使用Redis实现UA池
前提
最近忙于业务开发、交接和游戏,加上碰上了不定时出现的犹豫期和困惑期,荒废学业了一段时间。天冷了,要重新拾起开始下阶段的学习了。之前接触到的一些数据搜索项目,涉及到请求模拟,基于反爬需要使用随机的User Agent,于是使用Redis实现了一个十分简易的UA池。
背景
最近的一个需求,有模拟请求的逻辑,要求每次请求的请求头中的User Agent要满足下面几点:
- 每次获取的
User Agent是随机的。 - 每次获取的
User Agent(短时间内)不能重复。 - 每次获取的
User Agent必须带有主流的操作系统信息(可以是Uinux、Windows、IOS和安卓等等)。
这里三点都可以从UA数据的来源解决,实际上我们应该关注具体的实现方案。简单分析一下,流程如下:

在设计UA池的时候,它的数据结构和环形队列十分类似:
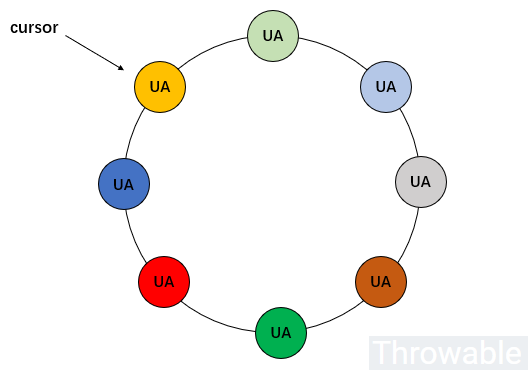
上图中,假设不同颜色的UA是完全不同的UA,它们通过洗牌算法打散放进去环形队列中,实际上每次取出一个UA之后,只需要把游标cursor前进或者后退一格即可(甚至可以把游标设置到队列中的任意元素)。最终的实现就是:需要通过中间件实现分布式队列(只是队列,不是消息队列)。
具体实现方案
毫无疑问需要一个分布式数据库类型的中间件才能存放已经准备好的UA,第一印象就感觉Redis会比较合适。接下来需要选用Redis的数据类型,主要考虑几个方面:
- 具备队列性质。
- 最好支持随机访问。
- 元素入队、出队和随机访问的时间复杂度要低,毕竟获取
UA的接口访问量会比较大。
支持这几个方面的Redis数据类型就是List,不过注意List本身不能去重,去重的工作可以用代码逻辑实现。然后可以想象客户端获取UA的流程大致如下:
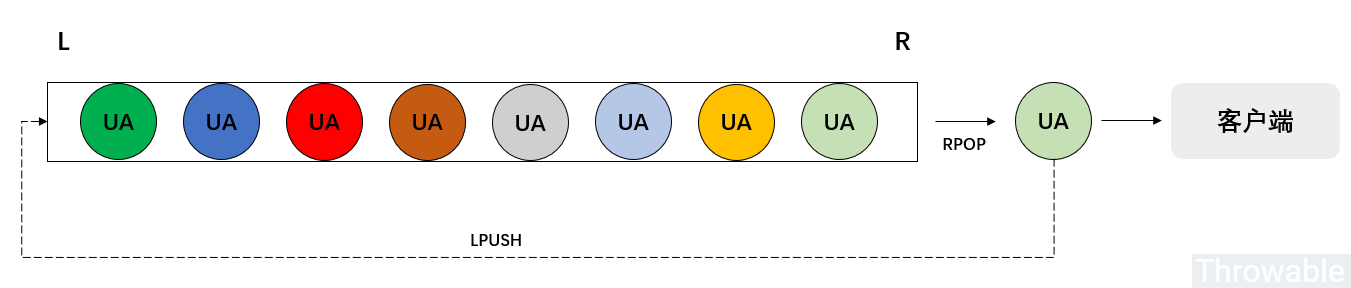
结合前面的分析,编码过程有如下几步:
- 准备好需要导入的
UA数据,可以从数据源读取,也可以直接文件读取。 - 因为需要导入的
UA数据集合一般不会太大,考虑先把这个集合的数据随机打散,如果使用Java开发可以直接使用Collections#shuffle()洗牌算法,当然也可以自行实现这个数据随机分布的算法,这一步对于一些被模拟方会严格检验UA合法性的场景是必须的。 - 导入
UA数据到Redis列表中。 - 编写
RPOP + LPUSH的Lua脚本,实现分布式循环队列。
编码和测试示例
引入Redis的高级客户端Lettuce依赖:
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>5.2.1.RELEASE</version>
</dependency>
编写RPOP + LPUSH的Lua脚本,Lua脚本名字暂称为L_RPOP_LPUSH.lua,放在resources/scripts/lua目录下:
local key = KEYS[1]
local value = redis.call('RPOP', key)
redis.call('LPUSH', key, value)
return value
这个脚本十分简单,但是已经实现了循环队列的功能。剩下来的测试代码如下:
public class UaPoolTest {
private static RedisCommands<String, String> COMMANDS;
private static AtomicReference<String> LUA_SHA = new AtomicReference<>();
private static final String KEY = "UA_POOL";
@BeforeClass
public static void beforeClass() throws Exception {
// 初始化Redis客户端
RedisURI uri = RedisURI.builder().withHost("localhost").withPort(6379).build();
RedisClient redisClient = RedisClient.create(uri);
