初识Prometheus
安装Prometheus Server
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
从二进制包安装
对于非Docker用户,可以从https://prometheus.io/download/找到最新版本的Prometheus Sevrer软件包:
export VERSION=2.4.3curl -LO https://github.com/prometheus/prometheus/releases/download/v$VERSION/prometheus-$VERSION.darwin-amd64.tar.gz
解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-${VERSION}.darwin-amd64.tar.gzcd prometheus-${VERSION}.darwin-amd64
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global configglobal:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'prometheus'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['localhost:9090']
Promtheus作为一个时间序列数据库,其采集的数据会以文件的形似存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数--storage.tsdb.path="data/"修改本地数据存储的路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件:
./prometheus
正常的情况下,你可以看到以下输出内容:
level=info ts=2018-10-23T14:55:14.499484Z caller=main.go:554 msg="Starting TSDB ..."level=info ts=2018-10-23T14:55:14.499531Z caller=web.go:397 component=web msg="Start listening for connections" address=0.0.0.0:9090level=info ts=2018-10-23T14:55:14.507999Z caller=main.go:564 msg="TSDB started"level=info ts=2018-10-23T14:55:14.508068Z caller=main.go:624 msg="Loading configuration file" filename=prometheus.ymllevel=info ts=2018-10-23T14:55:14.509509Z caller=main.go:650 msg="Completed loading of configuration file" filename=prometheus.ymllevel=info ts=2018-10-23T14:55:14.509537Z caller=main.go:523 msg="Server is ready to receive web requests."
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server:
docker run -d -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
启动完成后,可以通过http://localhost:9090访问Prometheus的UI界面:
使用Node Exporter采集主机运行数据
安装Node Exporter
