MobileNet V2深入理解
转载:https://zhuanlan.zhihu.com/p/33075914 MobileNet V2 论文初读
转载:https://blog.csdn.net/wfei101/article/details/79334659 网络模型压缩和优化:MobileNet V2网络结构理解
转载: https://zhuanlan.zhihu.com/p/50045821 mobilenetv1和mobilenetv2的区别
MobileNetV2: Inverted Residuals and Linear Bottlenecks:连接:https://128.84.21.199/pdf/1801.04381.pdf
MobileNet v1中使用的Depthwise Separable Convolution是模型压缩的一个最为经典的策略,它是通过将跨通道的 卷积换成单通道的
卷积+跨通道的
卷积来达到此目的的。
MobileNet V2主要的改进有两点:
1、Linear Bottlenecks。因为ReLU的在通道数较少的Feature Map上有非常严重信息损失问题,所以去掉了小维度输出层后面的非线性激活层ReLU,保留更多的特征信息,目的是为了保证模型的表达能力。
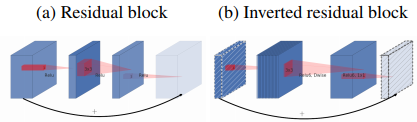
2、Inverted Residual block。该结构和传统residual block中维度先缩减再扩增正好相反,因此shotcut也就变成了连接的是维度缩减后的feature map。
相同点:
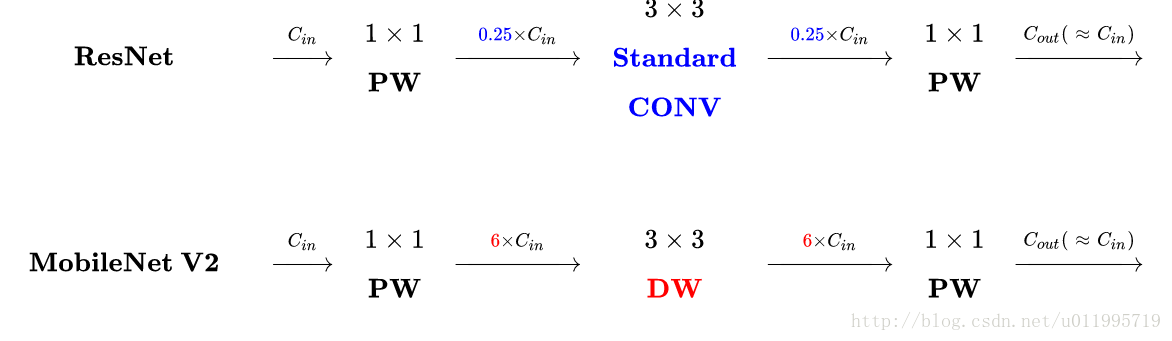
- 都采用 Depth-wise (DW) 卷积搭配 Point-wise (PW) 卷积的方式来提特征。这两个操作合起来也被称为 Depth-wise Separable Convolution,之前在 Xception 中被广泛使用。这么做的好处是理论上可以成倍的减少卷积层的时间复杂度和空间复杂度。由下式可知,因为卷积核的尺寸
通常远小于输出通道数
,因此标准卷积的计算复杂度近似为 DW + PW 组合卷积的
倍。由于Depthwise卷积的每个通道Feature Map产生且仅产生一个与之对应的Feature Map,也就是说输出层的Feature Map的channel数量等于输入层的Feature map的数量。因此
DepthwiseConv不需要控制输出层的Feature Map的数量,因此并没有num_filters 这个参数,这个参数是和输入特征的channels数相等。
standard Convolution运算量:3*3跨通道运算 C*(C*(K**2)*x),其中x为一个kernel核在一个一维的输入特征上运算需要滑动的次数,这里假设卷积核个数和输入通道数都是C;
Depth-wise Separable Convolution运算量:单通道运算(C*(K**2)*x)+ 跨通道1*1卷积 C*(C*(1**2)*x),,其中x为一个kernel核在一个一维的输入特征上运算需要滑动的次数,这里假设卷积核个数和输入通道数都是C;
Depthwise卷积示意图(3个通道)
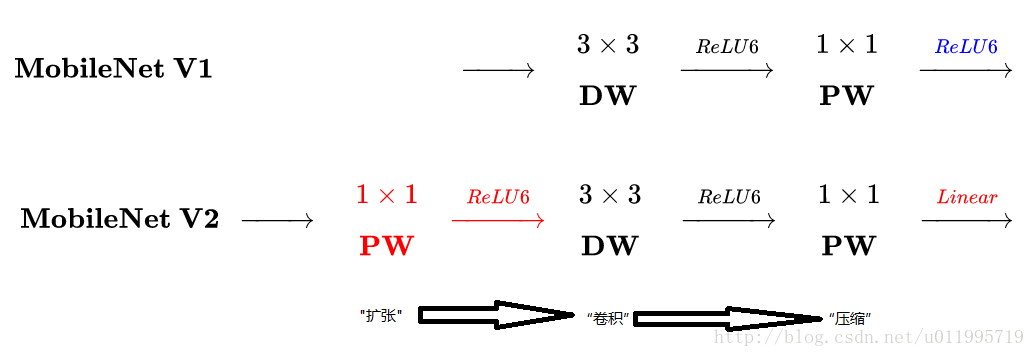
主要创新点:
1,Inverted residuals:V2 在 DW 卷积之前新加了一个 1*1 大小PW 卷积。这么做的原因,是因为 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。所以如果上一层给的通道数本身很少的话,DW 也只能很委屈的在低维空间提特征,因此效果不够好。现在 V2 为了改善这个问题,给每个 DW 之前都配备了一个 PW,专门用来升维,定义升维系数 t(而在v2中这个值一般是介于 之间的数,在作者的实验中,
),这样不管输入通道数
是多是少,经过第一个 PW 升维之后,DW 都是在相对的更高维 (
) 进行着辛勤工作的。主要也是为了提取更多的通道信息,得到更多的特征线信息。
2,Linear bottlenecks:V2 去掉了第二个 PW 的激活函数,意思就是bottleneck的输出不接非线性激活层。论文作者称其为 Linear Bottleneck。这么做的原因,是因为作者认为激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于第二个 PW 的主要功能就是降维,因此按照上面的理论,降维之后就不宜再使用 ReLU6 了。
再看看MobileNetV2的block 与ResNet 的block:主要不同之处就在于,ResNet是:压缩”→“卷积提特征”→“扩张”,MobileNetV2则是Inverted residuals, 即:“扩张”→“卷积提特征”→ “压缩
具体mobilenetV2的宏观结构如下:t表示每个bottleneck的PW层的expand系数,也就是channels扩张系数,
c表示每个bottleneck的输出通道数,也就是每个bottleneck输出的PW的channels数,用于降维,
n表示有多少个bottleneck连接在一起,s表示第一个bottleneck的DW层的stride,表示下采样;

附上mobilenetv2的源码,可以通过netscope: https://ethereon.github.io/netscope/#/editor查看:

name: "MOBILENET_V2"
layer {
name: "data"
type: "ImageData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size:
}
image_data_param {
source: "./train.txt"
batch_size:
shuffle: false
}
}
layer {
name: "data"
type: "ImageData"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size:
}
image_data_param {
source: "./valid.txt"
batch_size:
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
stride:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv1/bn"
type: "BatchNorm"
bottom: "conv1"
top: "conv1/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv1/scale"
type: "Scale"
bottom: "conv1/bn"
top: "conv1/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1/bn"
top: "conv1/bn"
}
layer {
name: "conv2_1/expand"
type: "Convolution"
bottom: "conv1/bn"
top: "conv2_1/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv2_1/expand/bn"
type: "BatchNorm"
bottom: "conv2_1/expand"
top: "conv2_1/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv2_1/expand/scale"
type: "Scale"
bottom: "conv2_1/expand/bn"
top: "conv2_1/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu2_1/expand"
type: "ReLU"
bottom: "conv2_1/expand/bn"
top: "conv2_1/expand/bn"
}
layer {
name: "conv2_1/dwise"
type: "Convolution"
bottom: "conv2_1/expand/bn"
top: "conv2_1/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv2_1/dwise/bn"
