CMDB_Agent版本
CMDB_Agent版本
CMDB概念
CMDB: Configure Manage DataBase
中文:配置管理数据库。
主要的作用是:收集服务器的基础信息(包括:服务器的主机名,ip,操作系统版本,磁盘,CPU等信息),将来提供给子系统(代码发布,工单系统等)数据
CMDB_Agent介绍

其本质上就是在各个服务器上执行subprocess.getoutput()命令,然后将每台机器上执行的结果,返回给主机API,然后主机API收到这些数据之后,放入到数据库中,最终通过web界面展现给用户
优点:速度快
缺点:需要为每台服务器步数一个Agent的程序
agent方案
将待采集的服务器看成一个agent,然后再服务器上使用python的subprocess模块执行linux相关的命令,然后分析得到的结果,将分析得到的结果通过requests模块发送给API,API获取到数据之后,进行二次比对数据,最后将比对的结果存入到数据库中,最后django起一个webserver从数据库中将数据获取出来,供用户查看
ssh类方案
在中控机服务器上安装一个模块叫paramiko模块,通过这个模块登录到带采集的服务器上,然后执行相关的linux命令,最后返回执行的结果,将分析得到的结果通过requests模块发送给API,API获取到数据之后,进行二次比对数据,最后将比对的结果存入到数据库中,最后django起一个webserver从数据库中将数据获取出来,供用户查看
相比较
agent方案
优点:不需要额外的增加中控机。
缺点:每新增一台服务器,就需要额外部署agent脚本。使用场景是:服务器多的情况 (1000台以上)
ssh方案
优点:不需要额外的部署脚本。
缺点:速度比较慢。使用场景是:服务器少 (1000台往下)
架构目录
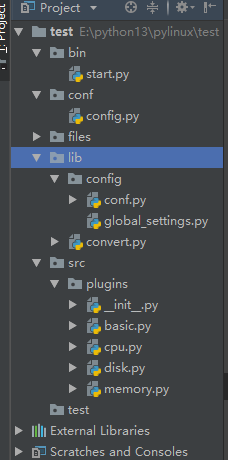
bin-start.py 启动文件
from src.plugins import PluginsManager
if __name__ == '__main__':
res = PluginsManager().execute()
for k, v in res.items():
print(k, v)
conf-config.py 自定义配置文件
模仿Django的setting,常用的配置写在这里面。不常用的写在global_settings.py中。
加载顺寻:先加载全局的。再加载局部的
USER = 'root'
MODE = 'agent'
DEBUG = True # True:代表是开发测试阶段 False:代表是上现阶段
import os
BASEDIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 模仿Django中间件,插拔式
PLUGINS_DICT = {
'basic': 'src.plugins.basic.Basic',
'cpu': 'src.plugins.cpu.Cpu',
#'disk': 'src.plugins.disk.Disk',
'memory': 'src.plugins.memory.Memory',
}
files 开发测试的文件
DEBUT=True时为测试阶段,用files的测试数据
lib-config-global_settings.py 全局配置的文件
pass
lib-config-conf.py 读取配置的文件
全局配置放在前面先加载,自定义配置的放在后面后加载。自定义配置了就用自定义的(覆盖),没有配置久用全局的
from conf import config
from . import global_settings
class mySettings():
def __init__(self):
# print('aa:', dir(global_settings))
# print('bb:', dir(config))
# 全局配置
for k in dir(global_settings):
if k.isupper():
v = getattr(global_settings, k)
setattr(self, k, v)
# 自定义配置
for k in dir(config):
if k.isupper():
v = getattr(config, k)
setattr(self, k, v)
settings = mySettings()
src-plugins-init.py 核心文件
from lib.config.conf import settings
import importlib
class PluginsManager():
def __init__(self):
self.plugins_dict = settings.PLUGINS_DICT
self.debug = settings.DEBUG
# 1.采集数据
def execute(self):
response = {}
for k, v in self.plugins_dict.items():
'''
k: basic
v: src.plugins.basic.Basic
'''
# 2.循环导入(字符串路径)
moudle_path, class_name = v.rsplit('.', 1) # ['src.plugins.basic','Basic']
# 用importlib.import_module()导入字符串路径
m = importlib.import_module(moudle_path)
# 3.导入类
cls = getattr(m, class_name)
# 循环执行鸭子类型的process方法,command_func函数的内存地址传过去,把debug传过去
ret = cls().process(self.command_func, self.debug)
response[k] = ret
return response
# 真正的连接,执行命令,返回结果的函数。命令变成参数
def command_func(self, cmd):
if settings.MODE == 'agent':
import subprocess
res = subprocess.getoutput(cmd)
return res
else:
import paramiko
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不再know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='10.0.0.200', port=22, username='root', password='123456')
# 执行命令
stdin, stdout, stderr = ssh.exec_command(cmd)
# 获取命令结果
result = stdout.read()
# 关闭连接
ssh.close()
return result