在Prometheus的架构设计中,Prometheus Server并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的CPU使用率,我们需要使用到Exporter。Prometheus周期性的从Exporter暴露的HTTP服务地址(通常是/metrics)拉取监控样本数据。
从上面的描述中可以看出Exporter可以是一个相对开放的概念,其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向Prometheus提供标准格式的监控样本数据即可。
这里为了能够采集到主机的运行指标如CPU, 内存,磁盘等信息。我们可以使用Node Exporter。
Node Exporter同样采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。可以从https://prometheus.io/download/获取最新的node exporter版本的二进制包。
curl -OL https://github.com/prometheus/node_exporter/releases/download/v0.15.2/node_exporter-0.15.2.darwin-amd64.tar.gztar -xzf node_exporter-0.15.2.darwin-amd64.tar.gz
运行node exporter:
cd node_exporter-0.15.2.darwin-amd64cp node_exporter-0.15.2.darwin-amd64/node_exporter /usr/local/bin/node_exporter
启动成功后,可以看到以下输出:
INFO[0000] Listening on :9100 source="node_exporter.go:76"
访问http://localhost:9100/可以看到以下页面:
初始Node Exporter监控指标
访问http://localhost:9100/metrics,可以看到当前node exporter获取到的当前主机的所有监控数据,如下所示:
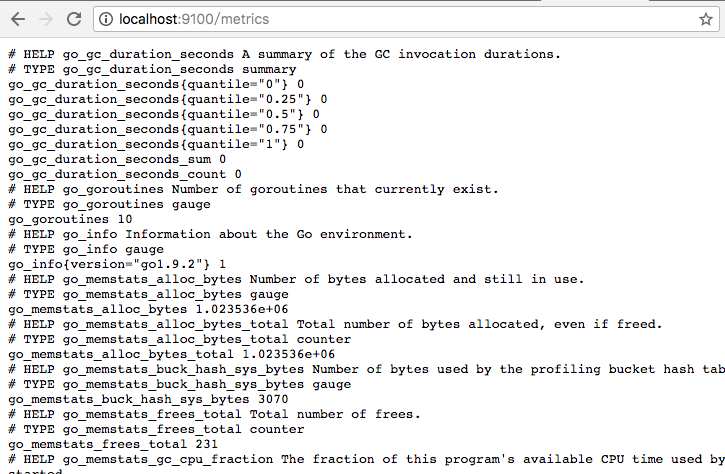
每一个监控指标之前都会有一段类似于如下形式的信息:
# HELP node_cpu Seconds the cpus spent in each mode.# TYPE node_cpu counternode_cpu{cpu="cpu0",mode="idle"} 362812.7890625# HELP node_load1 1m load average.# TYPE node_load1 gaugenode_load1 3.0703125
其中HELP用于解释当前指标的含义,TYPE则说明当前指标的数据类型。在上面的例子中node_cpu的注释表明当前指标是cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是计数器(counter),与该指标的实际含义一致。又例如node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为仪表盘(gauge),与指标反映的实际含义一致。
除了这些以外,在当前页面中根据物理主机系统的不同,你还可能看到如下监控指标:
- node_boot_time:系统启动时间
- node_cpu:系统CPU使用量
- nodedisk*:磁盘IO
- nodefilesystem*:文件系统用量
- node_load1:系统负载
- nodememeory*:内存使用量
- nodenetwork*:网络带宽
- node_time:当前系统时间
- go_*:node exporter中go相关指标
- process_*:node exporter自身进程相关运行指标
从Node Exporter收集监控数据
