手把手教你使用Python抓取QQ音乐数据(第二弹)
【一、项目目标】
通过Python爬取QQ音乐数据(一)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名、专辑名、播放链接。
此次我们在之前的基础上获取QQ音乐指定歌曲的歌词及前15个精彩评论。
【二、需要的库】
主要涉及的库有:requests、json、html
【三、项目实现】
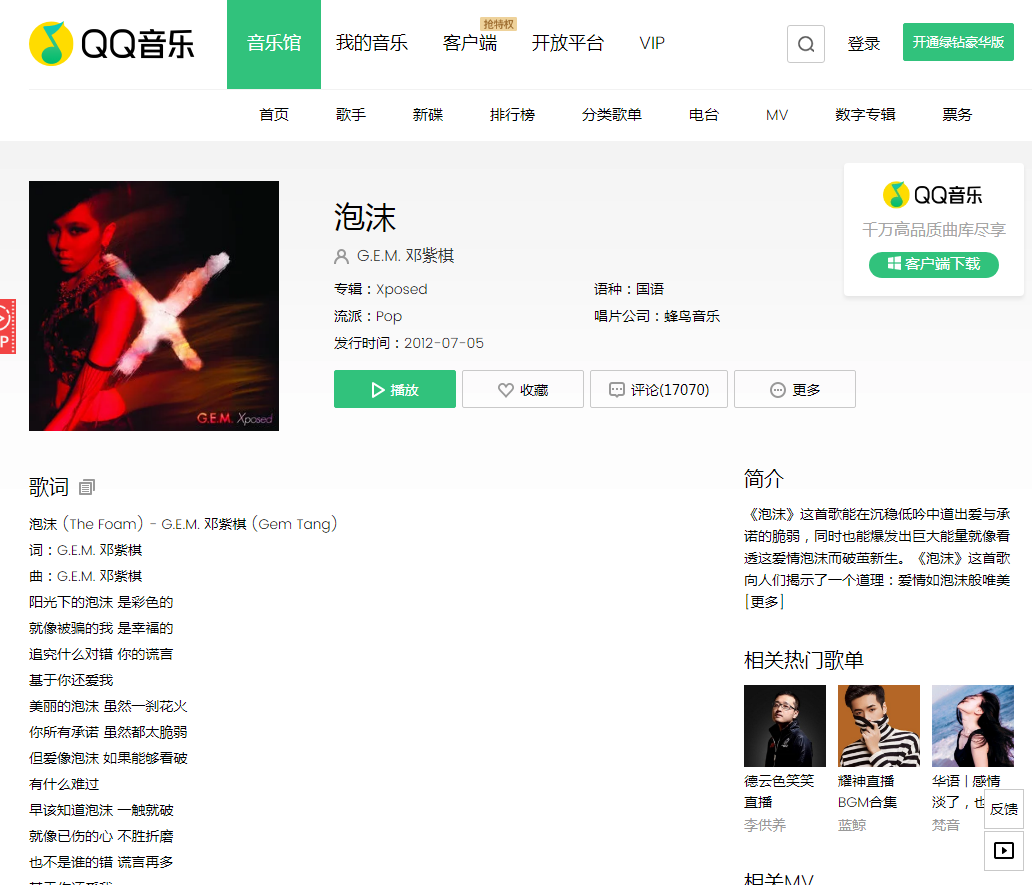
1.以歌曲“泡沫”为例,查看该界面的XHR
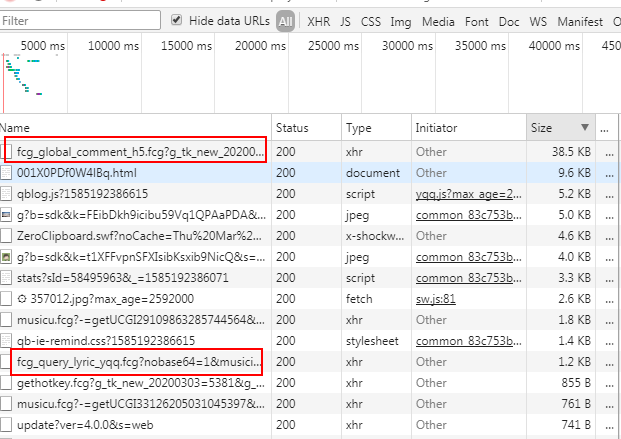
2.通过对XHR的Size进行排序,逐个查看(参考英文含义),我们看到第一个红框内是歌曲评论,第二个框内是歌词!