type: "BatchNorm"
bottom: "conv2_1/dwise"
top: "conv2_1/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv2_1/dwise/scale"
type: "Scale"
bottom: "conv2_1/dwise/bn"
top: "conv2_1/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu2_1/dwise"
type: "ReLU"
bottom: "conv2_1/dwise/bn"
top: "conv2_1/dwise/bn"
}
layer {
name: "conv2_1/linear"
type: "Convolution"
bottom: "conv2_1/dwise/bn"
top: "conv2_1/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv2_1/linear/bn"
type: "BatchNorm"
bottom: "conv2_1/linear"
top: "conv2_1/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv2_1/linear/scale"
type: "Scale"
bottom: "conv2_1/linear/bn"
top: "conv2_1/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv2_2/expand"
type: "Convolution"
bottom: "conv2_1/linear/bn"
top: "conv2_2/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv2_2/expand/bn"
type: "BatchNorm"
bottom: "conv2_2/expand"
top: "conv2_2/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv2_2/expand/scale"
type: "Scale"
bottom: "conv2_2/expand/bn"
top: "conv2_2/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu2_2/expand"
type: "ReLU"
bottom: "conv2_2/expand/bn"
top: "conv2_2/expand/bn"
}
layer {
name: "conv2_2/dwise"
type: "Convolution"
bottom: "conv2_2/expand/bn"
top: "conv2_2/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
stride:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv2_2/dwise/bn"
type: "BatchNorm"
bottom: "conv2_2/dwise"
top: "conv2_2/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv2_2/dwise/scale"
type: "Scale"
bottom: "conv2_2/dwise/bn"
top: "conv2_2/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu2_2/dwise"
type: "ReLU"
bottom: "conv2_2/dwise/bn"
top: "conv2_2/dwise/bn"
}
layer {
name: "conv2_2/linear"
type: "Convolution"
bottom: "conv2_2/dwise/bn"
top: "conv2_2/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv2_2/linear/bn"
type: "BatchNorm"
bottom: "conv2_2/linear"
top: "conv2_2/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv2_2/linear/scale"
type: "Scale"
bottom: "conv2_2/linear/bn"
top: "conv2_2/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv3_1/expand"
type: "Convolution"
bottom: "conv2_2/linear/bn"
top: "conv3_1/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv3_1/expand/bn"
type: "BatchNorm"
bottom: "conv3_1/expand"
top: "conv3_1/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv3_1/expand/scale"
type: "Scale"
bottom: "conv3_1/expand/bn"
top: "conv3_1/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu3_1/expand"
type: "ReLU"
bottom: "conv3_1/expand/bn"
top: "conv3_1/expand/bn"
}
layer {
name: "conv3_1/dwise"
type: "Convolution"
bottom: "conv3_1/expand/bn"
top: "conv3_1/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv3_1/dwise/bn"
type: "BatchNorm"
bottom: "conv3_1/dwise"
top: "conv3_1/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv3_1/dwise/scale"
type: "Scale"
bottom: "conv3_1/dwise/bn"
top: "conv3_1/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu3_1/dwise"
type: "ReLU"
bottom: "conv3_1/dwise/bn"
top: "conv3_1/dwise/bn"
}
layer {
name: "conv3_1/linear"
type: "Convolution"
bottom: "conv3_1/dwise/bn"
top: "conv3_1/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv3_1/linear/bn"
type: "BatchNorm"
bottom: "conv3_1/linear"
top: "conv3_1/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv3_1/linear/scale"
type: "Scale"
bottom: "conv3_1/linear/bn"
top: "conv3_1/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_3_1"
type: "Eltwise"
bottom: "conv2_2/linear/bn"
bottom: "conv3_1/linear/bn"
top: "block_3_1"
}
layer {
name: "conv3_2/expand"
type: "Convolution"
bottom: "block_3_1"
top: "conv3_2/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv3_2/expand/bn"