为了能够让Prometheus Server能够从当前node exporter获取到监控数据,这里需要修改Prometheus配置文件。编辑prometheus.yml并在scrape_configs节点下添加以下内容:
scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']# 采集node exporter监控数据- job_name: 'node'static_configs:- targets: ['localhost:9100']
重新启动Prometheus Server
访问http://localhost:9090,进入到Prometheus Server。如果输入“up”并且点击执行按钮以后,可以看到如下结果:
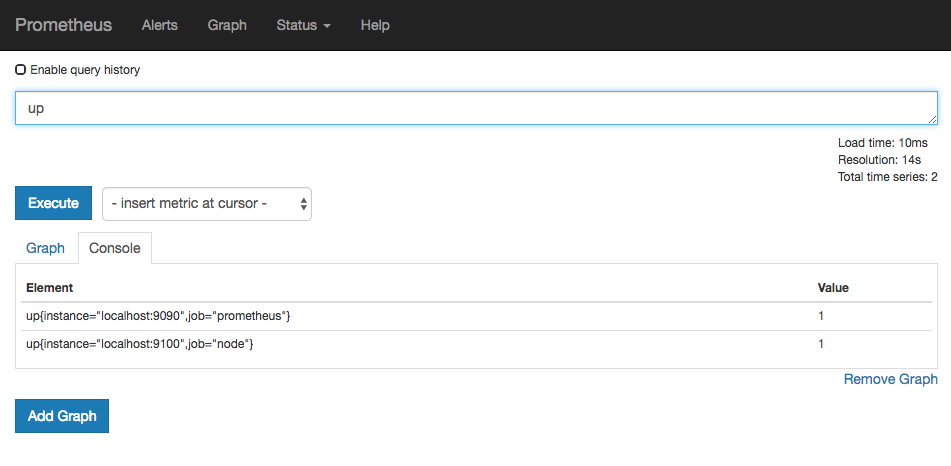
如果Prometheus能够正常从node exporter获取数据,则会看到以下结果:
up{instance="localhost:9090",job="prometheus"} 1up{instance="localhost:9100",job="node"} 1
其中“1”表示正常,反之“0”则为异常。
使用容器安装
对于Docker用户,直接使用Prometheus的镜像即可启动Prometheus Server:
docker run -d -p 9100:9100 prom/node-exporter
使用PromQL查询监控数据
Prometheus UI是Prometheus内置的一个可视化管理界面,通过Prometheus UI用户能够轻松的了解Prometheus当前的配置,监控任务运行状态等。 通过Graph面板,用户还能直接使用PromQL实时查询监控数据:
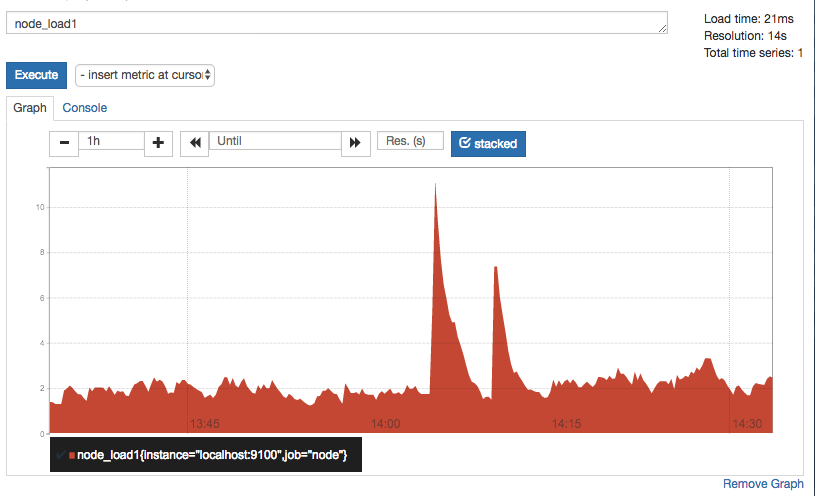
切换到Graph面板,用户可以使用PromQL表达式查询特定监控指标的监控数据。如下所示,查询主机负载变化情况,可以使用关键字node_load1可以查询出Prometheus采集到的主机负载的样本数据,这些样本数据按照时间先后顺序展示,形成了主机负载随时间变化的趋势图表:
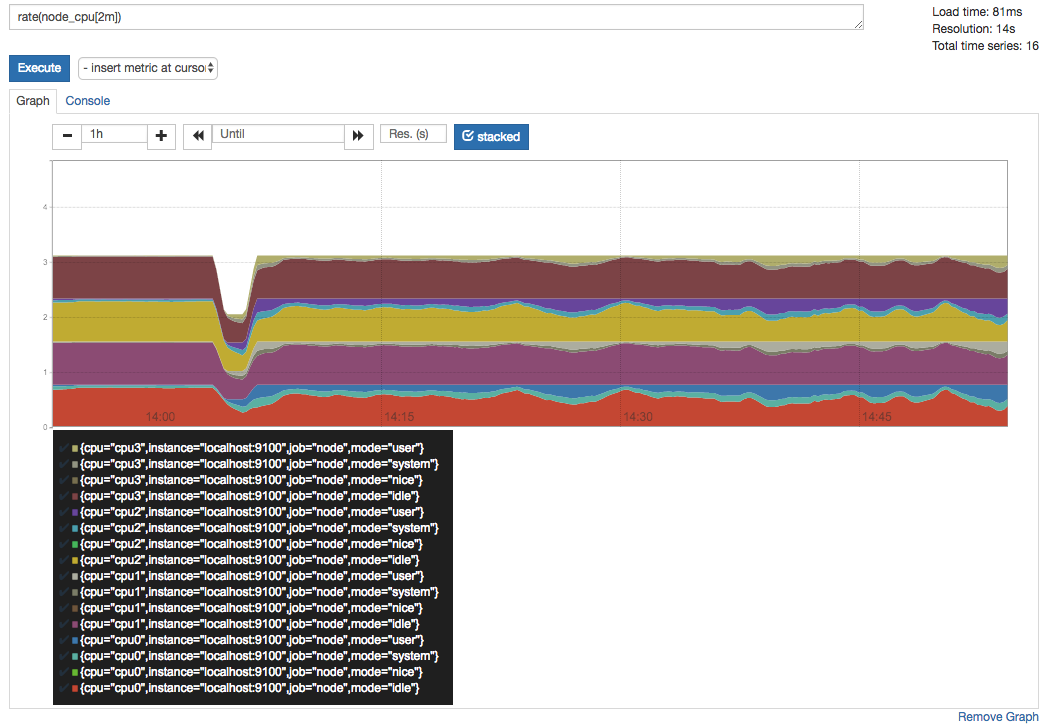
PromQL是Prometheus自定义的一套强大的数据查询语言,除了使用监控指标作为查询关键字以为,还内置了大量的函数,帮助用户进一步对时序数据进行处理。例如使用rate()函数,可以计算在单位时间内样本数据的变化情况即增长率,因此通过该函数我们可以近似的通过CPU使用时间计算CPU的利用率:
rate(node_cpu[2m])
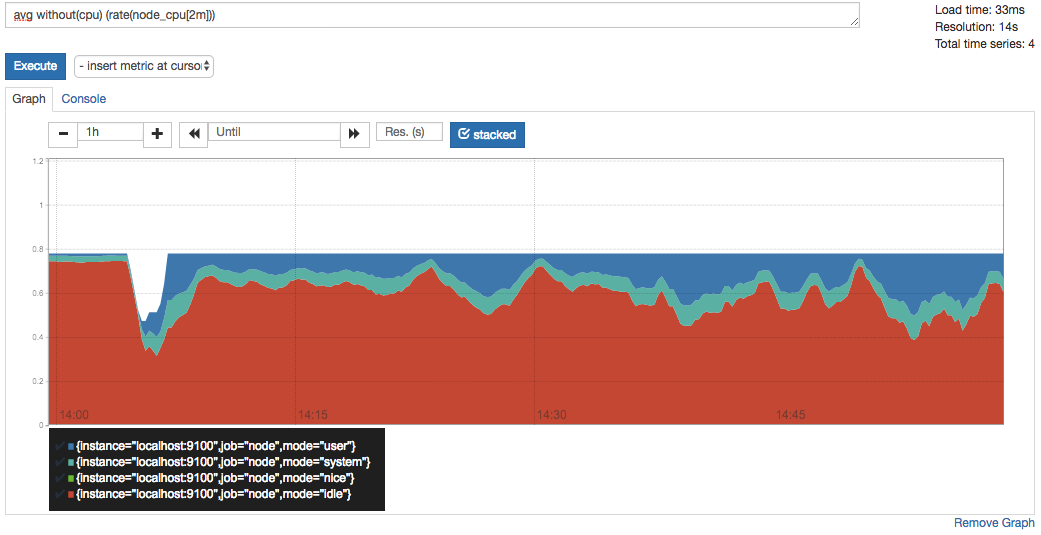
这时如果要忽略是哪一个CPU的,只需要使用without表达式,将标签CPU去除后聚合数据即可:
avg without(cpu) (rate(node_cpu[2m]))
那如果需要计算系统CPU的总体使用率,通过排除系统闲置的CPU使用率即可获得:
1 - avg without(cpu) (rate(node_cpu{mode="idle"}[2m]))
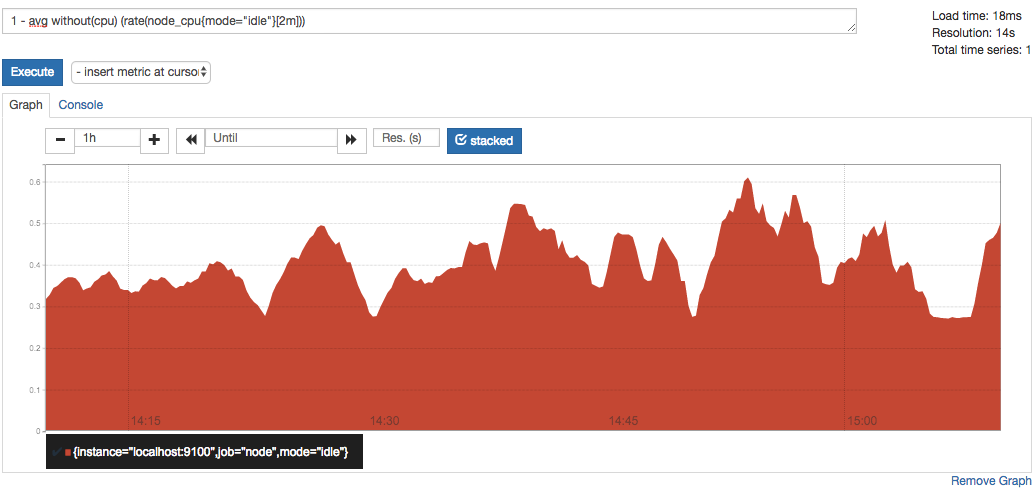
通过PromQL我们可以非常方便的对数据进行查询,过滤,以及聚合,计算等操作。通过这些丰富的表达书语句,监控指标不再是一个单独存在的个体,而是一个个能够表达出正式业务含义的语言。
使用Grafana创建可视化Dashboard
Prometheus UI提供了快速验证PromQL以及临时可视化支持的能力,而在大多数场景下引入监控系统通常还需要构建可以长期使用的监控数据可视化面板(Dashboard)。这时用户可以考虑使用第三方的可视化工具如Grafana,Grafana是一个开源的可视化平台,并且提供了对Prometheus的完整支持。
docker run -d -p 3000:3000 grafana/grafana