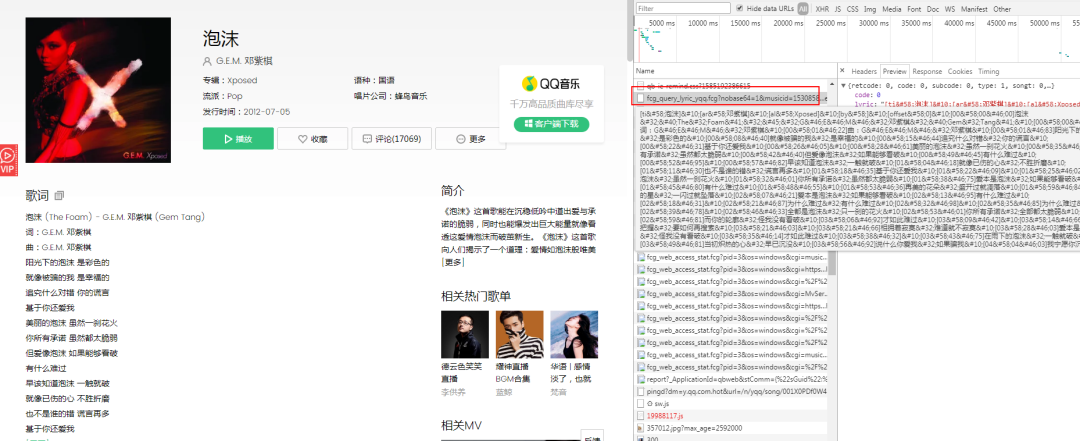
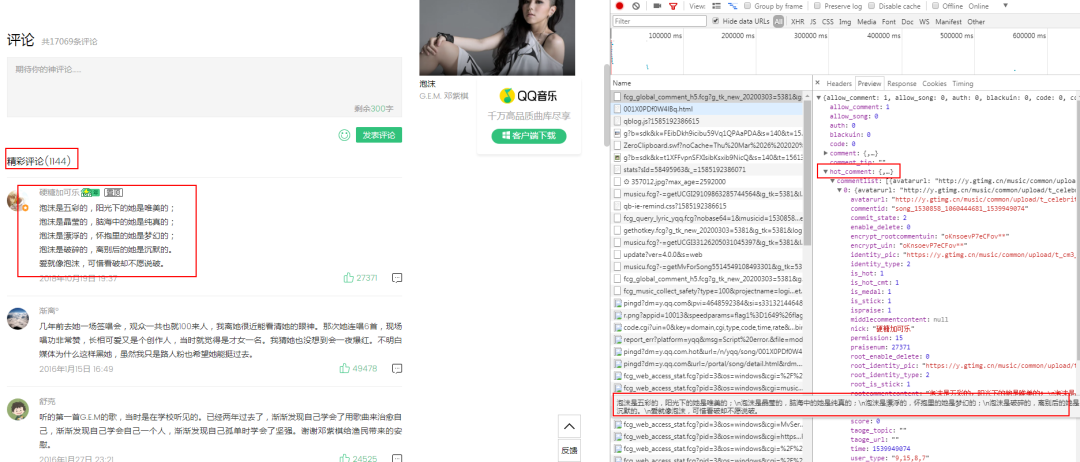
3.分别查看这两条数据Headers里面Parms参数。
4.发现这几个参数可能会代表不同的歌曲,那到底是哪个呢,我们在代开另一首歌对比一下。

5.发现只有这个topid不同,其他都一样,这就代表topid代表不同歌曲的id,同理我们看一下歌词。
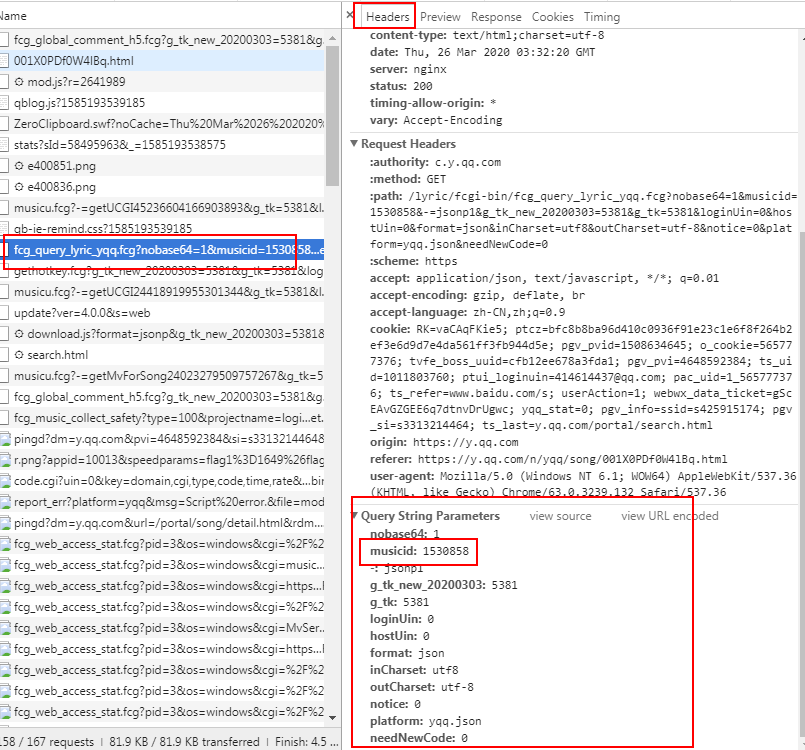
6、确定下来:musicid= topid = 歌曲的id,接下来我们的任务是找到这个id。
7.返回以下界面,也就是我们上一个项目的主战场。
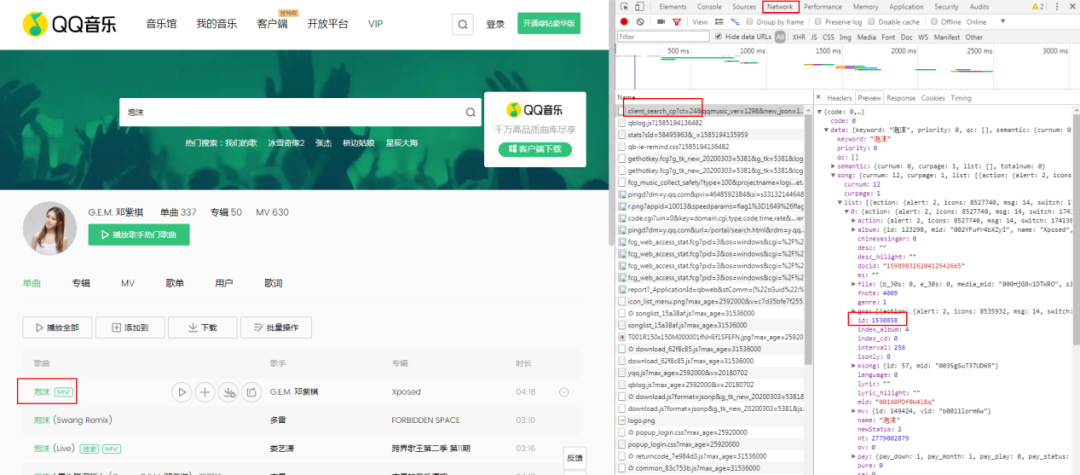
参考上一个项目,很容易找到“id”的值就是我们要寻找的id。
所以思路确定下来:先通过input()输入歌名生成url_1找到该歌曲的“id”参数,再生成url_2获取歌词和评论。
8.代码实现:获取歌曲id,如下所示:
import requests,html,json
url_1 = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
/# 标记了请求从什么设备,什么浏览器上发出
}
i = input('请输入需要查询歌词的歌曲名称:')
params = {'ct': '24', 'qqmusic_ver': '1298', 'new_json': '1', 'remoteplace': 'txt.yqq.song', 'searchid': '71600317520820180', 't': '0', 'aggr': '1', 'cr': '1', 'catZhida': '1', 'lossless': '0', 'flag_qc': '0', 'p': '1', 