利用sklearn对多分类的每个类别进行指标评价
今天晚上,笔者接到客户的一个需要,那就是:对多分类结果的每个类别进行指标评价,也就是需要输出每个类型的精确率(precision),召回率(recall)以及F1值(F1-score)。
对于这个需求,我们可以用sklearn来解决,方法并没有难,笔者在此仅做记录,供自己以后以及读者参考。
我们模拟的数据如下:
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
其中y_true为真实数据,y_pred为多分类后的模拟数据。使用sklearn.metrics中的classification_report即可实现对多分类的每个类别进行指标评价。
示例的Python代码如下:
# -*- coding: utf-8 -*-
from sklearn.metrics import classification_report
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
t = classification_report(y_true, y_pred, target_names=['北京', '上海', '成都'])
print(t)
输出结果如下:
precision recall f1-score support
北京 0.75 0.75 0.75 4
上海 1.00 0.67 0.80 3
成都 0.50 0.67 0.57 3
accuracy 0.70 10
macro avg 0.75 0.69 0.71 10
weighted avg 0.75 0.70 0.71 10
需要注意的是,输出的结果数据类型为str,如果需要使用该输出结果,则可将该方法中的output_dict参数设置为True,此时输出的结果如下:
{'北京': {'precision': 0.75, 'recall': 0.75, 'f1-score': 0.75, 'support': 4},
'上海': {'precision': 1.0, 'recall': 0.6666666666666666, 'f1-score': 0.8, 'support': 3},
'成都': {'precision': 0.5, 'recall': 0.6666666666666666, 'f1-score': 0.5714285714285715, 'support': 3},
'accuracy': 0.7,
'macro avg': {'precision': 0.75, 'recall': 0.6944444444444443, 'f1-score': 0.7071428571428572, 'support': 10},
'weighted avg': {'precision': 0.75, 'recall': 0.7, 'f1-score': 0.7114285714285715, 'support': 10}}
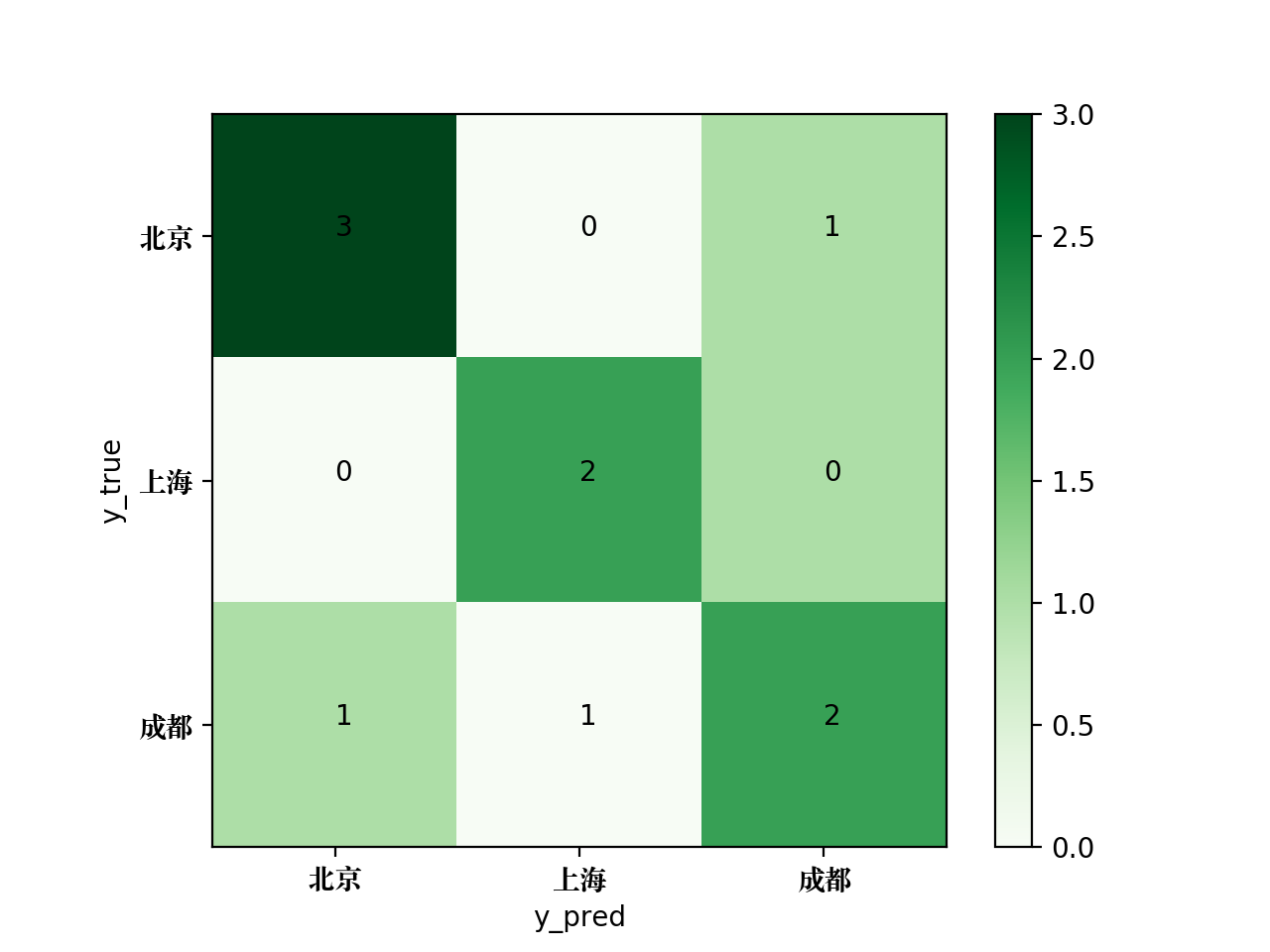
使用confusion_matrix方法可以输出该多分类问题的混淆矩阵,代码如下:
from sklearn.metrics import confusion_matrix