type: "BatchNorm"
bottom: "conv3_2/expand"
top: "conv3_2/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv3_2/expand/scale"
type: "Scale"
bottom: "conv3_2/expand/bn"
top: "conv3_2/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu3_2/expand"
type: "ReLU"
bottom: "conv3_2/expand/bn"
top: "conv3_2/expand/bn"
}
layer {
name: "conv3_2/dwise"
type: "Convolution"
bottom: "conv3_2/expand/bn"
top: "conv3_2/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
stride:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv3_2/dwise/bn"
type: "BatchNorm"
bottom: "conv3_2/dwise"
top: "conv3_2/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv3_2/dwise/scale"
type: "Scale"
bottom: "conv3_2/dwise/bn"
top: "conv3_2/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu3_2/dwise"
type: "ReLU"
bottom: "conv3_2/dwise/bn"
top: "conv3_2/dwise/bn"
}
layer {
name: "conv3_2/linear"
type: "Convolution"
bottom: "conv3_2/dwise/bn"
top: "conv3_2/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv3_2/linear/bn"
type: "BatchNorm"
bottom: "conv3_2/linear"
top: "conv3_2/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv3_2/linear/scale"
type: "Scale"
bottom: "conv3_2/linear/bn"
top: "conv3_2/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv4_1/expand"
type: "Convolution"
bottom: "conv3_2/linear/bn"
top: "conv4_1/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_1/expand/bn"
type: "BatchNorm"
bottom: "conv4_1/expand"
top: "conv4_1/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_1/expand/scale"
type: "Scale"
bottom: "conv4_1/expand/bn"
top: "conv4_1/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_1/expand"
type: "ReLU"
bottom: "conv4_1/expand/bn"
top: "conv4_1/expand/bn"
}
layer {
name: "conv4_1/dwise"
type: "Convolution"
bottom: "conv4_1/expand/bn"
top: "conv4_1/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_1/dwise/bn"
type: "BatchNorm"
bottom: "conv4_1/dwise"
top: "conv4_1/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_1/dwise/scale"
type: "Scale"
bottom: "conv4_1/dwise/bn"
top: "conv4_1/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_1/dwise"
type: "ReLU"
bottom: "conv4_1/dwise/bn"
top: "conv4_1/dwise/bn"
}
layer {
name: "conv4_1/linear"
type: "Convolution"
bottom: "conv4_1/dwise/bn"
top: "conv4_1/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_1/linear/bn"
type: "BatchNorm"
bottom: "conv4_1/linear"
top: "conv4_1/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_1/linear/scale"
type: "Scale"
bottom: "conv4_1/linear/bn"
top: "conv4_1/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_4_1"
type: "Eltwise"
bottom: "conv3_2/linear/bn"
bottom: "conv4_1/linear/bn"
top: "block_4_1"
}
layer {
name: "conv4_2/expand"
type: "Convolution"
bottom: "block_4_1"
top: "conv4_2/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_2/expand/bn"
type: "BatchNorm"
bottom: "conv4_2/expand"
top: "conv4_2/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_2/expand/scale"
type: "Scale"
bottom: "conv4_2/expand/bn"
top: "conv4_2/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_2/expand"
type: "ReLU"
bottom: "conv4_2/expand/bn"
top: "conv4_2/expand/bn"
}
layer {
name: "conv4_2/dwise"
type: "Convolution"
bottom: "conv4_2/expand/bn"
top: "conv4_2/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_2/dwise/bn"
type: "BatchNorm"
bottom: "conv4_2/dwise"
top: "conv4_2/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_2/dwise/scale"
type: "Scale"
bottom: "conv4_2/dwise/bn"
top: "conv4_2/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_2/dwise"
type: "ReLU"
bottom: "conv4_2/dwise/bn"
top: "conv4_2/dwise/bn"
}
layer {
name: "conv4_2/linear"
