【python爬虫实战】使用Selenium webdriver采集山东招考数据
1、目标
- 目标:按地区、高校 采集2020年拟在山东招生的所有专业信息
- 采集地址:http://xkkm.sdzk.cn/zy-manager-web/gxxx/selectAllDq#
2、Selenium webdriver说明
2.1 为什么使用webdriver
Selenium Webdriver是通过各种浏览器的驱动(web driver)来驱动浏览器的,相遇对于使用requests库直接对网页进行解析,效率较低,本次使用webdriver库主要原因是requests库无法解析该网站
2.2 webdriver支持浏览器
- Google Chrome
- Microsoft Internet Explorer 7,8,9,10,11 for Windows Vista,Windows 7,Windows 8,Windows 8.1.
- Microsoft Edge
- Firefox
- Safari
- Opera
2.3 配置与使用说明
webdriver是通过各浏览器的驱动程序 来操作浏览器的,所以,要有各浏览器的驱动程序,浏览器驱动要与本地浏览器版本对应,常用浏览器驱动下载地址如下:
| 浏览器 | 对应驱动下载地址 |
|---|---|
| chrom(chromedriver.exe) | http://npm.taobao.org/mirrors/chromedriver/ |
| firefox(geckodriver.exe) | https://github.com/mozilla/geckodriver/releases |
| Edge | https://developer.microsoft.com/en-us/micrsosft-edage/tools/webdriver |
| Safari | https://webkit.org/blog/6900/webdriver-support-in-safari-10/ |
本文使用谷歌的chrome浏览器,
chrome + webdriver的具体配置和操作说明见 https://www.cnblogs.com/cbowen/p/13217857.html
3、采集
3.1 分析网站
进入网页发现各省份地址相同、各高校地址相同,因此想按规律构造每个省份和每个学校的url,并用requests进行解析就无法实现了。
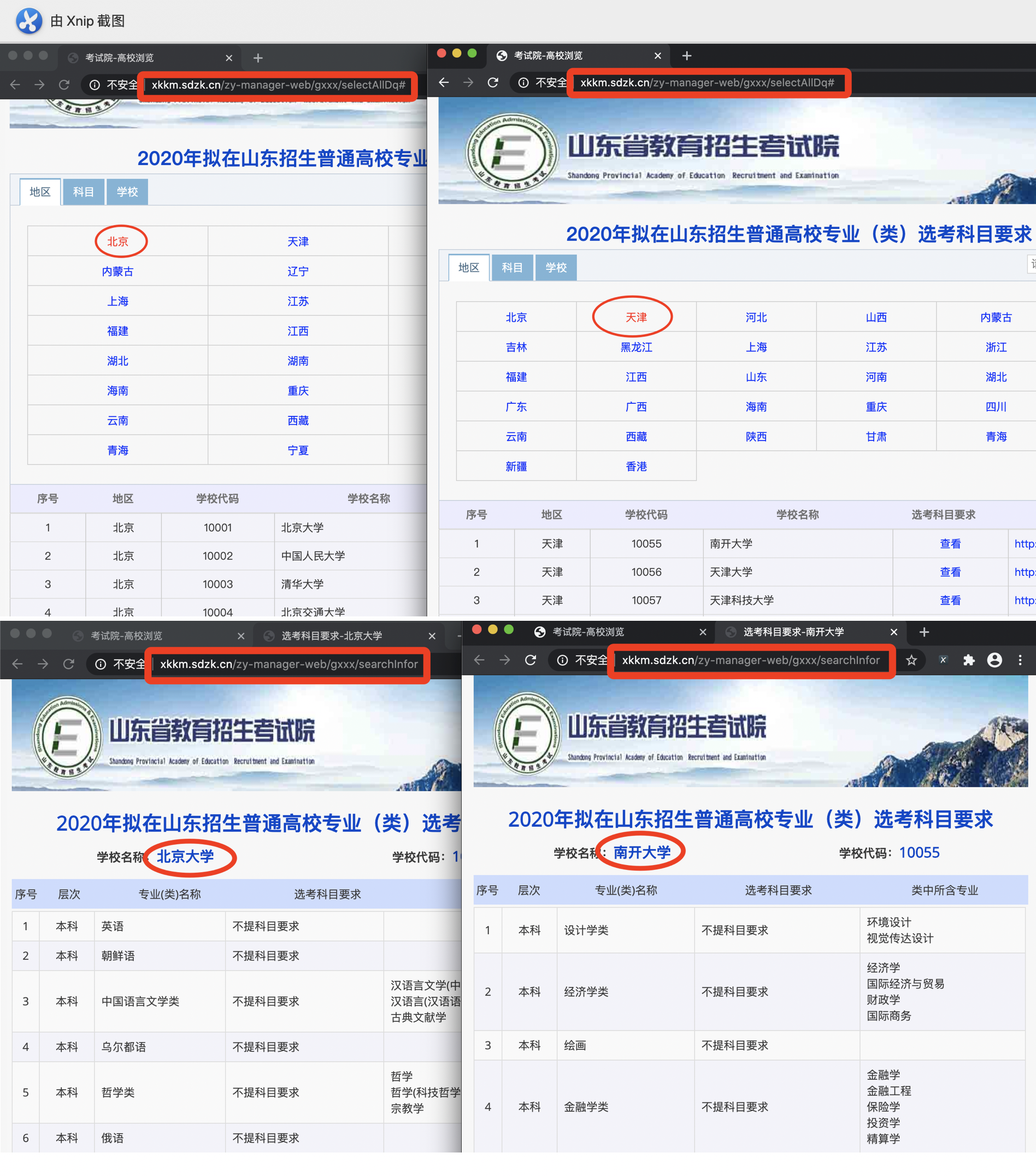
于是想到webdriver,来模拟人工操作,获取当前页面,再通过xpath定位到要获取的数据单元。
先用chrome控制台获取目标数据单元的xpath
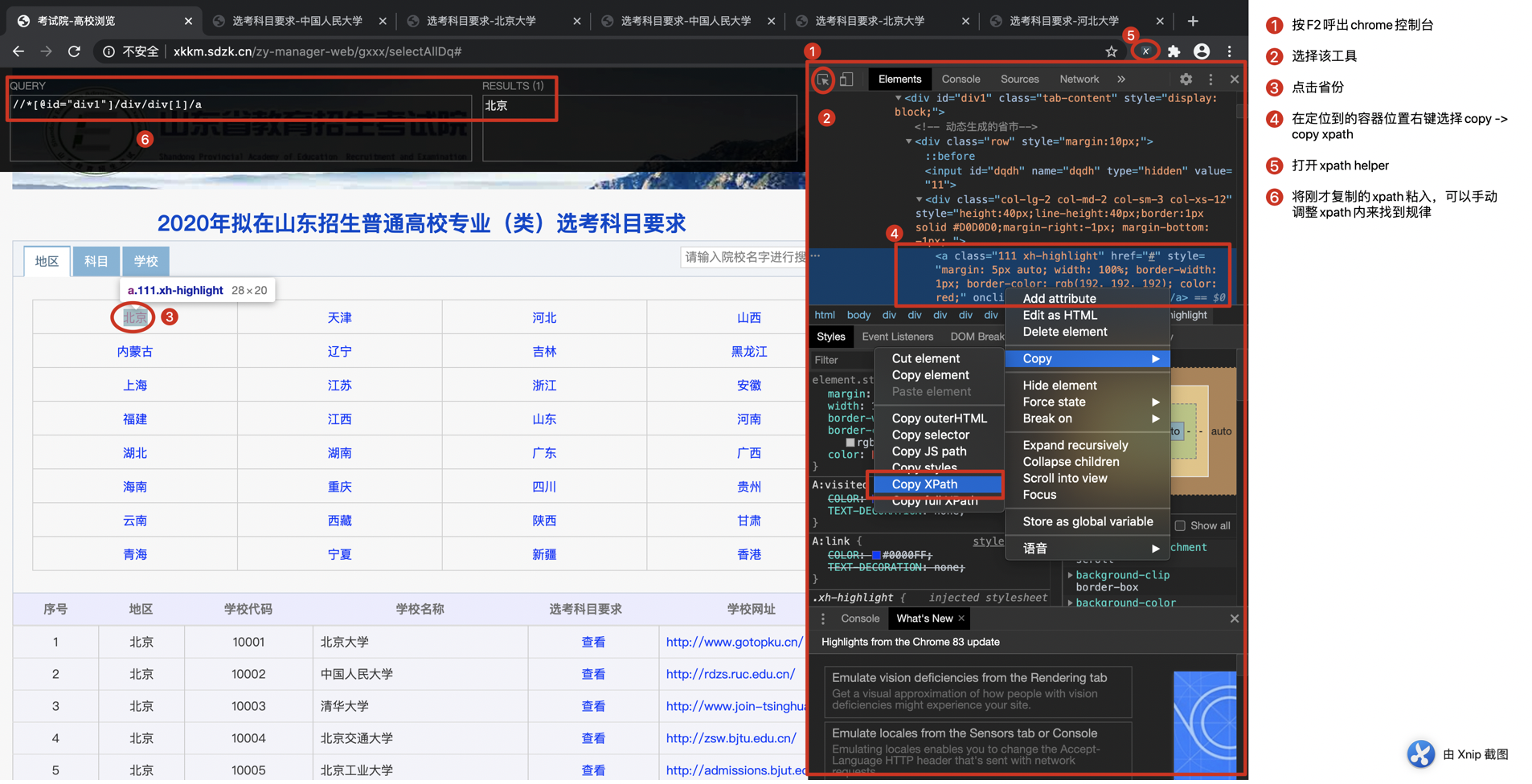
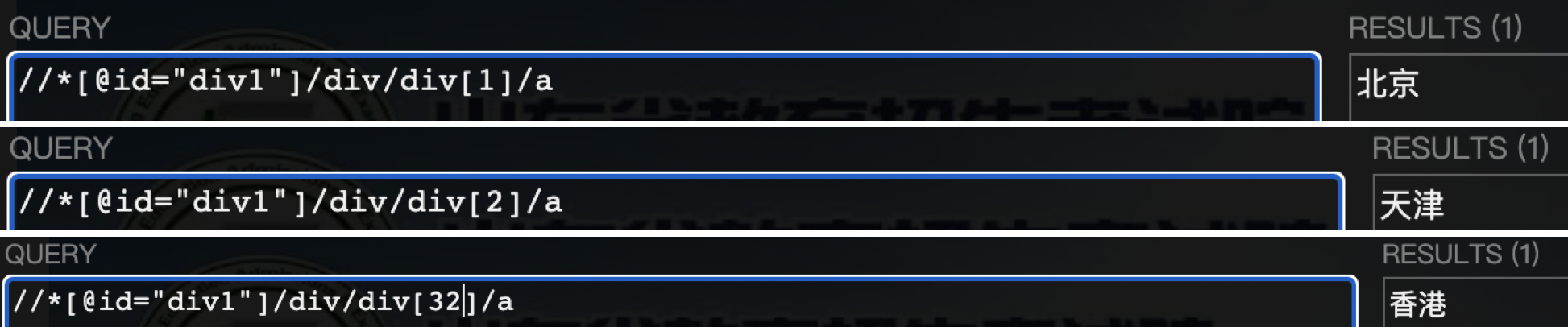
通过手动调整xpath,很容易发现省份xpath的规律为
for province_id in rang(1, 33)
province_xpath = '//*[@id="div1"]/div/div[%s]/a' % province_id
