R期望
斐波那契数列--九九乘法表
# 1、 打印斐波那契数列
kl<-c(1,1)
for (i in 1:8){
kl[i+2]<-kl[i]+kl[i+1]
}
kl # 10、 打印九九乘法表
# R 输出函数
for (i in 1:9){
for (j in 1:i){
cat(i,"*",j,"=",i*j," ")
}
cat('\n')
}
R语言的输出:cat() print() paste() 输入:scan() readline()
期望值
#一个随机事件的期望值可以看做是某种加权平均值,
#它是该事件每一个可能结果乘以权值后所得结果的总和,
#权值对应每一个可能结果出现的概率
掷一个色子
#掷一个色子
#所有结果 1 2 3 4 5 6
#所对概率 1/6 1/6 1/6 1/6 1/6 1/6
E_roll<-1*1/6+2*1/6+3*1/6+4*1/6+5*1/6+6*1/6
E_roll
# 求均值
mean(1:6)

掷两个色子
#掷两个色子
#所有结果 36
#所对概率 1/36 #列出n个向量元素的所有组合
sz<-1:6
rolls<-expand.grid(sz,sz)
#添加var1的概率
rolls$prob1<-1/6
#添加var2的概率
rolls$prob2<-1/6
rolls
#添加总概率值
rolls$prob<-rolls$prob1*rolls$prob2
#添加value值
rolls$value<-rolls$Var1+rolls$Var2
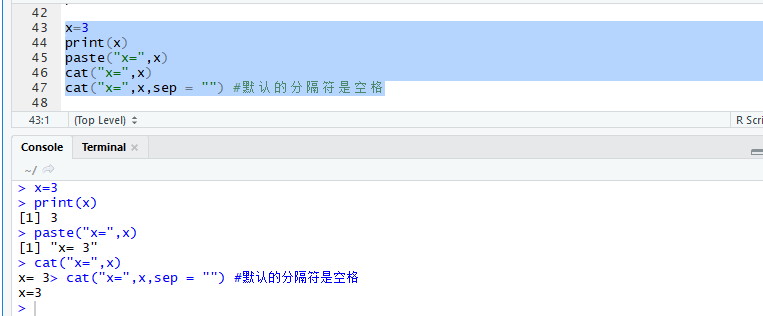
#计算期望值
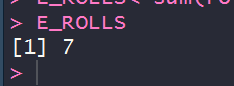
E_ROLLS<-sum(rolls$prob*rolls$value)
E_ROLLS
掷两个色子(作弊)
#1 2 3 4 5的概率为1/8
#6的概率为3/8
rolls1<-expand.grid(sz,sz)
#添加var1的概率
# 1/8 5次,3/8 1次
rolls1$prob1<-rep(c(1/8,3/8),c(5,1))
#添加var2的概率
rolls1$prob2<-rep(c(1/8,1/8,1/8,1/8,1/8,3/8),each=6)
#添加总概率
rolls1$prob<-rolls1$prob1*rolls1$prob2
#添加value值
rolls1$value<-rolls1$Var1+rolls1$Var2
#计算期望值
E_ROLLS1<-sum(rolls1$prob*rolls1$value)
E_ROLLS1
构建查找表和上面一样结果
#构建查找表
prob<-c(""=1/8,""=1/8,""=1/8,
""=1/8,""=1/8,""=3/8)
prob[1]
# 一次看多个值
prob[c(1,2,3,4,5,6)]
unname(prob[c(1,2,3,4,5,1,2,3,4,5,6)])
#添加var1的概率
rolls1$prob1<-prob[rolls1$Var1]
#添加var2的概率
rolls1$prob2<-prob[rolls1$Var2]
计算tiger机的期望值
7*7*7
wheel<-c("DD","","BBB","BB","B","C","")
combos<-expand.grid(wheel,wheel,wheel,
stringsAsFactors = F)
str(combos)
#构建查找表
prob <- c("DD"=0.03,""=0.03,"BBB"=0.06,
"BB"=0.1,"B"=0.25,"C"=0.01,""=0.52)
prob["DD"]
prob["C"]
#添加var1的概率 # prob[combos$Var1] 每个值对应的概率
combos$prob1<-unname(prob[combos$Var1])
#添加var2的概率
combos$prob2<-unname(prob[combos$Var2])
#添加var3的概率
combos$prob3<-unname(prob[combos$Var3])
#添加总概率
combos$prob<-combos$prob1*combos$prob2*combos$prob3
head(combos)
score(c("DD","DD","DD"))
#添加一列value
combos$value<-NA
combos[1,1]
combos[1,2]
combos[1,3]
c(combos[1,1],combos[1,2],combos[1,3])
score(c(combos[1,1],combos[1,2],combos[1,3]))
combos[1,"value"]<-score(c(combos[1,1],combos[1,2],combos[1,3]))
nrow(combos)
for (i in 1:343) {
combos[i,"value"]<-score(c(combos[i,1],combos[i,2],combos[i,3]))
}
head(combos)
tail(combos)
#计算期望值
E<-sum(combos$prob*combos$value)
E #验证期望值
sum(replicate(10,play()))
sum(replicate(100,play()))
sum(replicate(1000,play()))
sum(replicate(10000,play()))
R连接数据库
install.packages("RMySQL")
library(RMySQL)
#构造连接