StatefulRedisConnection<String, String> connect = redisClient.connect();
COMMANDS = connect.sync();
// 模拟构建UA池的原始数据,假设有10个UA,分别是UA-0 ... UA-9
List<String> uaList = Lists.newArrayList();
IntStream.range(0, 10).forEach(e -> uaList.add(String.format("UA-%d", e)));
// 洗牌
Collections.shuffle(uaList);
// 加载Lua脚本
ClassPathResource resource = new ClassPathResource("/scripts/lua/L_RPOP_LPUSH.lua");
String content = StreamUtils.copyToString(resource.getInputStream(), StandardCharsets.UTF_8);
String sha = COMMANDS.scriptLoad(content);
LUA_SHA.compareAndSet(null, sha);
// Redis队列中写入UA数据,数据量多的时候可以考虑分批写入防止长时间阻塞Redis服务
COMMANDS.lpush(KEY, uaList.toArray(new String[0]));
}
@AfterClass
public static void afterClass() throws Exception {
COMMANDS.del(KEY);
}
@Test
public void testUaPool() {
IntStream.range(1, 21).forEach(e -> {
String result = COMMANDS.evalsha(LUA_SHA.get(), ScriptOutputType.VALUE, KEY);
System.out.println(String.format("第%d次获取到的UA是:%s", e, result));
});
}
}
某次运行结果如下:
第1次获取到的UA是:UA-0
第2次获取到的UA是:UA-8
第3次获取到的UA是:UA-2
第4次获取到的UA是:UA-4
第5次获取到的UA是:UA-7
第6次获取到的UA是:UA-5
第7次获取到的UA是:UA-1
第8次获取到的UA是:UA-3
第9次获取到的UA是:UA-6
第10次获取到的UA是:UA-9
第11次获取到的UA是:UA-0
第12次获取到的UA是:UA-8
第13次获取到的UA是:UA-2
第14次获取到的UA是:UA-4
第15次获取到的UA是:UA-7
第16次获取到的UA是:UA-5
第17次获取到的UA是:UA-1
第18次获取到的UA是:UA-3
第19次获取到的UA是:UA-6
第20次获取到的UA是:UA-9
可见洗牌算法的效果不差,数据相对分散。
小结
其实UA池的设计难度并不大,需要注意几个要点:
- 一般主流的移动设备或者桌面设备的系统版本不会太多,所以来源
UA数据不会太多,最简单的实现可以使用文件存放,一次读取直接写入Redis中。 - 注意需要随机打散
UA数据,避免同一个设备系统类型的UA数据过于密集,这样可以避免触发模拟某些请求时候的风控规则。 - 需要熟悉
Lua的语法,毕竟Redis的原子指令一定离不开Lua脚本。
(本文完 c-2-d e-a-20191114)
原文链接
- Github Page:http://throwable.club/2019/11/14/redis-in-action-ua-pool/
- Coding Page:http://throwable.coding.me/2019/11/14/redis-in-action-ua-pool/
使用Redis实现UA池的更多相关文章
- selenium、UA池、ip池、scrapy-redis的综合应用案例
案例: 网易新闻的爬取: https://news.163.com/ 爬取的内容为一下4大板块中的新闻内容 爬取: 特点: 动态加载数据 ,用 selenium 爬虫 1. 创建项目 scrapy ...