再用同样方法获取高校的xpat,这里就不贴截图了,直接上结果
# sch_id为每个省份的高校id
# schid_xpath,province_xpath,schcode_xpath,school_xpath,subpage_xpath,schhome_xpath分别对应字段序号、地区、学校代码、学校名称、选考科目要求、学校主页
schid_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[1]/a' % school_id
province_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[2]/a' % school_id
schcode_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[3]/a' % school_id
school_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[4]/a' % school_id
subpage_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[5]/a' % school_id
schhome_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[6]/a' % school_id
再用同样方法获取专业信息的xpat,直接上结果
# major_id为每个高校专业序号,从1到最后一个专业序号
# i从1到4分别对应字段“序号”、“层次”、“专业名称”、“选考科目要求”
for i in range(1, 5):
major_xpath = '//*[@id="ccc"]/div/table/tbody/tr[%s]/td[%s]' % (major_id, i)
3.2 遍历省份
- 遍历省份很简单,一共32个省份,直接用rang(1,33),省去用try来判断。
- 在函数外启动浏览器,并传入WebDriver类wd,所有省份遍历完成后关闭浏览器
- 后面要将数据写入mysql,所有传入了完成数据库连接的connect对象conn,并在全部数据写入后关闭conn连接。
def traverse_province(wd, conn):
"""
循环进入省份
:return:
"""
for province_id in range(1, 33):
province_xpath = '//*[@id="div1"]/div/div[%s]/a' % province_id
wd.find_element_by_xpath(province_xpath).click() # 点击进入省份
time.sleep(1)
traverse_school(wd, conn) # 遍历省份内的高校
wd.quit()
conn.close()
3.3 遍历高校
- 用while True循环来遍历当前页所有的高校,用try-except来判断是否成功捕捉高校信息,失败则终端while True循环。