type: "Convolution"
bottom: "conv4_2/dwise/bn"
top: "conv4_2/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_2/linear/bn"
type: "BatchNorm"
bottom: "conv4_2/linear"
top: "conv4_2/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_2/linear/scale"
type: "Scale"
bottom: "conv4_2/linear/bn"
top: "conv4_2/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_4_2"
type: "Eltwise"
bottom: "block_4_1"
bottom: "conv4_2/linear/bn"
top: "block_4_2"
}
layer {
name: "conv4_3/expand"
type: "Convolution"
bottom: "block_4_2"
top: "conv4_3/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_3/expand/bn"
type: "BatchNorm"
bottom: "conv4_3/expand"
top: "conv4_3/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_3/expand/scale"
type: "Scale"
bottom: "conv4_3/expand/bn"
top: "conv4_3/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_3/expand"
type: "ReLU"
bottom: "conv4_3/expand/bn"
top: "conv4_3/expand/bn"
}
layer {
name: "conv4_3/dwise"
type: "Convolution"
bottom: "conv4_3/expand/bn"
top: "conv4_3/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_3/dwise/bn"
type: "BatchNorm"
bottom: "conv4_3/dwise"
top: "conv4_3/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_3/dwise/scale"
type: "Scale"
bottom: "conv4_3/dwise/bn"
top: "conv4_3/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_3/dwise"
type: "ReLU"
bottom: "conv4_3/dwise/bn"
top: "conv4_3/dwise/bn"
}
layer {
name: "conv4_3/linear"
type: "Convolution"
bottom: "conv4_3/dwise/bn"
top: "conv4_3/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_3/linear/bn"
type: "BatchNorm"
bottom: "conv4_3/linear"
top: "conv4_3/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_3/linear/scale"
type: "Scale"
bottom: "conv4_3/linear/bn"
top: "conv4_3/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv4_4/expand"
type: "Convolution"
bottom: "conv4_3/linear/bn"
top: "conv4_4/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_4/expand/bn"
type: "BatchNorm"
bottom: "conv4_4/expand"
top: "conv4_4/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_4/expand/scale"
type: "Scale"
bottom: "conv4_4/expand/bn"
top: "conv4_4/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_4/expand"
type: "ReLU"
bottom: "conv4_4/expand/bn"
top: "conv4_4/expand/bn"
}
layer {
name: "conv4_4/dwise"
type: "Convolution"
bottom: "conv4_4/expand/bn"
top: "conv4_4/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_4/dwise/bn"
type: "BatchNorm"
bottom: "conv4_4/dwise"
top: "conv4_4/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_4/dwise/scale"
type: "Scale"
bottom: "conv4_4/dwise/bn"
top: "conv4_4/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_4/dwise"
type: "ReLU"
bottom: "conv4_4/dwise/bn"
top: "conv4_4/dwise/bn"
}
layer {
name: "conv4_4/linear"
type: "Convolution"
bottom: "conv4_4/dwise/bn"
top: "conv4_4/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_4/linear/bn"
type: "BatchNorm"
bottom: "conv4_4/linear"
top: "conv4_4/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_4/linear/scale"
type: "Scale"
bottom: "conv4_4/linear/bn"
top: "conv4_4/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_4_4"
type: "Eltwise"
bottom: "conv4_3/linear/bn"
bottom: "conv4_4/linear/bn"
top: "block_4_4"
}
layer {
name: "conv4_5/expand"
type: "Convolution"
bottom: "block_4_4"
top: "conv4_5/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_5/expand/bn"
type: "BatchNorm"
bottom: "conv4_5/expand"
top: "conv4_5/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_5/expand/scale"
type: "Scale"
bottom: "conv4_5/expand/bn"
top: "conv4_5/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_5/expand"
type: "ReLU"
bottom: "conv4_5/expand/bn"
top: "conv4_5/expand/bn"
}
layer {
