3、Hive-sql优化,数据倾斜处理
一、Hive-sql 常用优化
MapReduce 流程:
Input->split->map->buffer(此处调整其大小)->spill->spill过多合并->merge->combine(减少reduce压力)->shuffle(copy、merge)->spill->disk->reduce->Output

1.1、常用参数设置
#增加reducer任务数量(拉取数量分流)
set mapred.reduce.tasks=20; #在同一个sql中的不同的job是否可以同时运行,默认为false
set hive.exec.parallel=true; #增加同一个sql允许并行任务的最大线程数
set hive.exec.parallel.thread.number=8; #设置reducer内存大小
set mapreduce.reduce.memory.mb=4096;
set mapreduce.reduce.java.opts=-Xmx3584m; -- -Xmx 设置堆的最大空间大小。 #设置执行引擎
set hive.execution.engine=mr; -- 执行MapReduce任务,也可以设置为spark
-- 设置内存大小
set mapreduce.reduce.memory.mb=8192; -- reduce 设置的是 Container 的内存上限,这个参数由 NodeManager 读取并进行控制,当 Container 的内存大小超过了这个参数值,NodeManager 会负责 kill 掉 Container
set mapreduce.reduce.java.opts=-Xmx6144m; -- reduce Java 程序可以使用的最大堆内存数,要小于 mapreduce.reduce.memory.mb
set mapreduce.map.memory.mb=8192; -- map申请内存大小
set mapreduce.map.java.opts=-Xmx6144m; #动态分区设置,参考:https://www.cnblogs.com/cssdongl/p/6831884.html
set hive.exec.dynamic.partition=true; 是开启动态分区
set hive.exec.dynamic.partition.mode=nonstrict; 这个属性默认值是strict,就是要求分区字段必须有一个是静态的分区值,当前设置为nonstrict,那么可以全部动态分区 #其他
-- 开始负载均衡
set hive.groupby.skewindata=true
-- 开启map端combiner
set hive.map.aggr=true
1.2、mapjoin
#mapjoin相关设置,小表加载到内存,无reduce
set hive.mapjoin.smalltable.filesize=25000000; -- 刷入内存表的大小(字节)。注意:设置太大也不会校验,所以要根据自己的数据集调整
set hive.auto.convert.join = true; -- 开启mapjoin,默认false
set hive.mapjoin.followby.gby.localtask.max.memory.usage=0.6 ;--map join做group by操作时,可使用多大的内存来存储数据。若数据太大则不会保存在内存里,默认0.55
set hive.mapjoin.localtask.max.memory.usage=0.90; -- 本地任务可以使用内存的百分比,默认值:0.90
