关于使用Binlog和canal来对MySQL的数据写入进行监控
先说下Binlog和canal是什么吧。
1、Binlog是mysql数据库的操作日志,当有发生增删改查操作时,就会在data目录下生成一个log文件,形如mysql-bin.000001,mysql-bin.000002等格式
2、canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB);
3、canal起源:早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。
4、基于日志增量订阅&消费支持的业务:
(1)数据库镜像
(2)数据库实时备份
(3)多级索引 (卖家和买家各自分库索引)
(4)search build
(5)业务cache刷新
(6)价格变化等重要业务消息
二、工作原理:
1、mysql主备复制实现:
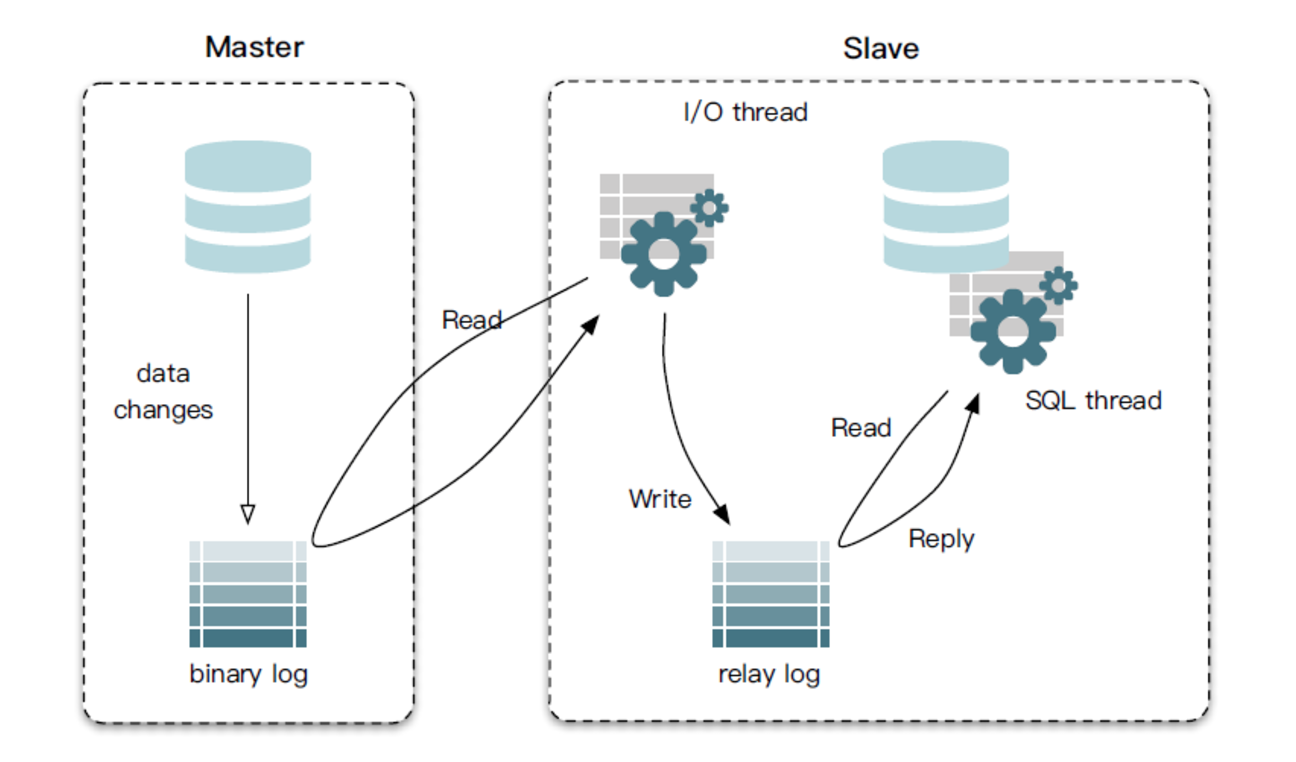
从上层来看,复制分成三步:
(1)master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
(2)slave将master的binary log events拷贝到它的中继日志(relay log);
(3)slave重做中继日志中的事件,将改变反映它自己的数据。
2、canal的工作原理:

原理相对比较简单:
(1)canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
(2)mysql master收到dump请求,开始推送binary log给slave(也就是canal)
(3)canal解析binary log对象(原始为byte流)
三、主要配置:
1、mysql默认是没有开启Binlog,不妨查看下本地mysql是否开启,可执行:
SHOW VARIABLES LIKE 'log_%';
如下图,是我本地mysql,“on”代表已经开启,“off”代表关闭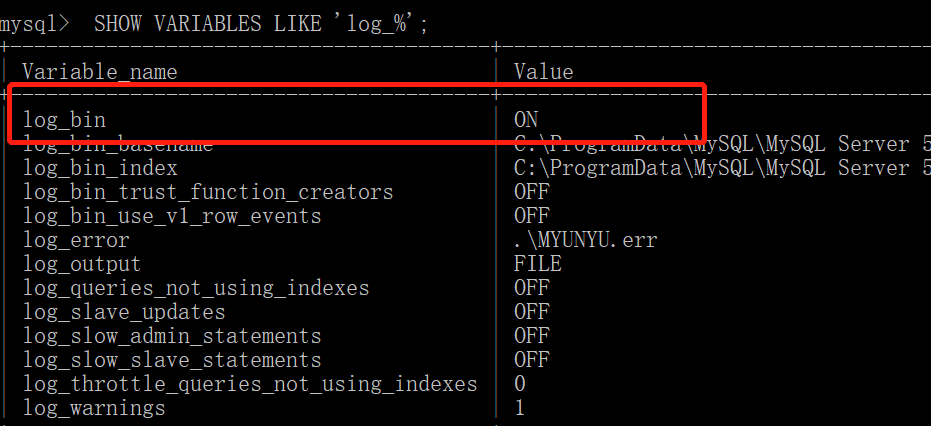
2、如何开启Binlog:
(1)先进入路径为C:\ProgramData\MySQL\MySQL Server 5.6的文件夹下(如果没有,可能是没有将隐藏的文件夹显示),而不是这个路径C:\Program Files\MySQL\MySQL Server 5.6
找到my.ini文件,在打开之前需要先将mysql服务停止,之后在my.ini配置文件中添加以下内容:
#添加这一行就ok
log-bin=mysql-bin
#选择row模式
binlog-format=ROW
#配置mysql replaction需要定义,不能和canal的slaveId重复
server_id=1 #指定生成log的数据库
binlog_do_db=springboot_test1(这是指定需要生成log的数据库,如果删除这句,则表示所有数据库都需要生成log) log-output=FILE
general-log=1 (只需要将0更改为1即可)
general_log_file="MYUNYU.log"
slow-query-log=1
slow_query_log_file="MYUNYU-slow.log"
long_query_time=10
配置好之后,再启动mysql服务,执行查看binlog是否开启,如果还没开启,那就可能是配置出了问题或者mysql版本的问题,这里不详细说
(2)从节点通过一个专门的账号连接主节点,这个账号需要拥有全局的 REPLICATION 权限。我们可以使用GRANT 命令创建这样的账号(需要先选中mysql系统库):
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
再查询mysql系统库中的user表是否存在canal用户:

3、配置canal:
首先先下载canal服务端代码canal.deployer-1.1.1.tar.gz(https://github.com/alibaba/canal/releases),解压之后,配置文件在conf文件夹下,
进入路径为C:\...\canal\canal.deployer-1.1.1\conf\example的文件夹,打开配置文件instance.properties,详细配置如下:
#################################################
## mysql serverId , v1.0.26+ will autoGen
#slaveId不能与my.ini配置文件的server_id一致
canal.instance.mysql.slaveId=1234 # enable gtid use true/false