name: "conv4_5/dwise"
type: "Convolution"
bottom: "conv4_5/expand/bn"
top: "conv4_5/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_5/dwise/bn"
type: "BatchNorm"
bottom: "conv4_5/dwise"
top: "conv4_5/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_5/dwise/scale"
type: "Scale"
bottom: "conv4_5/dwise/bn"
top: "conv4_5/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_5/dwise"
type: "ReLU"
bottom: "conv4_5/dwise/bn"
top: "conv4_5/dwise/bn"
}
layer {
name: "conv4_5/linear"
type: "Convolution"
bottom: "conv4_5/dwise/bn"
top: "conv4_5/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_5/linear/bn"
type: "BatchNorm"
bottom: "conv4_5/linear"
top: "conv4_5/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_5/linear/scale"
type: "Scale"
bottom: "conv4_5/linear/bn"
top: "conv4_5/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_4_5"
type: "Eltwise"
bottom: "block_4_4"
bottom: "conv4_5/linear/bn"
top: "block_4_5"
}
layer {
name: "conv4_6/expand"
type: "Convolution"
bottom: "block_4_5"
top: "conv4_6/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_6/expand/bn"
type: "BatchNorm"
bottom: "conv4_6/expand"
top: "conv4_6/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_6/expand/scale"
type: "Scale"
bottom: "conv4_6/expand/bn"
top: "conv4_6/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_6/expand"
type: "ReLU"
bottom: "conv4_6/expand/bn"
top: "conv4_6/expand/bn"
}
layer {
name: "conv4_6/dwise"
type: "Convolution"
bottom: "conv4_6/expand/bn"
top: "conv4_6/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_6/dwise/bn"
type: "BatchNorm"
bottom: "conv4_6/dwise"
top: "conv4_6/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_6/dwise/scale"
type: "Scale"
bottom: "conv4_6/dwise/bn"
top: "conv4_6/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_6/dwise"
type: "ReLU"
bottom: "conv4_6/dwise/bn"
top: "conv4_6/dwise/bn"
}
layer {
name: "conv4_6/linear"
type: "Convolution"
bottom: "conv4_6/dwise/bn"
top: "conv4_6/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_6/linear/bn"
type: "BatchNorm"
bottom: "conv4_6/linear"
top: "conv4_6/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_6/linear/scale"
type: "Scale"
bottom: "conv4_6/linear/bn"
top: "conv4_6/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_4_6"
type: "Eltwise"
bottom: "block_4_5"
bottom: "conv4_6/linear/bn"
top: "block_4_6"
}
layer {
name: "conv4_7/expand"
type: "Convolution"
bottom: "block_4_6"
top: "conv4_7/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_7/expand/bn"
type: "BatchNorm"
bottom: "conv4_7/expand"
top: "conv4_7/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_7/expand/scale"
type: "Scale"
bottom: "conv4_7/expand/bn"
top: "conv4_7/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu4_7/expand"
type: "ReLU"
bottom: "conv4_7/expand/bn"
top: "conv4_7/expand/bn"
}
layer {
name: "conv4_7/dwise"
type: "Convolution"
bottom: "conv4_7/expand/bn"
top: "conv4_7/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
stride:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv4_7/dwise/bn"
type: "BatchNorm"
bottom: "conv4_7/dwise"
top: "conv4_7/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_7/dwise/scale"
type: "Scale"
bottom: "conv4_7/dwise/bn"
top: "conv4_7/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu4_7/dwise"
type: "ReLU"
bottom: "conv4_7/dwise/bn"
top: "conv4_7/dwise/bn"
}
layer {
name: "conv4_7/linear"
type: "Convolution"
bottom: "conv4_7/dwise/bn"
top: "conv4_7/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv4_7/linear/bn"
type: "BatchNorm"
bottom: "conv4_7/linear"
top: "conv4_7/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv4_7/linear/scale"
type: "Scale"
bottom: "conv4_7/linear/bn"