-- 在设置成false时,可以手动的指定mapjoin /*+ MAPJOIN(c) */ 。-->c:放到内存中的表
select /*+ MAPJOIN(c) */ * from user_install_status u
inner join country_dict c
on u.country=c.code
-- 如果不是做innerjoin, 做left join 、right join
-- A left join B, 把B放到内存
-- A right join B, 把A放到内存
1.3、小文件合并
产生原因:
- hive动态分区插入数据,分区数据量小,产生大量的小文件
- reduce数量越多,输出大量小文件
- 数据源本身就就是一些小文件
影响:
- MapReduce原理上理解,小文件会开很多map,一个map开一个JVM去执行,每个任务的初始化、启动、执行,都会消耗资源。
- 在HDFS中,每个小文件对象约占150byte,如果小文件过多会占用大量内存。这样NameNode内存容量限制了集群规模。
解决方案:
在hive里有两种比较常见的处理办法
第一是使用Combinefileinputformat,将多个小文件打包作为一个整体的 inputsplit,减少map任务数
set mapred.max.split.size=256000000; # 每个 Map 最大分割大小
set mapred.min.split.size.per.node=256000000; # 一个节点上 split 的最小值
set Mapred.min.split.size.per.rack=256000000; #一个交换机下 split的最小值
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; #执行 map 前进行小文件的合并
第二是设置hive参数,将额外启动一个MR Job打包小文件
set hive.merge.mapfiles = true; # 是否合并Map输出文件
hive.merge.mapredfiles = false ; #是否合并 Reduce 输出文件,默认为 False
hive.merge.size.per.task = 256*1000*1000;# 合并文件的大小
1.4、JVM 重用
- MapReduce 执行过程中每个任务/task 会启用一个 JVM 来执行 map 和 reduce 任务,这时 JVM 的启动过程可能会造成资源的消耗,如果一个job包含大量的task任务的情况,此优化效果比较明显。通过参数 mapred.job.reuse.jvm.num.tasks 来设置
- 默认情况下,它被设置为 +1,这意味着每个 Map/Reduce 任务都会启动一个新的JVM 。 相反,如果将它设置为 -1,那么可以通过无限数量的任务来使用 jvm 。 在这种情况下,任务连续执行一个,以使用相同的JVM 。
- 为每个task启动一个新的 JVM 将耗时1秒左右,对于运行时间较长(比如1分钟以上)的job影响不大,但如果都是时间很短的task,那么频繁启停JVM会有开销。
- 如果我们想使用JVM重用技术来提高性能,那么可以将mapred.job.reuse.jvm.num.tasks设置成大于1的数。这表示属于同一job的顺序执行的task可以共享一个JVM,也就是说第二轮的map可以重用前一轮的JVM,而不是第一轮结束后关闭JVM,第二轮再启动新的JVM。
- 注意:
- JVM重用技术不是指同一Job的两个或两个以上的task可以同时运行于同一JVM上,而是排队按顺序执行。
- 如果task属于不同的job,那么JVM重用机制无效,不同job的task需要不同的JVM来运行。