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
print(confusion_matrix(y_true, y_pred, labels = ['北京', '上海', '成都']))
输出结果如下:
[[2 0 1]
[0 3 1]
[0 1 2]]
为了将该混淆矩阵绘制成图片,可使用如下的Python代码:
# -*- coding: utf-8 -*-
# author: Jclian91
# place: Daxing Beijing
# time: 2019-11-14 21:52
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import matplotlib as mpl
# 支持中文字体显示, 使用于Mac系统
zhfont=mpl.font_manager.FontProperties(fname="/Library/Fonts/Songti.ttc")
y_true = ['北京', '上海', '成都', '成都', '上海', '北京', '上海', '成都', '北京', '上海']
y_pred = ['北京', '上海', '成都', '上海', '成都', '成都', '上海', '成都', '北京', '上海']
classes = ['北京', '上海', '成都']
confusion = confusion_matrix(y_true, y_pred)
# 绘制热度图
plt.imshow(confusion, cmap=plt.cm.Greens)
indices = range(len(confusion))
plt.xticks(indices, classes, fontproperties=zhfont)
plt.yticks(indices, classes, fontproperties=zhfont)
plt.colorbar()
plt.xlabel('y_pred')
plt.ylabel('y_true')
# 显示数据
for first_index in range(len(confusion)):
for second_index in range(len(confusion[first_index])):
plt.text(first_index, second_index, confusion[first_index][second_index])
# 显示图片
plt.show()
生成的混淆矩阵图片如下:
本次分享到此结束,感谢大家阅读,也感谢在北京大兴待的这段日子,当然还会再待一阵子~
利用sklearn对多分类的每个类别进行指标评价的更多相关文章
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 利用Sklearn实现加州房产价格预测,学习运用机器学习的整个流程(包含很多细节注解)
Chapter1_housing_price_predict .caret, .dropup > .btn > .caret { border-top-color: #000 !impor ...