top: "conv4_7/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv5_1/expand"
type: "Convolution"
bottom: "conv4_7/linear/bn"
top: "conv5_1/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv5_1/expand/bn"
type: "BatchNorm"
bottom: "conv5_1/expand"
top: "conv5_1/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_1/expand/scale"
type: "Scale"
bottom: "conv5_1/expand/bn"
top: "conv5_1/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu5_1/expand"
type: "ReLU"
bottom: "conv5_1/expand/bn"
top: "conv5_1/expand/bn"
}
layer {
name: "conv5_1/dwise"
type: "Convolution"
bottom: "conv5_1/expand/bn"
top: "conv5_1/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv5_1/dwise/bn"
type: "BatchNorm"
bottom: "conv5_1/dwise"
top: "conv5_1/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_1/dwise/scale"
type: "Scale"
bottom: "conv5_1/dwise/bn"
top: "conv5_1/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu5_1/dwise"
type: "ReLU"
bottom: "conv5_1/dwise/bn"
top: "conv5_1/dwise/bn"
}
layer {
name: "conv5_1/linear"
type: "Convolution"
bottom: "conv5_1/dwise/bn"
top: "conv5_1/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv5_1/linear/bn"
type: "BatchNorm"
bottom: "conv5_1/linear"
top: "conv5_1/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_1/linear/scale"
type: "Scale"
bottom: "conv5_1/linear/bn"
top: "conv5_1/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_5_1"
type: "Eltwise"
bottom: "conv4_7/linear/bn"
bottom: "conv5_1/linear/bn"
top: "block_5_1"
}
layer {
name: "conv5_2/expand"
type: "Convolution"
bottom: "block_5_1"
top: "conv5_2/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv5_2/expand/bn"
type: "BatchNorm"
bottom: "conv5_2/expand"
top: "conv5_2/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_2/expand/scale"
type: "Scale"
bottom: "conv5_2/expand/bn"
top: "conv5_2/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu5_2/expand"
type: "ReLU"
bottom: "conv5_2/expand/bn"
top: "conv5_2/expand/bn"
}
layer {
name: "conv5_2/dwise"
type: "Convolution"
bottom: "conv5_2/expand/bn"
top: "conv5_2/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv5_2/dwise/bn"
type: "BatchNorm"
bottom: "conv5_2/dwise"
top: "conv5_2/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_2/dwise/scale"
type: "Scale"
bottom: "conv5_2/dwise/bn"
top: "conv5_2/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu5_2/dwise"
type: "ReLU"
bottom: "conv5_2/dwise/bn"
top: "conv5_2/dwise/bn"
}
layer {
name: "conv5_2/linear"
type: "Convolution"
bottom: "conv5_2/dwise/bn"
top: "conv5_2/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv5_2/linear/bn"
type: "BatchNorm"
bottom: "conv5_2/linear"
top: "conv5_2/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_2/linear/scale"
type: "Scale"
bottom: "conv5_2/linear/bn"
top: "conv5_2/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_5_2"
type: "Eltwise"
bottom: "block_5_1"
bottom: "conv5_2/linear/bn"
top: "block_5_2"
}
layer {
name: "conv5_3/expand"
type: "Convolution"
bottom: "block_5_2"
top: "conv5_3/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv5_3/expand/bn"
type: "BatchNorm"
bottom: "conv5_3/expand"
top: "conv5_3/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_3/expand/scale"
type: "Scale"
bottom: "conv5_3/expand/bn"
top: "conv5_3/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu5_3/expand"
type: "ReLU"
bottom: "conv5_3/expand/bn"
top: "conv5_3/expand/bn"
}
layer {
name: "conv5_3/dwise"
type: "Convolution"
bottom: "conv5_3/expand/bn"
top: "conv5_3/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
stride:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv5_3/dwise/bn"
type: "BatchNorm"
bottom: "conv5_3/dwise"