'n': '10', 'w': i, 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'utf-8', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0'}
res_music = requests.get(url_1,headers=headers,params=params)
/# 发起请求
json_music = res_music.json()
id = json_music['data']['song']['list'][0]['id']
print(id)
9.代码实现:获取歌词
实现方法如下:
url_2 = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
/# 标记了请求从什么设备,什么浏览器上发出
}
params = {
'nobase64':'1',
'musicid':id, /#用上面获取到的id
'-':'jsonp1',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0',
}
res_music = requests.get(url_2,headers=headers,params=params)
/# 发起请求
js = res_music.json()
lyric = js['lyric']
lyric_html = html.unescape(lyric) /#用了转义字符html.unescape方法
/# print(lyric_html)
f1 = open(i+'歌词.txt','a',encoding='utf-8')
f1.writelines(lyric_html)
f1.close() /#存储到txt中
input('下载成功,按回车键退出!')
- 代码实现:获取评论。
url_3 = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
/# 标记了请求从什么设备,什么浏览器上发出
}
params = {'g_tk_new_20200303': '5381', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'GB2312', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0', 'cid': '205360772', 'reqtype': '2', 'biztype': '1', 'topid': id, 'cmd': '8', 'needmusiccrit': '0', 'pagenum': '0', 'pagesize': '25', 'lasthotcommentid': '', 'domain': 'qq.com', 'ct': '24', 'cv': '10101010'}
res_music = requests.get(url_3,headers=headers,params=params)
/# 发起请求
js = res_music.json()
comments = js['hot_comment']['commentlist']
f2 = open(i+'评论.txt','a',encoding='utf-8') /#存储到txt中
for i in comments:
comment = i['rootcommentcontent'] + '\n——————————————————————————————————\n'
f2.writelines(comment)
/# print(comment)
f2.close()
input('下载成功,按回车键退出!')
