0 Spark完成WordCount操作
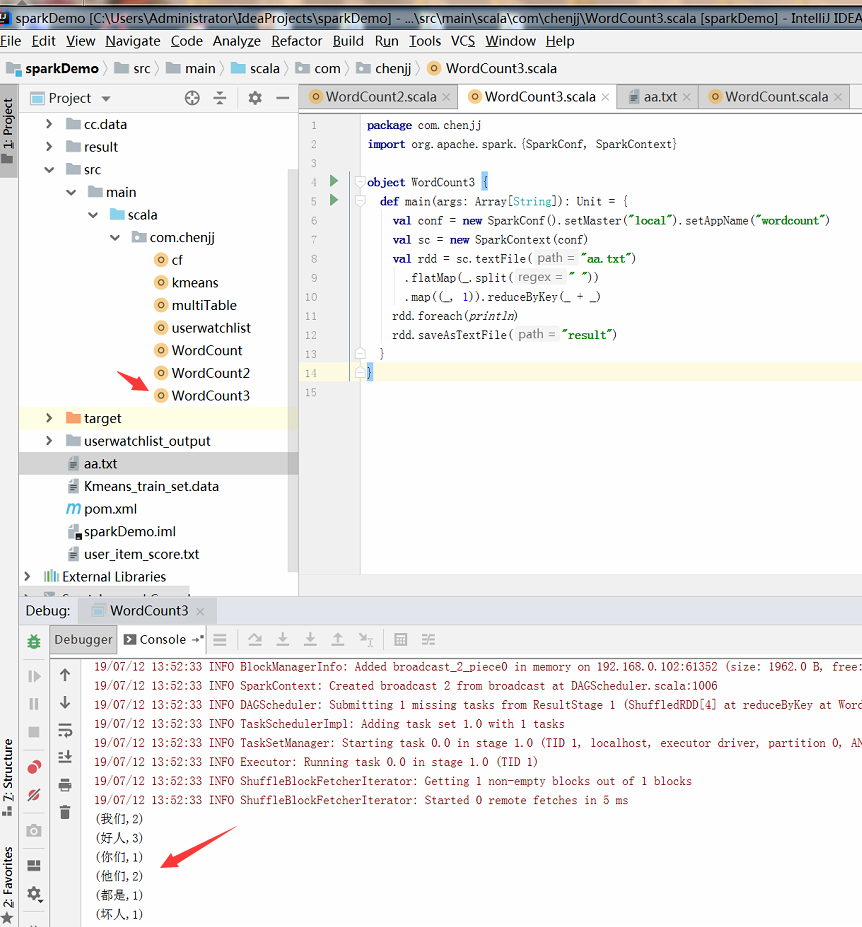
先看下结果:
pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chenjj</groupId>
<artifactId>sparkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<spark.version>2.2.0</spark.version>
</properties> <repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories> <dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<classifier>dist</classifier>
<appendAssemblyId>true</appendAssemblyId>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
1、项目目录下新建aa.txt文件
我们 都是 好人
我们 好人 你们 他们
好人 坏人 他们
2、scala版本---WordCount3.scala
package com.chenjj
import org.apache.spark.{SparkConf, SparkContext} object WordCount3 {
def main(args: Array[String]): Unit = {
//conf 可以设置SparkApplication 的名称,设置Spark 运行的模式
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
//SparkContext 是通往spark 集群的唯一通道
val sc = new SparkContext(conf)
val rdd = sc.textFile("aa.txt")
.flatMap(_.split(" "))
.map((_, 1)).reduceByKey(_ + _)
rdd.foreach(println)
rdd.saveAsTextFile("result")
}
}
3、运行结果:

0 Spark完成WordCount操作的更多相关文章
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- spark 对hbase 操作
本文将分两部分介绍,第一部分讲解使用 HBase 新版 API 进行 CRUD 基本操作:第二部分讲解如何将 Spark 内的 RDDs 写入 HBase 的表中,反之,HBase 中的表又是如何以 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- spark shuffle写操作三部曲之UnsafeShuffleWriter
前言 在前两篇文章 spark shuffle的写操作之准备工作 中引出了spark shuffle的三种实现,spark shuffle写操作三部曲之BypassMergeSortShuffleWr ...
- spark shuffle写操作之SortShuffleWriter
提出问题 1. spark shuffle的预聚合操作是如何做的,其中底层的数据结构是什么?在数据写入到内存中有预聚合,在读溢出文件合并到最终的文件时是否也有预聚合操作? 2. shuffle数据的排 ...
随机推荐
- Spring Boot:整合JdbcTemplate
综合概述 Spring对数据库的操作在jdbc上面做了更深层次的封装,而JdbcTemplate便是Spring提供的一个操作数据库的便捷工具.我们可以借助JdbcTemplate来执行所有数据库操作 ...
- Web框架之Django重要组件(Django中间件、csrf跨站请求伪造)
Web框架之Django_09 重要组件(Django中间件.csrf跨站请求伪造) 摘要 Django中间件 csrf跨站请求伪造 一.Django中间件: 什么是中间件? 官方的说法:中间件是 ...
- Metasploit学习笔记
原创博客,转载请注出处! 各位看官可参看——Metasploit实验操作 1.打开msf msfconsole2.帮助选项: msfconsole -h 显示在msf ...
- ElasticStack学习(二):ElasticStack安装与运行
一.ElasticSearch的安装与运行 1.由于ElasticSearch是由Java语言开发的,若要运行ElasticSearch,需要安装并配置JDK,并要设置$JAVA_HOME环境变量. ...
- T4生成实体和简单的CRUD操作
主要跟大家交流下T4,我这里针对的是mysql,我本人比较喜欢用mysql,所以语法针对mysql,所以你要准备mysql的DLL了,同理sqlserver差不多,有兴趣可以自己写写,首先网上找了一个 ...
- DFS和BFS的比较
DFS(Depth First Search,深度优先搜索)和BFS(Breadth First Search,广度优先搜索)是两种典型的搜索算法.下面通过一个实例来比较一下深度优先搜索和广度优先搜索 ...
- Java中的反射(1)
Reflection in Java 反射到底是什么呢,我被问到的时候其实也没办法很好的回答这个问题,翻一翻博客,然后逐条讲解.今天干脆就整合一下,免得以后还要去翻. 首先讲一下Java是如何在运行时 ...
- Unity3D热更新之LuaFramework篇[06]--Lua中是怎么实现脚本生命周期的
前言 用c#开发的时候,新建的脚本都默认继承自Monobehaviour, 因此脚本才有了自己的生命周期函数,如Awake,Start, Update, OnDestroy等. 在相应的方法中实现游戏 ...
- 解决thinkphp在开发环境下文件模块找不到的问题
win10系统下,phpstudy开发环境下小问题描述: 找不到public公共模块. Not Found The requested URL /public/admin/login.html was ...
- apache开启vhost后localhost和127.0.0.1无法访问
自己单独搭建了php+mysql+apach+windows环境:后面又开启apache的虚拟主机vhost;然后自己配置虚拟主机站点可以正常访问,但是localhost和127.0.0.1无法访问, ...