- 利用sklearn实现k-means
基于上面的一篇博客k-means利用sklearn实现k-means #!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np ...
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
- sklearn CART决策树分类
sklearn CART决策树分类 决策树是一种常用的机器学习方法,可以用于分类和回归.同时,决策树的训练结果非常容易理解,而且对于数据预处理的要求也不是很高. 理论部分 比较经典的决策树是ID3.C ...
- OC分类(类目/类别) 和 类扩展 - 全解析
OC分类(类目/类别) 和 类扩展 - 全解析 具体见: oschina -> MyDemo -> 011.FoundationLog-OC分类剖析 http://blog.csdn. ...
- sklearn特征选择和分类模型
sklearn特征选择和分类模型 数据格式: 这里.原始特征的输入文件的格式使用libsvm的格式,即每行是label index1:value1 index2:value2这样的稀疏矩阵的格式. s ...
- Flutter实战视频-移动电商-21.分类页_类别信息接口调试
21.分类页_类别信息接口调试 先解决一个坑 取消上面的GridVIew的回弹效果.就是在拖这个gridview的时候有一个滚动的效果 physics: NeverScrollableScrollPh ...
- sklearn实现多分类逻辑回归
sklearn实现多分类逻辑回归 #二分类逻辑回归算法改造适用于多分类问题1.对于逻辑回归算法主要是用回归的算法解决分类的问题,它只能解决二分类的问题,不过经过一定的改造便可以进行多分类问题,主要的改 ...
随机推荐
- python3 之 变量作用域详解
作用域: 指命名空间可直接访问的python程序的文本区域,这里的 ‘可直接访问’ 意味着:对名称的引用(非限定),会尝试在命名空间中查找名称: L:local,局部作用域,即函数中定义的变量: E: ...
- Scrapy中的反反爬、logging设置、Request参数及POST请求
常用的反反爬策略 通常防止爬虫被反主要有以下几策略: 动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息.) 禁用cookies(也就是不启用cookies midd ...
- pymongo的基本操作和使用
MongoDB简介 MongoDB是一个开源的文档类型数据库,它具有高性能,高可用,可自动收缩的特性.MongoDB能够避免传统的ORM映射从而有助于开发. 文档 在MongoDB中,一行纪录就是一个 ...
- ctf比赛linux文件监控和恢复shell
之前参加ctf比赛时候临时写的,有很多不足,不过可以用,就贴出来分享给大家,希望对大家有帮助. 脚本一:记录当前目录情况 #!/bin/bashfunction getdir(){ for el ...
- Spring Security(二)--WebSecurityConfigurer配置以及filter顺序
“致"高级"工程师(BUG工程师) 一颗折腾的心
- Spring Boot中使用Jpa的findOne方法不能传入id
最近通过慕课网学习spring boot,视频中通过jpa的findOne方法以id为参数查询出对应的信息, 而当我自己做测试的时候却发现我的findOne方法的参数没有Integer类型的id,而是 ...
- pngquant——一个好用的png压缩工具
一个可以进行有损图片压缩的命令行工具和代码库. 网址:https://pngquant.org/ 1.为什么选择pngquant 传说中的神器——tinyPng 我们现在用的工具——ImageAlph ...
- 翻转二叉树(深搜-先序遍历-交换Node)
题目:翻转二叉树,例如 4 / \ 2 7 / \ / \ 1 3 6 9 to 4 / \ 7 2 / \ / \ 9 6 3 1 已知二叉树的节点定义如下: class TreeNode { in ...
- ios宏定义应该呆在恰当的地方
项目为了看起来整洁 并减少不必要的多次拼写 我们会把这样的方法 做成宏定义 那么问题来了 很多文件同时用到一个或多个宏定义 写完之后就会变成这个样子 看起来很乱 阅读性也不好 那么问题来了怎么解决嘞 ...
- [TimLinux] JavaScript 模态框可拖动功能实现——原始版
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...