- 封装函数
11.结果展示
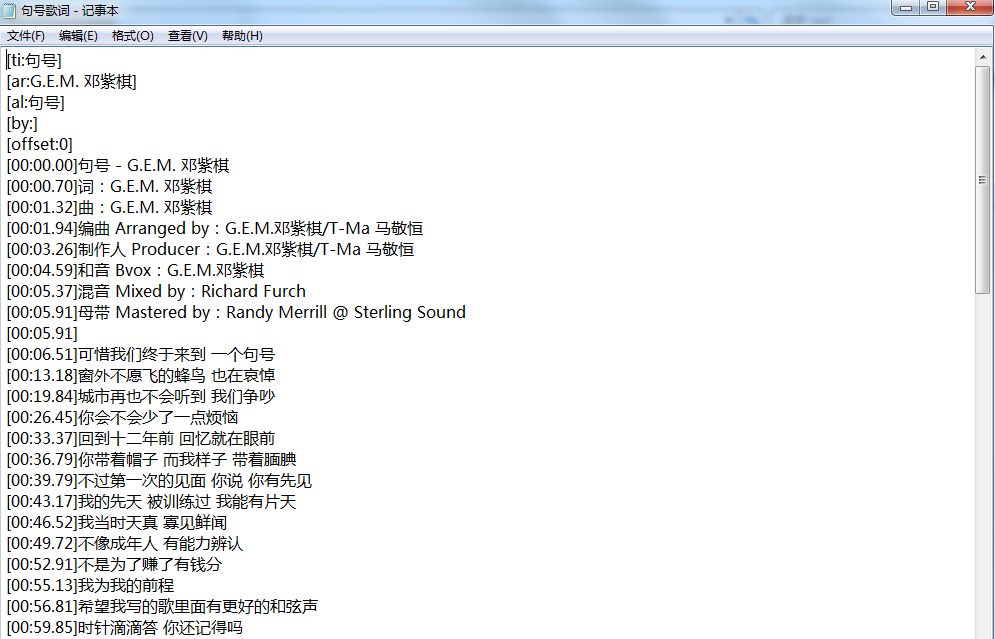
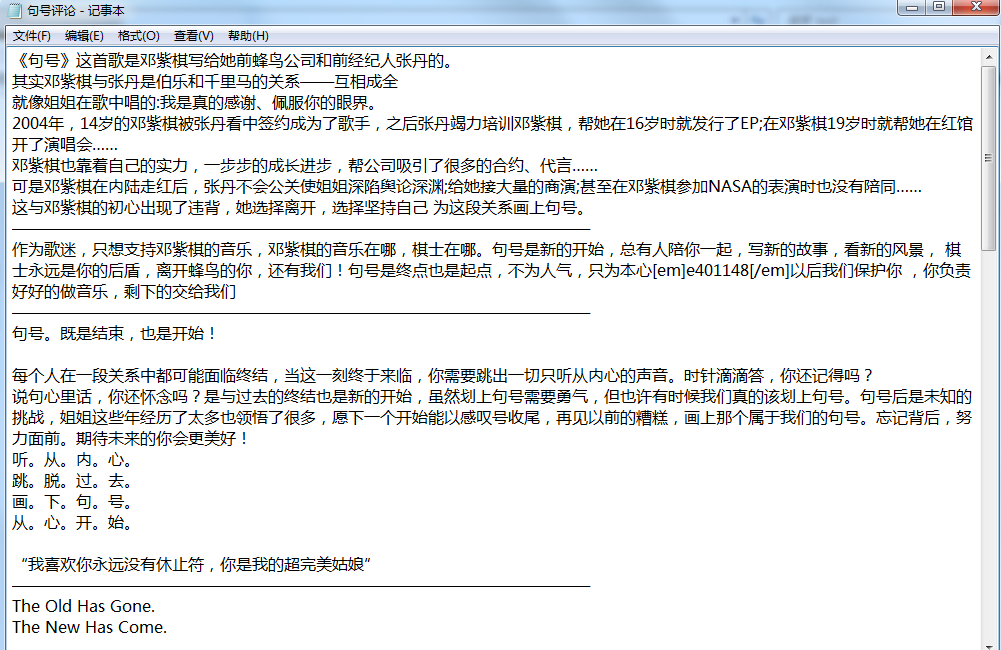
【四、总结】
1.项目二比项目一稍复杂一点,多了一步获取歌曲id的步骤;
2.通过XHR爬取数据一般要使用json,格式为:
res =requests.get(url)
json =res.json()
list = json[‘’][‘’]…
3.学习了转义字符html.unescape方法;
4.保存到txt还可以用 with open() as的方法;
5.Python爬取QQ音乐数据(第三弹)将为大家带来如何爬取更多评论,并生成词云图(wordcloud)。
6.需要本文源码的话,请在公众号后台回复“QQ音乐”四个字进行获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
手把手教你使用Python抓取QQ音乐数据(第二弹)的更多相关文章
- 手把手教你使用Python抓取QQ音乐数据(第一弹)
[一.项目目标] 获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名.专辑名.播放链接. 由浅入深,层层递进,非常适合刚入门的同学练手. [二.需要的库] 主要涉及的库有:requests.json ...