src-plugins-basic.py 查看硬件信息
from conf import config
class Basic(object):
def process(self, command_func, debug):
if debug:
output = {
'os_platform': "linux",
'os_version': "CentOS release 6.6 (Final)\nKernel \r on an \m",
'hostname': 'c1.com'
}
else:
output = {
'os_platform': command_func("uname").strip(),
'os_version': command_func("cat /etc/issue").strip().split('\n')[0],
'hostname': command_func("hostname").strip(),
}
return output
src-plugins-cpu.py 查看cpu属性
import os
from lib.config.conf import settings
class Cpu():
def __init__(self):
pass
def process(self, command_func, debug):
if debug:
output = open(os.path.join(settings.BASEDIR, 'files/cpuinfo.out'), 'r', encoding='utf-8').read()
else:
output = command_func("cat /proc/cpuinfo")
return self.parse(output)
def parse(self, content):
"""
解析shell命令返回结果
:param content: shell 命令结果
:return:解析后的结果
"""
response = {'cpu_count': 0, 'cpu_physical_count': 0, 'cpu_model': ''}
cpu_physical_set = set()
content = content.strip()
for item in content.split('\n\n'):
for row_line in item.split('\n'):
key, value = row_line.split(':')
key = key.strip()
if key == 'processor':
response['cpu_count'] += 1
elif key == 'physical id':
cpu_physical_set.add(value)
elif key == 'model name':
if not response['cpu_model']:
response['cpu_model'] = value
response['cpu_physical_count'] = len(cpu_physical_set)
return response
src-plugins-disk.py 查看磁盘信息
# 采集磁盘信息
from lib.config.conf import settings
import os
import re
class Disk(object):
def __init__(self):
pass
def process(self, command_func, debug):
if debug:
output = open(os.path.join(settings.BASEDIR, 'files/disk.out'), 'r', encoding='utf-8').read()
else:
output = command_func('MegaCli -PDList -aALL') # radi 卡 磁盘阵列
return self.parse(output) # 调用过滤的函数
# 过滤函数,对字符串的处理过滤
def parse(self, content):
"""
解析shell命令返回结果
:param content: shell 命令结果
:return:解析后的结果
"""
response = {}
result = []
for row_line in content.split("\n\n\n\n"):
result.append(row_line)
for item in result:
temp_dict = {}
for row in item.split('\n'):
if not row.strip():
continue
if len(row.split(':')) != 2:
continue
key, value = row.split(':')
name = self.mega_patter_match(key)
if name:
if key == 'Raw Size':
raw_size = re.search('(\d+\.\d+)', value.strip())
if raw_size:
temp_dict[name] = raw_size.group()
else:
raw_size = '0'
else:
temp_dict[name] = value.strip()
if temp_dict:
response[temp_dict['slot']] = temp_dict
return response
@staticmethod
def mega_patter_match(needle):
grep_pattern = {'Slot': 'slot', 'Raw Size': 'capacity', 'Inquiry': 'model', 'PD Type': 'pd_type'}
for key, value in grep_pattern.items():
if needle.startswith(key):
return value
return False
CMDB_Agent版本的更多相关文章
- CMDB_Agent_ssh版本分析
目录 CMDB_Agent+ssh版本+server端 CMDB_Agent版本 CMDB概念 CMDB_Agent介绍 agent方案 ssh类方案 相比较 client端 架构目录 bin-sta ...
- Flask 请求中间件、错误处理、标签、过滤器、CBV
目录 一.请求中间件 二.请求中间件额外方法(重写源码) 三.请求错误处理 四.请求标签.过滤器 五.CBV写法 基础版 常用版 一.请求中间件 中间件: 1 before_first_request ...
- 【AR实验室】OpenGL ES绘制相机(OpenGL ES 1.0版本)
0x00 - 前言 之前做一些移动端的AR应用以及目前看到的一些AR应用,基本上都是这样一个套路:手机背景显示现实场景,然后在该背景上进行图形学绘制.至于图形学绘制时,相机外参的解算使用的是V-SLA ...