- 获取高校基本信息放列表school_info中,传入下层函数用于冗余保存高校+专业 完整数据。
- 进入高校的子页面后,需要重新定位当前操作页面,wd.window_handles获取当前浏览器所有子页面句柄,wd.switch_to.window切换至指定页面。
- 最内层函数traverse_major()会获取专业数据,并将本层获取的高校数据和专业数据写入mysql。
- 在一个高校的全部专业数据写入完成后,提交一次。
def traverse_school(wd, conn):
"""
遍历高校信息
:return:
"""
school_id = 1
while True:
school_info = []
try:
# 获取高校信息
for i in [1, 2, 3, 4, 6]:
school_xpath = '//*[@id="div4"]/table/tbody/tr[%s]/td[%s]' % (school_id, i)
text = wd.find_element_by_xpath(school_xpath).text
school_info.append(text)
# 进入高校子页
wd.find_element_by_xpath('//*[@id="div4"]/table/tbody/tr[%s]/td[5]/a' % school_id).click()
wd.switch_to.window(wd.window_handles[-1]) # 切换到最后一个页面
traverse_major(school_info, wd, conn) # 遍历专业
wd.close() # 关闭当前页
wd.switch_to.window(wd.window_handles[-1]) # 重新定位一次页面
school_id += 1
except:
break
conn.commit() # 每个高校份提交一次
3.4 采集专业数据
- 将专业信息结合上层函数传入的高校信息冗余保存。
- 每个高校启动一次游标。
- 本函数内仅使操作游标进行数据写入,数据库的连接在下面函数中,数据库关闭在最外层函数中。
def traverse_major(school_info, wd, conn):
"""
遍历专业信息,最后结合高校信息一并输出
:param school_info: 上层函数传递进来的高校信息
:return:
"""
major_id = 1
cursor = conn.cursor()
while True:
major_info = []
try:
for i in range(1, 5):
major_xpath = '//*[@id="ccc"]/div/table/tbody/tr[%s]/td[%s]' % (major_id, i)
text = wd.find_element_by_xpath(major_xpath).text
major_info.append(text)
print(school_info + major_info)
# 写入mysql
insert_sql = '''
insert into sdzk_data