- 手把手教你用Python抓取AWS的日志(CloudTrail)数据
数据时代,利用数据做决策是大数据的核心价值. 本文手把手,教你使用python进行AWS的CloudTrail配置,进行日志抓取.进行数据分析,发现数据价值! 如今是云的时代,许多公司都把自己的IT架 ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- 使用浏览器抓取QQ音乐接口(排行榜篇)
前言 最近手头比较空闲,再加上看到其他人的博客都差不多有个类似的播放控件,手就会闲不下来,说干就干,所以我们开始吧! 来到QQ音乐的官网,我们就直奔着目标去,寻找排行榜 我们主要用的是最近比较热的歌, ...
- 使用浏览器抓取QQ音乐接口(歌曲篇)
前言 前面我们获取了歌曲的排行榜的数据,我们现在需要实现歌曲播放 前面我们写了一段函数来得到了回调的数据,现在我们需要使用这一段数据,来实现播放歌曲 完整代码 <!DOCTYPE html> ...
- 手把手教你用python抓网页数据
http://www.1point3acres.com/bbs/thread-83337-1-1.html
- python 抓取javascript 动态数据
1. 新安装一个python库 :~$ sudo pip install seleniumhq 2. 编写代码: 以获取百度百科点赞数为例 import selenium from selenium ...
随机推荐
- Vim入门教程——转
简书: https://www.jianshu.com/p/bcbe916f97e1
- Spring boot Sample 007之spring-boot-log4j2
一.环境 1.1.Idea 2020.1 1.2.JDK 1.8 二.目的 spring boot 整合多环境log4j2 三.步骤 3.1.点击File -> New Project -> ...
- 一个神秘URL酿大祸,差点让我背锅!
神秘URL 我叫小风,是Windows帝国一个普通的上班族.上一回说到因为一个跨域请求,我差点丢了饭碗,好在有惊无险,我的职场历险记还在继续. "叮叮叮叮~~~~",闹钟又把我给吵 ...
- Java实现 LeetCode 824 山羊拉丁文(暴力)
824. 山羊拉丁文 给定一个由空格分割单词的句子 S.每个单词只包含大写或小写字母. 我们要将句子转换为 "Goat Latin"(一种类似于 猪拉丁文 - Pig Latin ...
- Java实现 LeetCode 646 最长数对链(暴力)
646. 最长数对链 给出 n 个数对. 在每一个数对中,第一个数字总是比第二个数字小. 现在,我们定义一种跟随关系,当且仅当 b < c 时,数对(c, d) 才可以跟在 (a, b) 后面. ...
- Java实现 LeetCode 462 最少移动次数使数组元素相等 II
462. 最少移动次数使数组元素相等 II 给定一个非空整数数组,找到使所有数组元素相等所需的最小移动数,其中每次移动可将选定的一个元素加1或减1. 您可以假设数组的长度最多为10000. 例如: 输 ...
- Java实现 LeetCode 12 整数转罗马数字
12. 整数转罗马数字 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 ...
- Android中WebView如何加载JavaScript脚本
主Activity和XML布局,末尾附上效果图 package com.example.myapplication; import androidx.appcompat.app.AppCompatAc ...
- Java实现最大流量问题
1 问题描述 何为最大流量问题? 给定一个有向图,并为每一个顶点设定编号为0~n,现在求取从顶点0(PS:也可以称为源点)到顶点n(PS:也可以称为汇点)后,顶点n能够接收的最大流量.图中每条边的权值 ...
- java实现三进制转十进制
** 三进制转十进制** 不同进制的数值间的转换是软件开发中很可能 会遇到的常规问题.下面的代码演示了如何把键盘输入的3 进制数字转换为十进制.试完善之. BufferedReader br = ne ...