1.5、常见 sql 优化
- 减少使用distinct
- 查询条件中减少使用函数
- 避免使用select *
- 多个union all可以使用insert into替换
- 尽量避免一个SQL包含复杂逻辑,可以使用中间表来完成复杂的逻辑
- 减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段
二、数据倾斜
2.1、数据倾斜的表现
- 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
- 单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
2.2、数据倾斜的解决方案
参数调节:
- 对于group by 产生倾斜的问题
- 开启map端combiner:【set hive.map.aggr=true;】
- 开启负载均衡:【set hive.groupby.skewindata=true;】
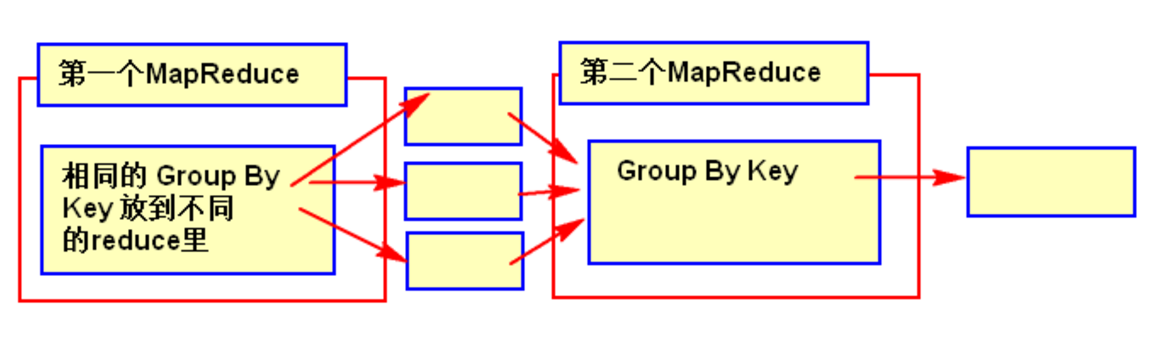
- 有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。
- 第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
- 第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
SQL 语句调节:
- 大小表Join:
- 使用map join让小的维度表先进内存。在map端完成join,不经过reduce。
- 大表Join大表:
- 非法数据太多,比如null,可以把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
- 如果null值不要,可以通过where条件筛选掉;
- 将大量的非法数据转化成随机数+字符串,这样两个表的数据不会join在一起。
- count distinct大量相同特殊值:
- count distinct时,将值为空的情况单独处理
- 如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。
- 如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
- 采用sum group by的方式来替换 count(distinct) 完成计算。
- 空值过多,集中到一个reduce处理--设置随机数(case when a.column is null then concat('test',rand()) else column end = b.column)或过滤。
- 特殊情况特殊处理:
- 在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去
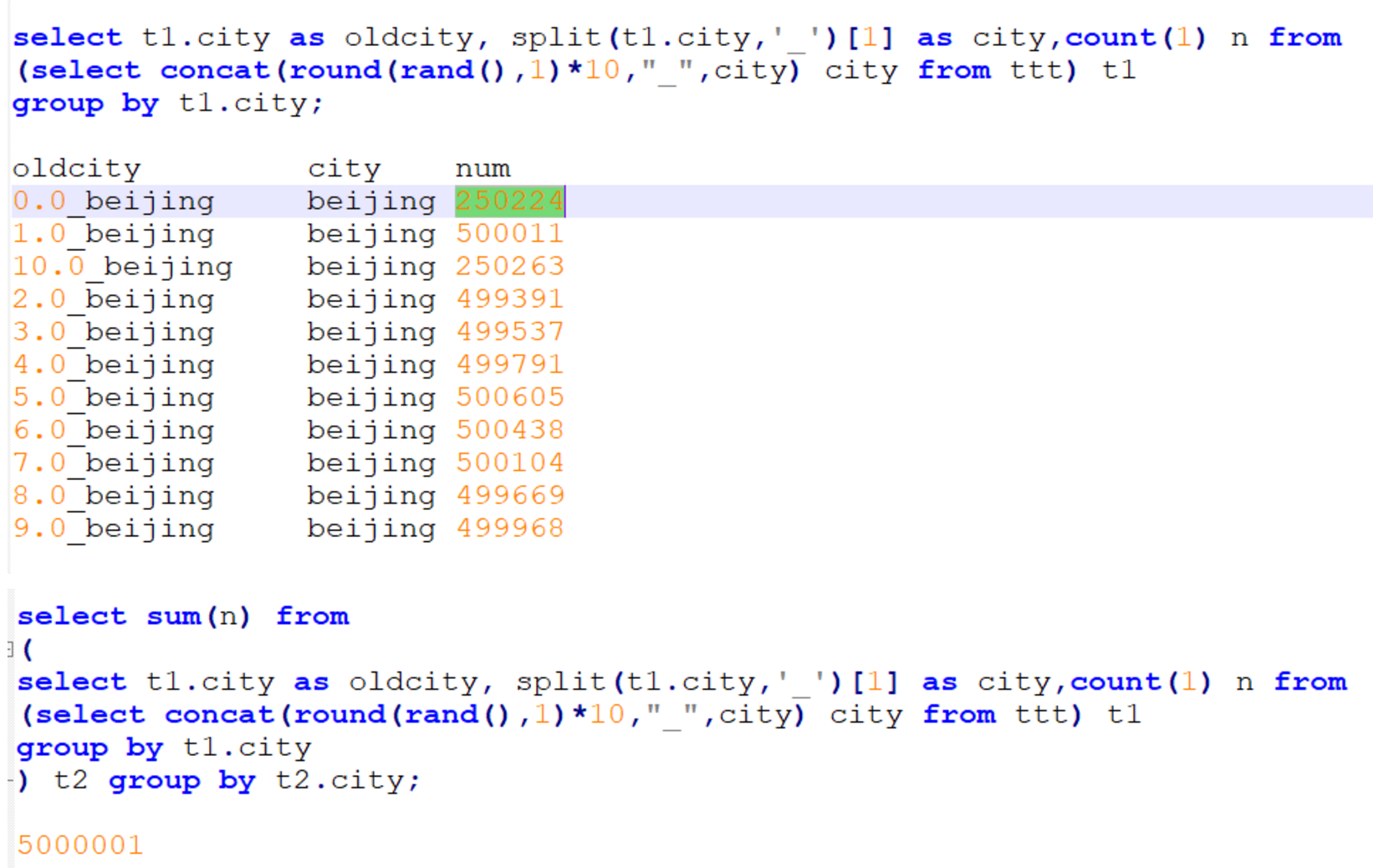
- 比如:group by时维度过小,数据过于集中,数据自身倾斜,比如 北京的用户比其它地方的用户多很多
- 此时可以把北京的数据单独处理:先把北京的数据分成N块,每块的数据进行局部统计,再将每块的局部统计结果进行汇总,最终统计出结果
3、Hive-sql优化,数据倾斜处理的更多相关文章
- Hive中的数据倾斜
Hive中的数据倾斜 hive 1. 什么是数据倾斜 mapreduce中,相同key的value都给一个reduce,如果个别key的数据过多,而其他key的较少,就会出现数据倾斜.通俗的说,就是我 ...