top: "conv5_3/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_3/dwise/scale"
type: "Scale"
bottom: "conv5_3/dwise/bn"
top: "conv5_3/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu5_3/dwise"
type: "ReLU"
bottom: "conv5_3/dwise/bn"
top: "conv5_3/dwise/bn"
}
layer {
name: "conv5_3/linear"
type: "Convolution"
bottom: "conv5_3/dwise/bn"
top: "conv5_3/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv5_3/linear/bn"
type: "BatchNorm"
bottom: "conv5_3/linear"
top: "conv5_3/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv5_3/linear/scale"
type: "Scale"
bottom: "conv5_3/linear/bn"
top: "conv5_3/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv6_1/expand"
type: "Convolution"
bottom: "conv5_3/linear/bn"
top: "conv6_1/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_1/expand/bn"
type: "BatchNorm"
bottom: "conv6_1/expand"
top: "conv6_1/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_1/expand/scale"
type: "Scale"
bottom: "conv6_1/expand/bn"
top: "conv6_1/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu6_1/expand"
type: "ReLU"
bottom: "conv6_1/expand/bn"
top: "conv6_1/expand/bn"
}
layer {
name: "conv6_1/dwise"
type: "Convolution"
bottom: "conv6_1/expand/bn"
top: "conv6_1/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv6_1/dwise/bn"
type: "BatchNorm"
bottom: "conv6_1/dwise"
top: "conv6_1/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_1/dwise/scale"
type: "Scale"
bottom: "conv6_1/dwise/bn"
top: "conv6_1/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu6_1/dwise"
type: "ReLU"
bottom: "conv6_1/dwise/bn"
top: "conv6_1/dwise/bn"
}
layer {
name: "conv6_1/linear"
type: "Convolution"
bottom: "conv6_1/dwise/bn"
top: "conv6_1/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_1/linear/bn"
type: "BatchNorm"
bottom: "conv6_1/linear"
top: "conv6_1/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_1/linear/scale"
type: "Scale"
bottom: "conv6_1/linear/bn"
top: "conv6_1/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_6_1"
type: "Eltwise"
bottom: "conv5_3/linear/bn"
bottom: "conv6_1/linear/bn"
top: "block_6_1"
}
layer {
name: "conv6_2/expand"
type: "Convolution"
bottom: "block_6_1"
top: "conv6_2/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_2/expand/bn"
type: "BatchNorm"
bottom: "conv6_2/expand"
top: "conv6_2/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_2/expand/scale"
type: "Scale"
bottom: "conv6_2/expand/bn"
top: "conv6_2/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu6_2/expand"
type: "ReLU"
bottom: "conv6_2/expand/bn"
top: "conv6_2/expand/bn"
}
layer {
name: "conv6_2/dwise"
type: "Convolution"
bottom: "conv6_2/expand/bn"
top: "conv6_2/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv6_2/dwise/bn"
type: "BatchNorm"
bottom: "conv6_2/dwise"
top: "conv6_2/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_2/dwise/scale"
type: "Scale"
bottom: "conv6_2/dwise/bn"
top: "conv6_2/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu6_2/dwise"
type: "ReLU"
bottom: "conv6_2/dwise/bn"
top: "conv6_2/dwise/bn"
}
layer {
name: "conv6_2/linear"
type: "Convolution"
bottom: "conv6_2/dwise/bn"
top: "conv6_2/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_2/linear/bn"
type: "BatchNorm"
bottom: "conv6_2/linear"
top: "conv6_2/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_2/linear/scale"
type: "Scale"
bottom: "conv6_2/linear/bn"
top: "conv6_2/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "block_6_2"
type: "Eltwise"
bottom: "block_6_1"
bottom: "conv6_2/linear/bn"
top: "block_6_2"
}
layer {
name: "conv6_3/expand"
type: "Convolution"
bottom: "block_6_2"
top: "conv6_3/expand"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_3/expand/bn"
type: "BatchNorm"
