 |
|---|---|---|---|---|---|
| 2 | 2的1次方 | 0000 0010 | 第2位 | 1 | 0000 0001 |
| 4 | 2的2次方 | 0000 0100 | 第3位 | 3 | 0000 0011 |
| 8 | 2的3次方 | 0000 1000 | 第4位 | 7 | 0000 0111 |
好了,两个数都有了,
???????0??????? -- 1 节点的hashcode,第n + 1位为0,此处n为2
000000010000000 -- 2 老数组
000000100000000 -- 3 新数组的长度,等于老数组长度 * 2
000000011111111 -- 4 新数组的长度 - 1
运算:1和4相与

大家注意看红字部分,还有框出来的那一列,这一列为0,导致,最终结果,肯定是比2那一行的数字小,2这行,不就是老数组的长度吗,那你比老数组小;你比这一行小,在新数组里,就只能在低位了。
反之,如果节点的hashcode,这一位为1,那么,最终结果,至少是大于等于2这一行的数字,所以,会放在高位。
参考资料
https://www.jianshu.com/p/2829fe36a8dd
曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位?的更多相关文章
- 曹工说JDK源码(4)--抄了一小段ConcurrentHashMap的代码,我解决了部分场景下的Redis缓存雪崩问题
曹工说JDK源码(1)--ConcurrentHashMap,扩容前大家同在一个哈希桶,为啥扩容后,你去新数组的高位,我只能去低位? 曹工说JDK源码(2)--ConcurrentHashMap的多线 ...
- 曹工说JDK源码(3)--ConcurrentHashMap,Hash算法优化、位运算揭秘
hashcode,有点讲究 什么是好的hashcode,一般来说,一个hashcode,一般用int来表示,32位. 下面两个hashcode,大家觉得怎么样? 0111 1111 1111 1111 ...
- 曹工说JDK源码(2)--ConcurrentHashMap的多线程扩容,说白了,就是分段取任务
前言 先预先说明,我这边jdk的代码版本为1.8.0_11,同时,因为我直接在本地jdk源码上进行了部分修改.调试,所以,导致大家看到的我这边贴的代码,和大家的不太一样. 不过,我对源码进行修改.重构 ...
- 曹工说Redis源码(2)-- redis server 启动过程解析及简单c语言基础知识补充
文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis,而怎么才能懂,光看是不够的,建议跟着下面的这一篇,把环境搭建起来,后续可以自己阅读源码,或者跟着我这边一起阅读.由于 ...
- 曹工说Redis源码(3)-- redis server 启动过程完整解析(中)
文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis,而怎么才能懂,光看是不够的,建议跟着下面的这一篇,把环境搭建起来,后续可以自己阅读源码,或者跟着我这边一起阅读.由于 ...
- 曹工说Redis源码(4)-- 通过redis server源码来理解 listen 函数中的 backlog 参数
文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis,而怎么才能懂,光看是不够的,建议跟着下面的这一篇,把环境搭建起来,后续可以自己阅读源码,或者跟着我这边一起阅读.由于 ...
- 曹工说Redis源码(5)-- redis server 启动过程解析,以及EventLoop每次处理事件前的前置工作解析(下)
曹工说Redis源码(5)-- redis server 启动过程解析,eventLoop处理事件前的准备工作(下) 文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis ...
- 曹工说Redis源码(6)-- redis server 主循环大体流程解析
文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis,而怎么才能懂,光看是不够的,建议跟着下面的这一篇,把环境搭建起来,后续可以自己阅读源码,或者跟着我这边一起阅读.由于 ...
- 曹工说Redis源码(7)-- redis server 的周期执行任务,到底要做些啥
文章导航 Redis源码系列的初衷,是帮助我们更好地理解Redis,更懂Redis,而怎么才能懂,光看是不够的,建议跟着下面的这一篇,把环境搭建起来,后续可以自己阅读源码,或者跟着我这边一起阅读.由于 ...
随机推荐
- 关于Nginx参数路径问题的问题
本文转载自:https://pureage.info/2013/10/31/130.html 由于工作需要,开始分析nginx的proxy模块,在分析之前,当然要先会用了.于是开始熟悉该模块的一些指令 ...
- 小程序-云开发 bindscroll滚动事件执行setData()方法,导致scroll-view视图抖动
需求描述 想做一个类似京东小程序首页功能列表左右滑动的效果,效果图如下 遇到的问题 1. 如何让scroll-view显示两行 做过小程序开发的都知道,scroll-view要么显示一行,可以左右滚动 ...
- SonarQube搭建手记
前提 这篇文章记录的是SonarQube服务搭建的详细过程,应用于云迁移后的PipleLine的代码扫描环节. 笔者有软件版本升级强迫症,一般喜欢使用软件的最新版本,编写此文的时候(2020-05-1 ...
- JS的函数和对象四
复习 数组 toString/join/concat/slice/splice/reverse/sort/ push/pop/unshift/shift 字符串 new String(2) / S ...
- javaWeb普通类获取ApplicationContext
网上看了很多关于获取ApplicationContext的方法,五大方法,但是我用web服务使用成功的就这一个,自己记忆下. import javax.servlet.ServletContextEv ...
- JavaScript编程入门
写在前面: 不管容易还是简单 总要尝试才知道答案 1.JavaScript初探 JavaScript:轻量级脚本语言,是可插入HTML页面的编程代码. 将JavaScript插入HTML页 ...
- python运用 - log信息提取(知识: 遍历 | os )
运用到的python知识点: excel相关:https://www.cnblogs.com/yaner2018/p/11269873.html 字典: python字典的几种方式: 1)key值遍历 ...
- celery异步消息队列的使用
1.准备工作 1.1 流程图 2.环境安装 2.1.在Ubuntu中需要安装redis 安装redis $sudo apt-get update $sudo apt-get install redis ...
- python爬取页面内容
from selenium import webdriverimport xlwt driver = webdriver.Chrome(r'D:\chromedriver.exe')driver.ma ...
- 附件2:async/await
在实际开发中总会遇到许多异步的问题,最常见的场景便是接口请求之后一定要等一段时间才能得到结果,如果遇到多个接口前后依赖,那么问题就变得复杂.大家都一直在尝试使用更好的方案来解决这些问题.最开始只能利用 ...