canal.instance.gtidon=false # position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid= # rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId= # table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/springboot_test1
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid= # username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
#这里配置监控的数据库名
canal.instance.defaultDatabaseName =springboot_test1
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
#################################################
再进入路径为C:\...\canal\canal.deployer-1.1.1\bin的文件夹,双击打开startup.bat,如果显示有以下内容,则表示配置成功,canal服务器端启动ok:

4、客户端代码测试:
(1)首先创建一个空的maven项目,在pom文件中引入canal客户端的依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.0.12</version>
</dependency>
(2)创建一个类进行测试:
package com.xxx; import java.net.InetSocketAddress;
import java.util.List; import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.client.*; public class CanalClient { public static void main(String args[]) {
// 创建链接 instanceA
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEntryCount = 1200;
while (emptyCount < totalEntryCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
}
System.out.println("empty too many times, exit");
}catch (Exception e){
//connector.rollback(batchId); // 处理失败, 回滚数据
}
finally {
connector.disconnect();
}
} private static void printEntry( List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);
} EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList()); } else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
} private static void printColumn( List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
} }
运行CanalClient的main方法,如果看到控制台出现以下内容则代表连接成功:
再到mysql中创建数据库springboot_test,springboot_test1,springboot_test2,再在这三个库中分别创建student表,sql语句为:
CREATE TABLE `student` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`NAME` varchar(20) NOT NULL,
`CLASS_NAME` varchar(30) NOT NULL,
`CREATE_DATE` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`UPDATE_DATE` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`ID`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
执行插入语句:
INSERT INTO student(NAME , class_name )VALUES('student1' , 'class1');
sql执行完之后再看idea中的控制台,如果出现下面内容打印则表示可以监控数据库的写入等操作

到此,使用Binlog和canal来对MySQL的数据写入进行监控的操作实现完毕!