- Redis客户端连接池
使用场景 对于一些大对象,或者初始化过程较长的可复用的对象,我们如果每次都new对象出来,那么意味着会耗费大量的时间. 我们可以将这些对象缓存起来,当接口调用完毕后,不是销毁对象,当下次使用的时候,直 ...
- redis运用连接池报错解决
redis使用连接池报错解决redis使用十几小时就一直报异常 redis.clients.jedis.exceptions.JedisConnectionException: Could not g ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- 14.UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - ...
- UA池和代理池
scrapy下载中间件 UA池 代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎 ...
- UA池和代理池在scrapy中的应用
一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系 ...
- 爬虫开发13.UA池和代理池在scrapy中的应用
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: ( ...
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
随机推荐
- Java基础接口和抽象类区别(二)
抽象类 在了解抽象类之前,先来了解一下抽象方法.抽象方法是一种特殊的方法:它只有声明,而没有具体的实现.抽象方法的声明格式为: 抽象方法必须用abstract关键字进行修饰.如果一个类含有抽象方法,则 ...
- JS 正则表达式^$详解,脱字符^与美元符$同时写表示什么意思?
壹 ❀ 引 对于初学正则的同学来说,^$这两个看似简单的字符却在使用中总让匹配结果超出我们的预期,^什么时候表示行首什么时候表示反义?^ $两个一起写表示什么含义?今天我们就来详细聊聊这两个字符. ...
- PDF提取表格的网页工具——Excalibur
在之前的文章另类爬虫:从PDF文件中爬取表格数据中,我们知道如何利用Python的camelot模块,通过写Python程序来提取PDF中的表格数据.本文我们将学习如何用更便捷的工具从PDF中提取 ...
- Redis基础知识、命令以及java操作Redis
1 nosql的概念 sql:操作(关系型)数据库的标准查询语言 关系型数据库(rdbms):以关系(由行和列组成的二维表)模型为核心数据库,有表的储存系统.(mysql.oracle.sqlserv ...
- vscode 同步扩展插件
第一步: 在 VSCode 中,安装用于同步配置的插件 settings sync 第二步:将 VSCode 配置上传到 GitHub 完成这一步需要 GitHub token 和 GitHu ...
- css3 伪类实现右箭头→
css3 实现右箭头→ <!DOCTYPE html> <html lang="en"> <head> <meta charset=&qu ...
- oracle数据库执行sql文件
使用oracle客户端连接数据库,从oracle官网下载客户端instantclient_18_3工具,到目录下打开cmd命令窗口: 个人网盘客户端工具:https://pan.baidu.com/s ...
- WPF炫酷UI及动画
偶然看见了一张图,感觉挺好看的,花了点时间将他转化成了我代码仓库的一部分.虽然不难但也费时间.其中除了背景是百度的一张底图,其他所有内容均通过WPF的Path.Line.TextBlock.Borde ...
- python面向对象-1
1.面向对象的思想优点 优点: 简化代码 ,构建公共模板 ,扩展性强 思想: 类作为模板 ,对象通过模板实例化对象 ,对象去做事 ,抽象将显示存在的事物使用代码体现 2.三大特性 封装(狭义) : 对 ...
- Dynamics CRM 2013开始推出的服务器端同步来配置邮件服务
我是微软Dynamics 365 & Power Platform方面的工程师罗勇,也是2015年7月到2018年6月连续三年Dynamics CRM/Business Solutions方面 ...