访问http://localhost:3000就可以进入到Grafana的界面中,默认情况下使用账户admin/admin进行登录。在Grafana首页中显示默认的使用向导,包括:安装、添加数据源、创建Dashboard、邀请成员、以及安装应用和插件等主要流程:
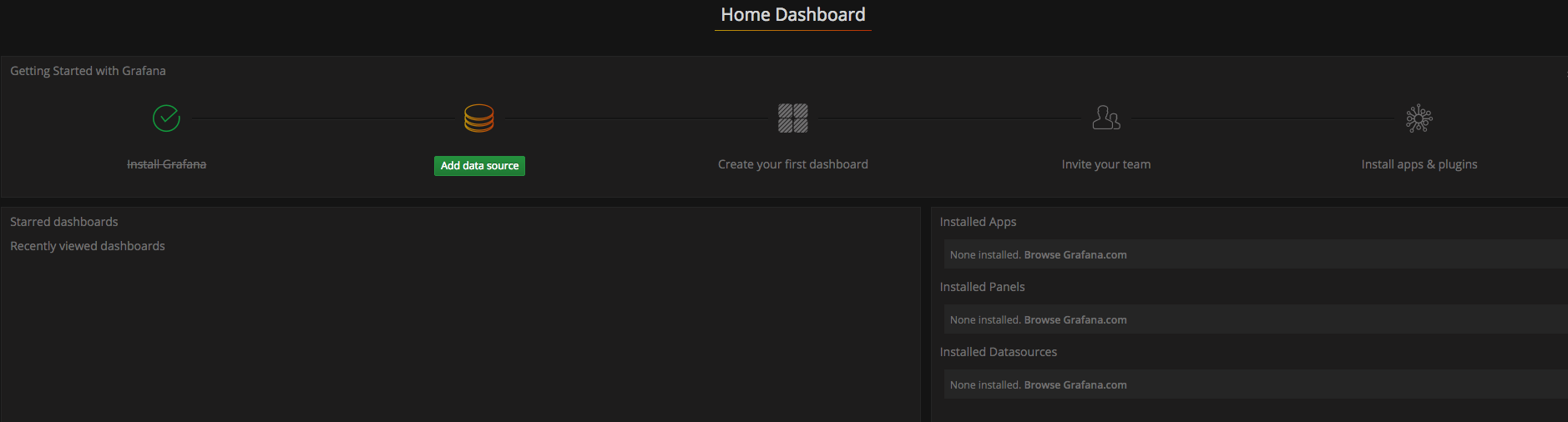
这里将添加Prometheus作为默认的数据源,如下图所示,指定数据源类型为Prometheus并且设置Prometheus的访问地址即可,在配置正确的情况下点击“Add”按钮,会提示连接成功的信息:
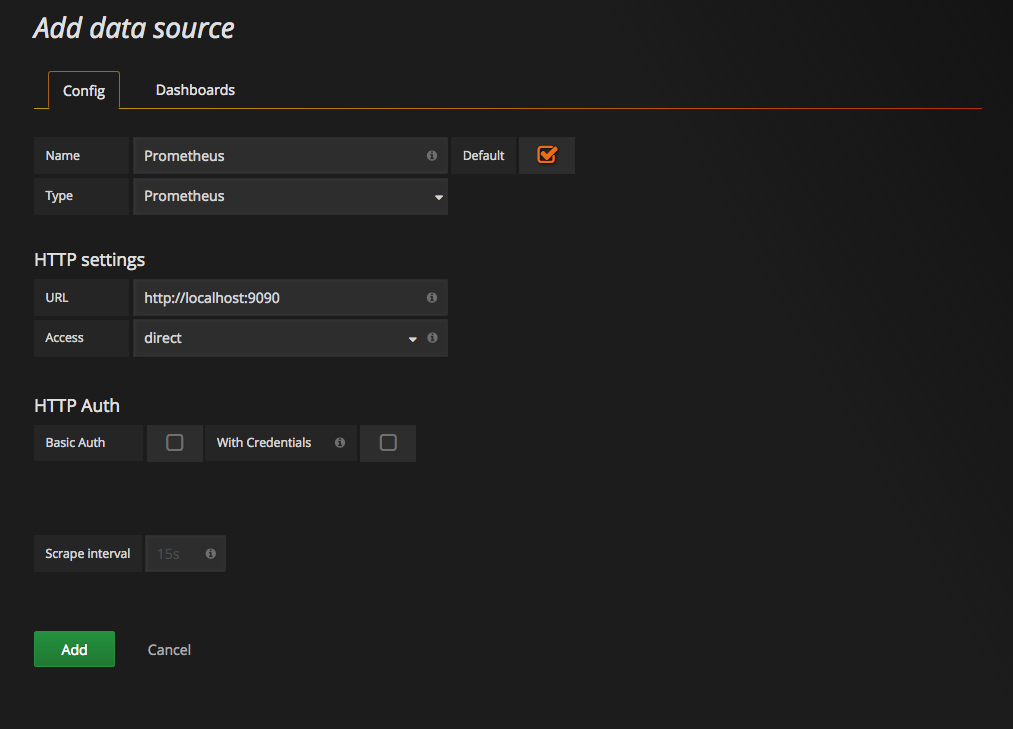
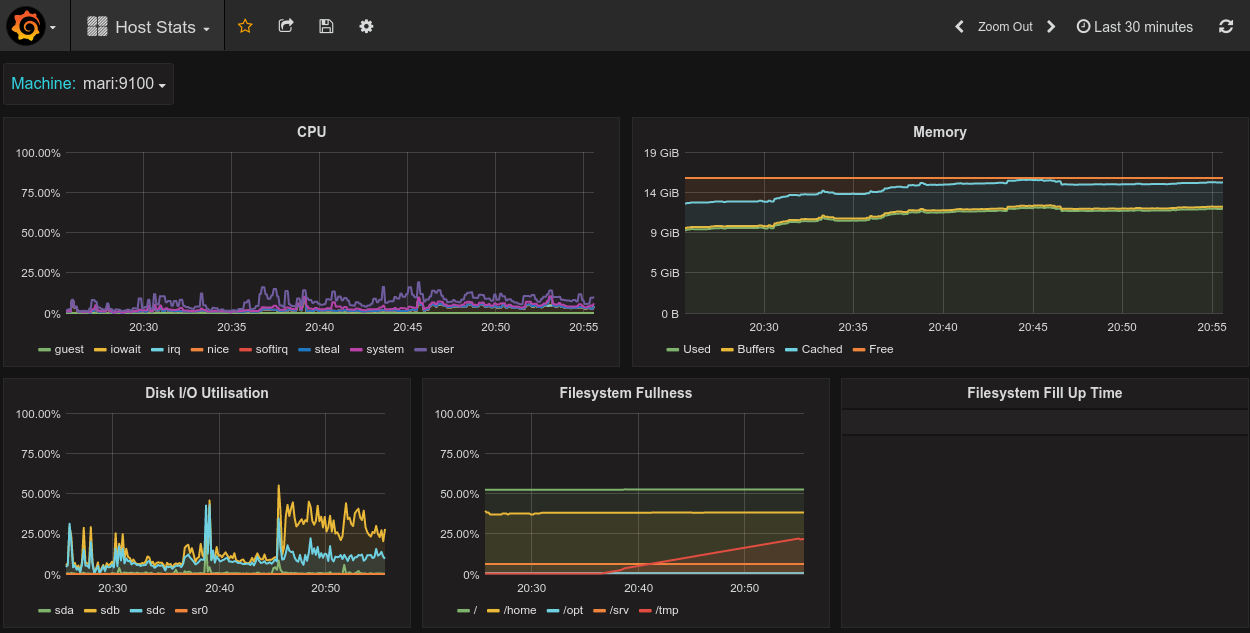
在完成数据源的添加之后就可以在Grafana中创建我们可视化Dashboard了。Grafana提供了对PromQL的完整支持,如下所示,通过Grafana添加Dashboard并且为该Dashboard添加一个类型为“Graph”的面板。 并在该面板的“Metrics”选项下通过PromQL查询需要可视化的数据:
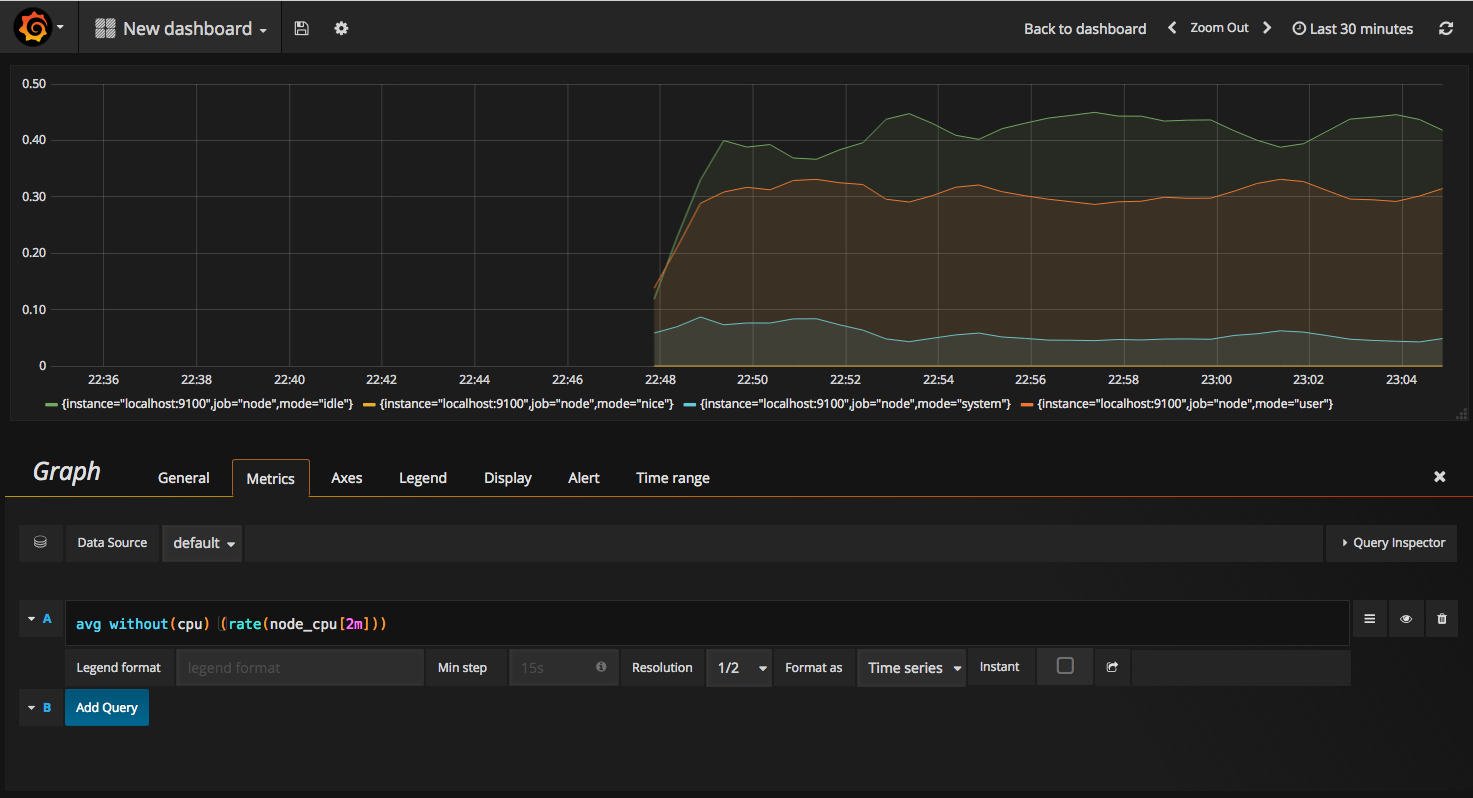
点击界面中的保存选项,就创建了我们的第一个可视化Dashboard了。 当然作为开源软件,Grafana社区鼓励用户分享Dashboard通过https://grafana.com/dashboards网站,可以找到大量可直接使用的Dashboard:
Grafana中所有的Dashboard通过JSON进行共享,下载并且导入这些JSON文件,就可以直接使用这些已经定义好的Dashboard:
初识Prometheus的更多相关文章
- Prometheus监控学习笔记之全面学习Prometheus
0x00 概述 Prometheus是继Kubernetes后第2个正式加入CNCF基金会的项目,容器和云原生领域事实的监控标准解决方案.在这次分享将从Prometheus的基础说起,学习和了解Pro ...