关于使用Binlog和canal来对MySQL的数据写入进行监控的更多相关文章
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- 基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析
Spark Streaming可以用于实时流项目的开发,实时流项目的数据源除了可以来源于日志.文件.网络端口等,常常也有这种需求,那就是实时分析处理MySQL中的增量数据.面对这种需求当然我们可以通过 ...
- Python将MySQL表数据写入excel
背景:将mysql表查询结果写入excel. 1.使用sqlyog工具将查询结果导出到Excel.xml中,用excel打开发现:因为text字段中有回车换行操作,显示结果行是乱的. 2.用mysql ...
- 从mysql读取数据写入mongo
# coding:utf-8 # Created by qinlin.liu at 2017/3/14 import pymysql import datetime #pymongo说明文档 : h ...
- MySql Binlog 说明 & Canal 集成MySql的更新异常说明 & MySql Binlog 常用命令汇总
文章来源于本人的印象笔记,如出现格式问题可访问该链接查看原文 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 目录 背景介绍 开启MySq ...
- 使用canal分析binlog(二) canal源码分析
在能够跑通example后有几个疑问 1. canal的server端对于已经读取的binlog,client已经ack的position,是否持久化,保存在哪里 2. 即使不启动zookeeper, ...
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
- Canal——增量同步MySQL数据到ElasticSearch
1.准备 1.1.组件 JDK:1.8版本及以上: ElasticSearch:6.x版本,目前貌似不支持7.x版本: Kibana:6.x版本: Canal.deployer:1 ...
- 使用Canal作为mysql的数据同步工具
一.Canal介绍 1.应用场景 在前面的统计分析功能中,我们采取了服务调用获取统计数据,这样耦合度高,效率相对较低,目前我采取另一种实现方式,通过实时同步数据库表的方式实现,例如我们要统计每天注册与 ...
随机推荐
- rest framework-分页-长期维护
############### 分页组件 ############### # 分页组件 # # django也有分页,rest framework也有分页,但是没有页面这个概念了, # 这个分页 ...
- python语法基础-文件操作-长期维护
############### python-简单的文件操作 ############### # python中文件的操作 # 文件操作的基本套路 # 1,打开文件,默认是是只读方式打开文件 ...
- 解决一个通过 WebReference 调用 WCF 时自定义 DataContract 类参数提交的问题
先看一下VS2013自动创建默认的IService1.vb,注意自定义的数据契约 CompositeType ' 注意: 使用上下文菜单上的“重命名”命令可以同时更改代码和配置文件中的接口名“ISer ...
- hdu1069 Monkey and Banana LIS
#include<cstdio> #include<iostream> #include<algorithm> #include<queue> #inc ...
- java replaceall 用法:处理特殊字符
public class TryDotRegEx { public static void main(String[] args) { // TODO Auto-generated method st ...
- [LC] 102. Binary Tree Level Order Traversal
Given a binary tree, return the level order traversal of its nodes' values. (ie, from left to right, ...
- 口语、听力:新概念英语2,lesson 45
新概念英语2,lesson 45 练习听力
- Golang Slice 总结
数组 Go的切片是在数组之上的抽象数据类型,因此在了解切片之前必须要要理解数组.数组类型由指定和长度和元素类型定义.数组不需要显式的初始化:数组元素会自动初始化为零值:Go的数组是值语义.一个数组变量 ...
- Hashtable和Hashmap的区别?
1.实现的继承的父类不同 Hashtable继承Dictionary类 HashMap继承abstractMap类 两个类都实现了Map接口 2.线程安全性不同 Hashmap线程是不安全的 H ...
- python3多进程爬虫(第二卷)
上卷中讲到,我有4个进程,可是我要同时爬取20+数据怎么办,很明显上卷的语法公式不可以,所以现在我引入线程池 现在看一下线程池的语法 看一下爬虫: 注意圈中重点