- ABP入门系列(2)——通过模板创建MAP版本项目
一.从官网创建模板项目 进入官网下载模板项目 依次按下图选择: 输入验证码开始下载 下载提示: 二.启动项目 使用VS2015打开项目,还原Nuget包: 设置以Web结尾的项目,设置为启动项目: 打 ...
- 理解Maven中的SNAPSHOT版本和正式版本
Maven中建立的依赖管理方式基本已成为Java语言依赖管理的事实标准,Maven的替代者Gradle也基本沿用了Maven的依赖管理机制.在Maven依赖管理中,唯一标识一个依赖项是由该依赖项的三个 ...
- MIP 官方发布 v1稳定版本
近期,MIP官方发布了MIP系列文件的全新v1版本,我们建议大家尽快完成升级. 一. 我是开发者,如何升级版本? 对于MIP页面开发者来说,只需替换线上引用的MIP文件为v1版本,就可以完成升级.所有 ...
- 终于等到你:CYQ.Data V5系列 (ORM数据层)最新版本开源了
前言: 不要问我框架为什么从收费授权转到免费开源,人生没有那么多为什么,这些年我开源的东西并不少,虽然这个是最核心的,看淡了就也没什么了. 群里的网友:太平说: 记得一年前你开源另一个项目的时候我就说 ...
- DBImport V3.7版本发布及软件稳定性(自动退出问题)解决过程分享
DBImport V3.7介绍: 1:先上图,再介绍亮点功能: 主要的升级功能为: 1:增加(Truncate Table)清表再插入功能: 清掉再插,可以保证两个库的数据一致,自己很喜欢这个功能. ...
- Windows 7上执行Cake 报错原因是Powershell 版本问题
在Windows 7 SP1 电脑上执行Cake的的例子 http://cakebuild.net/docs/tutorials/getting-started ,运行./Build.ps1 报下面的 ...
随机推荐
- 用Gitolite搭建服务器上的Git
使用git作为版本控制工具,确实非常流行且好用,常用的git代码服务器有Github还是国内的Gitcafe和OSC都是很不错,可以免费存放一些开源的项目代码,对于私人项目,则需要支付一定的费用.同时 ...
- 芮勇博士荣获2016年IEEE 计算机学会技术成就奖
微软亚洲研究院常务副院长 芮勇 日前,电气电子工程师学会(the Institute of Electrical and Electronics Engineers, IEEE)计算机学会(Comp ...
- 启动时查看配置文件application.yml
Spring Boot Application 事件和监听器 在多环境的情况下. 可能需要切换配置文件的一个对应的属性来切换环境 面临的问题就是 如何在springboot加载完配置文件的时候就可以立 ...
- python fake_useragent模块 user-agent的获取
1. UserAgent 模块使用 from fake_useragent import UserAgent ua = UserAgent() # 实例化,实例化时需要联网但是网站不太稳定 print ...
- VirtualBox Ubuntu设置静态ip亲测可行
virtualbox重启后ip会自动分配,不固定.项目中需要配置ip地址,因此每次ip换了,需要重新配置和编译. 网上搜罗好几种方法进行配置,尝试下面这种简单并且可行: 步骤一:查看虚拟机网卡 ifc ...
- GPUImage学习总结
GPUImage是iOS上一个基于OpenGL进行图像处理的开源框架,内置大量滤镜,架构灵活,可以在其基础上很轻松地实现各种图像处理功能. GPUImgae特性 1,丰富的输入组件 摄像头.图片.视频 ...
- 国产数据库适配publiccms开源项目
金仓数据库适配 操作说明: 一.在程序的所有实体层添加schema=”public”(这里的public是根据数据库定义的模式) 二.切换数据库,修改配置文件cms.properties里面的cms. ...
- Java Web环境配置
准备工作 jdk-8u241 apache-tomcat-9.0.31-windows-x64.zip Eclipse IDE for Enterprise Java Developers 关于版本选 ...
- TCP/IP基础总结性学习(6)
HTTP 首部 一. HTTP 报文首部 1.HTTP 报文的结构: 2.HTTP 请求报文 图示: 举例子: 3.HTTP 响应报文: 下面的示例是访问 http://hackr.jp 时,请求报文 ...
- leetcode 209 3 滑动窗口
class Solution { public: int minSubArrayLen(int s, vector<int>& nums) { ,r=-; //由于数组是[]区间, ...