conn<-dbConnect(MySQL(),user="root",
password="",dbname="db1")
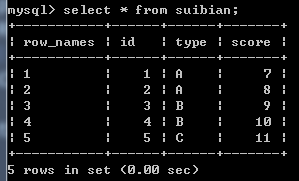
lizi<-data.frame(id=1:5,
type=c("A","A","B","B","C"),
score=7:11,
stringsAsFactors = F)
lizi
#把表写入数据库
dbWriteTable(conn,"suibian",lizi)
#关闭数据库
dbDisconnect(conn)
library(ggplot2)
data("diamonds",package = "ggplot2")
str(diamonds)
dbWriteTable(conn,"diamonds",diamonds,row.names=F)

Data Frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成
cbind: 根据列进行合并,即叠加所有列,m列的矩阵与n列的矩阵cbind()最后变成m+n列,合并前提:cbind(a, c)中矩阵a、c的行数必需相符 rbind: 根据行进行合并,就是行的叠加,m行的矩阵与n行的矩阵rbind()最后变成m+n行,合并前提:rbind(a, c)中矩阵a、c的列数必需相符
#定义资料集
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
s1 = pd.Series([1,2,3,4], index=['a','b','c','d']) #将df2合并到df1的下面,以及重置index,并打印出结果
res = df1.append(df2, ignore_index=True)
print(res)
a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
#合并多个df,将df2与df3合并至df1的下面,以及重置index,并打印出结果
res = df1.append([df2, df3], ignore_index=True)
作业:构造6个数据框,每个数据框分别有三个变量,
#追加数据:append
#作业:构造6个数据框,每个数据框分别有三个变量,
#id、type、score
#id:是0-9,10-19,20-29……
#type:"A","B","C"……
#score:长度为10的随机数
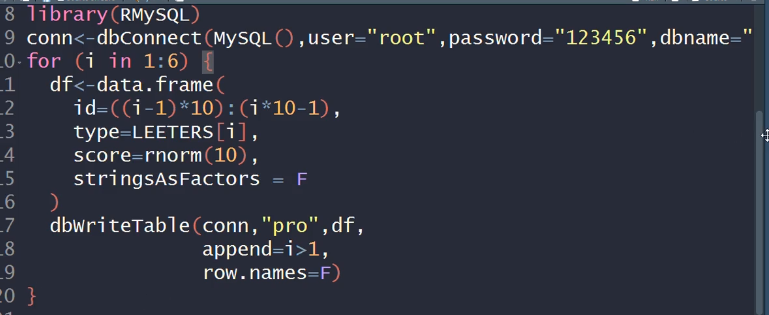
#把这6个数据框写到一张表里,表名:pro install.packages("RMySQL")
library(RMySQL)
#构造连接
conn<-dbConnect(MySQL(),user="root",
password="",dbname="db1") a1<-data.frame(id=0:9,type=LETTERS[1:10],score=rnorm(10))
a2<-data.frame(id=10:19,type=LETTERS[1:10],score=rnorm(10))
a3<-data.frame(id=20:29,type=LETTERS[1:10],score=rnorm(10))
a4<-data.frame(id=30:39,type=LETTERS[1:10],score=rnorm(10))
a5<-data.frame(id=40:49,type=LETTERS[1:10],score=rnorm(10))
a6<-data.frame(id=50:59,type=LETTERS[1:10],score=rnorm(10))
s<-rbind(a1,a2,a3,a4,a5,a6) #把表写入数据库
dbWriteTable(conn,"pro",s)
#关闭数据库
dbDisconnect(conn)

-----------
1122
#生成随机数
rnorm(10) #查看数据库中有没有一张特定的表
dbExistsTable(conn,"diamonds") #列出当前的数据库中有哪些表
dbListTables(conn) #列出表中的字段
dbListFields(conn,"diamonds") #读取表的数据
db_df<-dbReadTable(conn,"course")
db_df
提取数据到R里
#提取数据到R里
dbGetQuery() #查看数据集的摘要统计量
summary(diamonds) #1.查询cut切工的类别
dbGetQuery(conn,"select distinct cut from diamonds") #2.查询克拉、价格、大小(size),size用x*y*z来表示
db_diamonds<-dbGetQuery(conn,"select carat,price,x*y*z as size from diamonds")
head(db_diamonds) #3.查询克拉、切工、颜色、价格,切工是Good,颜色是E
good_e_diamonds<-dbGetQuery(conn,"select carat,cut,color,price from diamonds where cut='Good' and color='E'")
head(good_e_diamonds)
111
R期望的更多相关文章
- Maximum Random Walk(概率dp)
题意: 走n步,给出每步向左走概率l,向右走概率r,留在原地的概率 1-l-r,求能达到的最远右边距离的期望. 分析: 开始按期望逆求的方式分析,但让求的就是右边界没法退,懵了一会,既然逆着不能求,就 ...