(school_id,province,school_code,school_name,school_home,major_id,cc,major_name,subject_ask)
values('%s','%s','%s','%s','%s','%s','%s','%s','%s')
''' % (school_info[0], school_info[1], school_info[2], school_info[3], school_info[4],
major_info[0], major_info[1], major_info[2], major_info[3])
cursor.execute(insert_sql)
major_id += 1
except:
break
cursor.close() # 每个高校都重新开启一次游标
3.5 写入mysql
- 该函数仅用于创建mysql连接,并创建表。
- 判断表是否存在,存在则先删除再创建。
- 函数返回connect类,用于其他函数使用。
- 关闭连接在最外层函数中,直到所有省份数据采集结束后才关闭连接。
def connect_mysql(config):
"""
连接数据库,并创建表,如果表已存在则先删除
:param config: mysql数据库信息
:return: 返回连接成功的connect对象
"""
create_sql = '''
CREATE table if NOT EXISTS sdzk_data
(school_id int(3),province varchar(20), school_code varchar(5),
school_name varchar(50), school_home varchar(100), major_id int(3),
cc varchar(5), major_name varchar(100), subject_ask varchar(50))
'''
# 判断表是否存在,存在则删除,然后创建
conn = pymysql.connect(**config)
cursor = conn.cursor()
cursor.execute('''show TABLEs like "sdzk_data"''')
if cursor.fetchall():
cursor.execute('''drop table sdzk_data''')
cursor.execute(create_sql)
cursor.close()
return conn
4、源码
源码地址:https://github.com/18686622933/sdzk_data
【python爬虫实战】使用Selenium webdriver采集山东招考数据的更多相关文章
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- [Python爬虫] 之一 : Selenium+Phantomjs动态获取网站数据信息
本人刚才开始学习爬虫,从网上查询资料,写了一个利用Selenium+Phantomjs动态获取网站数据信息的例子,当然首先要安装Selenium+Phantomjs,具体的看 http://www.c ...