- hive优化-数据倾斜优化
数据倾斜解决方法,通常从以下几个方面进行考量: 业务上丢弃 • 不参与关联:在on条件上直接过滤 • 随机数打散:比如 null.空格.0等“Other”性质的特殊值 倾斜键记录单独处理 • ...
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
一.本课程是怎么样的一门课程(全面介绍) 1.1.课程的背景 作为企业Hadoop应用的核心产品,Hive承载着FaceBook.淘宝等大佬 95%以上的离线统计,很多企业里的离线统 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Hive、Inceptor数据倾斜详解及解决
一.倾斜造成的原因 正常的数据分布理论上都是倾斜的,就是我们所说的20-80原理:80%的财富集中在20%的人手中, 80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量. 俗话是,一 ...
- spark 性能优化 数据倾斜 故障排除
版本:V2.0 第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围 ...
- Hive SQL优化思路
Hive的优化主要分为:配置优化.SQL语句优化.任务优化等方案.其中在开发过程中主要涉及到的可能是SQL优化这块. 优化的核心思想是: 减少数据量(例如分区.列剪裁) 避免数据倾斜(例如加参数.Ke ...
- hive单节点数据倾斜解决方法
一.现象 map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百 ...
- Hive SQL 优化面试题整理
Hive优化目标 在有限的资源下,执行效率更高 常见问题: 数据倾斜 map数设置 reduce数设置 其他 Hive执行 HQL --> Job --> Map/Reduce 执行计划 ...
- hive SQL优化之distribute by和sort by
近期在优化hiveSQL. 以下是一段排序,分组后取每组第一行记录的SQL INSERT OVERWRITE TABLE t_wa_funnel_distinct_temp PARTITION (pt ...
随机推荐
- L20 梯度下降、随机梯度下降和小批量梯度下降
airfoil4755 下载 链接:https://pan.baidu.com/s/1YEtNjJ0_G9eeH6A6vHXhnA 提取码:dwjq 梯度下降 (Boyd & Vandenbe ...
- ATcoder E - Flatten 质因子分解求LCM
题解:其实就是求n个数的lcm,由于数据特别大,求lcm时只能用质因子分解的方法来求. 质因子分解求lcm.对n个数每个数都进行质因子分解,然后用一个数组记录某个质因子出现的最大次数.然后累乘pow( ...
- Project configuration is not up-to-date with pom.xml.错误
完整错误信息:Description Resource Path Location TypeProject configuration is not up-to-date with pom.xml. ...
- HTML学习过程-(1)
记录我HTML的学习 (1) 最开始学习html是在因为在听北京理工大学教授讲的网络公开课上.当时老师讲的是网络爬虫,因为要爬取特定网页的信息,需要借助[正则表达式](https://baike.ba ...
- phpMyAdmin后台文件包含溯源
先上大佬解释的漏洞原理链接 https://mp.weixin.qq.com/s?__biz=MzIzMTc1MjExOQ==&mid=2247485036&idx=1&sn= ...
- SpringMVC数据传递及乱码问题
基础环境搭建请参考SringMVC入门程序 一.SpringMVC数据处理 1:resful 路径传值 http://localhost/get/1/2 /* http://localhost/get ...
- python 中自带的堆模块heapq
import heapq my_heap = [] #使用列表保存数据 #网列表中插入数据,优先级使用插入的内容来表示,就是一个比较大小的操作,越大优先级越高 heapq.heappush(my_he ...
- Java IO 流--FileUtils 工具类封装
IO流的操作写多了,会发现都已一样的套路,为了使用方便我们可以模拟commosIo 封装一下自己的FileUtils 工具类: 1.封装文件拷贝: 文件拷贝需要输入输出流对接,通过输入流读取数据,然后 ...
- QtConcurrent::run() 只能运行参数个数不超过5的函数
有时不得不看源码 qtconcurrentrun.h template <typename T, typename Param1, typename Arg1, typename Param2, ...
- java.util.concurrent简介
文章目录 主要的组件 Executor ExecutorService ScheduledExecutorService Future CountDownLatch CyclicBarrier Sem ...