- Scyther-Semantics and verification of Security Protocol
1 .本书前一节主要是介作者自己的生平经历(读完感觉作者是个神童),目标明确作者13岁代码已经写的很溜了.自己也开了网络公司,但是后面又专注于自己的计算机基础理论,修了哲学的博士学位(不得不说很多专业 ...
- CF963E Circles of Waiting
Circles of Waiting 求一个整点四连通随机游⾛,离原点距离超过R期望步数.R≤50. 带状矩阵法 本质上就是网格图的随机游走. \[ E_x=\sum_y P_{x,y}E_y+1 \ ...
- [原]CentOS7安装Rancher2.1并部署kubernetes (二)---部署kubernetes
################## Rancher v2.1.7 + Kubernetes 1.13.4 ################ ##################### ...
- 利用python进行数据分析2_数据采集与操作
txt_filename = './files/python_baidu.txt' # 打开文件 file_obj = open(txt_filename, 'r', encoding='utf-8' ...
- Django项目:CRM(客户关系管理系统)--81--71PerfectCRM实现CRM项目首页
{#portal.html#} {## ————————46PerfectCRM实现登陆后页面才能访问————————#} {#{% extends 'king_admin/table_index.h ...
- 神经网络模型及R代码实现
神经网络基本原理 一.神经元模型 图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j到神经元i的连接权值,θ表示一个阈值 ( threshold ),或称为偏置( bias ).则神 ...
- 用R语言的quantreg包进行分位数回归
什么是分位数回归 分位数回归(Quantile Regression)是计量经济学的研究前沿方向之一,它利用解释变量的多个分位数(例如四分位.十分位.百分位等)来得到被解释变量的条件分布的相应的分位数 ...
- UVA&&POJ离散概率与数学期望入门练习[4]
POJ3869 Headshot 题意:给出左轮手枪的子弹序列,打了一枪没子弹,要使下一枪也没子弹概率最大应该rotate还是shoot 条件概率,|00|/(|00|+|01|)和|0|/n谁大的问 ...
随机推荐
- USB3.0之高速视频传输测试 双目相机(mt9p031、mt9m001)带宽高达300M测试 配合isensor测试 500万像素15fps
最近完善了下USB3.0的视频开发测试,主要优化了FPGA程序和固件,及其同步方式.对带宽和图像效果进行了仔细的测试 开发板架构(2CMOS+FPGA+2DDR2+USB3.0) 评估板底板配合2个M ...
- 你不知道的JavaScript(上)this和对象原型(三)
第四章 混核对象“类” 1.理论 面向对象编程强调的是数据和操作数据的行为本质上是互相关联的.实例化,继承,多态性 javascript中只有对象,并不存在可以被实例化的“类”.一个对象并不会被复制 ...
- JS基础知识——原型与原型链
1.如何准确判断一个变量的数组类型 2.写一个原型链继承的例子 3.描述new一个对象的过程 4.zepto(或其他框架中如何使用原型链) 知识点: (1)构造函数 function Foo(name ...
- 使用SQL语句修改Mysql数据库字符集的方法
使用SQL语句修改Mysql数据库字符集的方法 修改库: alter database [$database] character set [$character_set] collate [$c ...
- JS---DOM---事件冒泡和阻止事件冒泡,总结事件
事件冒泡: 多个元素嵌套, 有层次关系 ,这些元素都注册了相同的事件, 如果里面的元素的事件触发了, 外面的元素的该事件自动的触发了 事件有三个阶段: 1.事件捕获阶段 :从外向内 2.事件 ...
- 3.Android-ADT之helloworld项目结构介绍
1.helloworld项目结构如下图所示: src 放项目的源代码的.而MainActivity.java文件则对应helloworld界面代码,代码如下所示: gen BuildConfig.ja ...
- Windows系统下解决PhPStudy MySQL启动失败
报错 Apache\Nginx服务正常启动了,但是MySQL却一直启动失败. 解决流程 查看端口是否被占用 打开系统自带的资源管理器,查看监听端口3306是不是被占用,下图中3306端口被mysqld ...
- WebAPI接口测试数据库操作
通常我们是不建议直接查看数据库内容来检查功能的,但是在没有外部接口或者图形界面验证的情况下,只能通过查询数据库来验证. 比如我们手工需要从界面上添加一万条数据,估计要花好几天时间,显然不能手工去操作. ...
- Codeforces Round #608 (Div. 2) 题解
目录 Codeforces Round #608 (Div. 2) 题解 前言 A. Suits 题意 做法 程序 B. Blocks 题意 做法 程序 C. Shawarma Tent 题意 做法 ...
- MyBatis结果集一对多映射
MyBatis结果集一对多映射 需求:重画二维码配置类,根据sizeCode将查询出来的imageCode分组. DROP TABLE IF EXISTS `size_code`; CREATE TA ...