- [Python爬虫] 之八:Selenium +phantomjs抓取微博数据
基本思路:在登录状态下,打开首页,利用高级搜索框输入需要查询的条件,点击搜索链接进行搜索.如果数据有多页,每页数据是20条件,读取页数 然后循环页数,对每页数据进行抓取数据. 在实践过程中发现一个问题 ...
- [Python爬虫] 之三:Selenium 调用IEDriverServer 抓取数据
接着上一遍,在用Selenium+phantomjs 抓取数据过程中发现,有时候抓取不到,所以又测试了用Selenium+浏览器驱动的方式:具体代码如下: #coding=utf-8import os ...
- [Python爬虫] 之七:selenium webdriver定位不到元素的五种原因及解决办法(转载)
转载:http://www.51testing.com/html/87/300987-831171.html 1.动态id定位不到元素for example: //WebElement ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- 路飞学城—Python爬虫实战密训班 第二章
路飞学城—Python爬虫实战密训班 第二章 一.Selenium基础 Selenium是一个第三方模块,可以完全模拟用户在浏览器上操作(相当于在浏览器上点点点). 1.安装 - pip instal ...
随机推荐
- java中Condition类的详细介绍(详解)
已找不到原文了,还望原文博主看到能告诉小白一下,一定标注原文地址 一 condition 介绍及demo Condition是在java 1.5中才出现的,它用来替代传统的Object的wait(). ...
- XML基础(转)
一.XML是什么?作用是什么?1.XML是指可扩展标记语言(eXtensible Markup Language),用户自定义的标签.相对于HTML来讲的.2.XML被设计的宗旨是表示数据.HTML是 ...
- https如何进行加密传输
客户端是没有证书的,也就没有公钥和私钥. SSL握手阶段,服务器把证书传输给客户端,同时也就传输了公钥(公钥是证书的一部分). 由客户端来对这个证书进行有效性认可,再由这个客户端来生成对称密钥. 对称 ...
- 5分钟速成Markdown
一.认识 Markdown Markdown 是一种用来写作的轻量级「标记语言」,它用简洁的语法代替排版,而不像一般我们用的字处理软件 Word 或 Pages 有大量的排版.字体设置.它使我们专心于 ...
- Prometheus监控Docker Swarm集群(一)
Prometheus监控Docker Swarm集群(一) cAdvisor简介 为了解决容器的监控问题,Google开发了一款容器监控工具cAdvisor(Container Advisor),它为 ...
- python学习日记2019.9.2
1 定义一个字符串对象str str.title() #将字符串中用空格分隔的字符段首字母大写 str.rstrip() #将字符串末的空格删去 str.strip() #将字符串首末的空格删去 st ...
- HTML新增的语义化标签及其作用
在html5中,新增了几个语义化标签:<article>.<section>.<aside>.<hgroup>. <header>,< ...
- c++无法解析的外部符号 "int const bufferSize
无法解析的外部符号 "int const bufferSize 严重性 代码 说明 项目 文件 行 禁止显示状态错误 LNK2001 无法解析的外部符号 "int const bu ...
- cookie的介绍和使用
一.什么是cookie 是由服务器端生成,发送给客户端(一般指浏览器),浏览器将cookie以键值对的形式保存到某个目录下的文本文件内.下次请求该网站时就把cookie发送回服务器.(cookie就是 ...
- 虹软AI 人脸识别SDK接入 — 参数优化篇
引言 使用了免费的人脸识别算法,感觉还是很不错的,但是初次接触的话会对一些接口的参数有些疑问的.这里分享一下我对一些参数的验证结果(这里以windows版本为例,linux.android基本一样), ...