- 《为什么说 Prometheus 是足以取代 Zabbix 的监控神器?》
为什么说 Prometheus 是足以取代 Zabbix 的监控神器? Kuberneteschina 致力于提供最权威的 Kubernetes 技术.案例与Meetup! 关注他 12 人赞同 ...
- Prometheus 学习目录
Prometheus 介绍 Prometheus 安装 https://www.bookstack.cn/read/prometheus-book/quickstart-why-monitor.md ...
- Prometheus监控学习笔记之初识PromQL
0x00 概述 Prometheus 提供了一种功能表达式语言 PromQL,允许用户实时选择和汇聚时间序列数据.表达式的结果可以在浏览器中显示为图形,也可以显示为表格数据,或者由外部系统通过 HTT ...
- 初识PromQL
初识PromQL Prometheus通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列.指标名称反映了监控样本的基本标识,而label则在这个基本特征 ...
- prometheus监控系统
关于Prometheus Prometheus是一套开源的监控系统,它将所有信息都存储为时间序列数据:因此实现一种Profiling监控方式,实时分析系统运行的状态.执行时间.调用次数等,以找到系统的 ...
- Prometheus 系统监控方案 一
最近一直在折腾时序类型的数据库,经过一段时间项目应用,觉得十分不错.而Prometheus又是刚刚推出不久的开源方案,中文资料较少,所以打算写一系列应用的实践过程分享一下. Prometheus 是什 ...
- Android动画效果之初识Property Animation(属性动画)
前言: 前面两篇介绍了Android的Tween Animation(补间动画) Android动画效果之Tween Animation(补间动画).Frame Animation(逐帧动画)Andr ...
- 初识Hadoop
第一部分: 初识Hadoop 一. 谁说大象不能跳舞 业务数据越来越多,用关系型数据库来存储和处理数据越来越感觉吃力,一个查询或者一个导出,要执行很长 ...
随机推荐
- 解决:jenkins jnlp安装 provided port 40127 is not reachable
解决方法: 开放linux 防火墙40127端口允许下载jnlp centos7 解决如下: [root@hostuser chrome]# firewall-cmd --zone=public -- ...
- winform Anchor和Dock属性
在设计窗体时,这两个属性特别有用,如果用户认为改变窗口的大小并不容易,应确保窗口看起来不显得很乱,并编写许多代码行来达到这个目的,许多程序解决这个问题是地,都是禁止给窗口重新设置大小,这显然是解决问题 ...
- JAVA(1)之关于对象数组作形参名的方法的使用
public class Test{ int tour; public static void cs(Test a[]) { for (int i = 0; i < a.length; i++) ...
- Golang介绍以及安装
Go语言 Google开源 编译形语言 21世纪的C语言 Go语言的特点 简单易并发 开发效率高 执行性能好 Go语言应用的领域 服务端开发 日志处理 文件系统 监控服务 容器虚拟化 Docker k ...
- 牛客大数加法-A+B
题目描述实现一个加法器,使其能够输出a+b的值.输入描述:输入包括两个数a和b,其中a和b的位数不超过1000位.输出描述:可能有多组测试数据,对于每组数据,输出a+b的值.示例1输入2 610000 ...
- 【PAT甲级】1064 Complete Binary Search Tree (30 分)
题意:输入一个正整数N(<=1000),接着输入N个非负整数(<=2000),输出完全二叉树的层次遍历. AAAAAccepted code: #define HAVE_STRUCT_TI ...
- 树莓派4B踩坑指南 - (9)安装Git和Docker
安装Git sudo apt-get install wget git-core 安装Docker curl -sSL https://get.docker.com | sh # 树莓派专属脚本福利, ...
- python学习 —— 使用subprocess获取命令行输出结果
这里使用的版本:Python2 >= 2.7 对于获取命令行窗口中的输出python有一个很好用的模块:subprocess 两个简单例子: 1.获取ping命令的输出: from subpro ...
- centos610无桌面安装libreoffice缺失字体
1.安装libreoffice 2.安装fontconfig yum -y install fontconfig 3.安装ttmkfdir yum -y install ttmkfdir 4.检查已有 ...
- 解决github访问慢和下载项目慢的问题
一.国内访问 GitHub 为什么很慢? GitHub的CDN域名遭到DNS污染,导致无法连接使用 GitHub 的加速分发服务器,才使得国内访问速度很慢. 二.如何解决 DNS 污染? 通过修改 ...