bottom: "conv6_3/expand"
top: "conv6_3/expand/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_3/expand/scale"
type: "Scale"
bottom: "conv6_3/expand/bn"
top: "conv6_3/expand/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu6_3/expand"
type: "ReLU"
bottom: "conv6_3/expand/bn"
top: "conv6_3/expand/bn"
}
layer {
name: "conv6_3/dwise"
type: "Convolution"
bottom: "conv6_3/expand/bn"
top: "conv6_3/dwise"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
group:
weight_filler {
type: "msra"
}
engine: CAFFE
}
}
layer {
name: "conv6_3/dwise/bn"
type: "BatchNorm"
bottom: "conv6_3/dwise"
top: "conv6_3/dwise/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_3/dwise/scale"
type: "Scale"
bottom: "conv6_3/dwise/bn"
top: "conv6_3/dwise/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "relu6_3/dwise"
type: "ReLU"
bottom: "conv6_3/dwise/bn"
top: "conv6_3/dwise/bn"
}
layer {
name: "conv6_3/linear"
type: "Convolution"
bottom: "conv6_3/dwise/bn"
top: "conv6_3/linear"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_3/linear/bn"
type: "BatchNorm"
bottom: "conv6_3/linear"
top: "conv6_3/linear/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_3/linear/scale"
type: "Scale"
bottom: "conv6_3/linear/bn"
top: "conv6_3/linear/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.000000001
}
}
layer {
name: "conv6_4"
type: "Convolution"
bottom: "conv6_3/linear/bn"
top: "conv6_4"
param {
lr_mult: 1.0
decay_mult: 1.0
}
convolution_param {
num_output:
bias_term: false
kernel_size:
weight_filler {
type: "msra"
}
}
}
layer {
name: "conv6_4/bn"
type: "BatchNorm"
bottom: "conv6_4"
top: "conv6_4/bn"
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
name: "conv6_4/scale"
type: "Scale"
bottom: "conv6_4/bn"
top: "conv6_4/bn"
param {
lr_mult: 1.0
decay_mult: 0.0
}
param {
lr_mult: 1.0
decay_mult: 0.0
}
scale_param {
filler {
value: 0.5
}
bias_term: true
bias_filler {
value:
}
l1_lambda: 0.001
}
}
layer {
name: "relu6_4"
type: "ReLU"
bottom: "conv6_4/bn"
top: "conv6_4/bn"
}
layer {
name: "pool6"
type: "Pooling"
bottom: "conv6_4/bn"
top: "pool6"
pooling_param {
pool: AVE
global_pooling: true
}
}
layer {
name: "food_fc7"
type: "Convolution"
bottom: "pool6"
top: "fc7"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
#num_output:
num_output:
kernel_size:
weight_filler {
type: "msra"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc7"
bottom: "label"
top: "loss"
}
layer {
name: "top1/acc"
type: "Accuracy"
bottom: "fc7"
bottom: "label"
top: "top1/acc"
include {
phase: TEST
}
}
layer {
name: "top5/acc"
type: "Accuracy"
bottom: "fc7"
bottom: "label"
top: "top5/acc"
include {
phase: TEST
}
accuracy_param {
top_k:
}
}
MobileNet V2深入理解的更多相关文章
- 轻量化模型:MobileNet v2
MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381 MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型. 关于Mobile ...
- mobile-net v2 学习记录。我是菜鸡!
声明:只是自己写博客总结下,不保证正确性,我的理解很可能是错的.. 首先,mobile net V1的主要特点是: 1.深度可分离卷积.用depth-wise convolution来分层过滤特征,再 ...
- YOLO V2论文理解
概述 YOLO(You Only Look Once: Unified, Real-Time Object Detection)从v1版本进化到了v2版本,作者在darknet主页先行一步放出源代码, ...
- MobileNet V2
https://zhuanlan.zhihu.com/p/33075914 http://blog.csdn.net/u011995719/article/details/79135818 https ...
- 卷积神经网络学习笔记——轻量化网络MobileNet系列(V1,V2,V3)
完整代码及其数据,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote 这里结合网络的资料和Mo ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- 深度学习笔记(十一)网络 Inception, Xception, MobileNet, ShuffeNet, ResNeXt, SqueezeNet, EfficientNet, MixConv
1. Abstract 本文旨在简单介绍下各种轻量级网络,纳尼?!好吧,不限于轻量级 2. Introduction 2.1 Inception 在最初的版本 Inception/GoogleNet, ...
- MobileNet系列
最近一段时间,重新研读了谷歌的mobilenet系列,对该系列有新的认识. 1.MobileNet V1 这篇论文是谷歌在2017年提出了,专注于移动端或者嵌入式设备中的轻量级CNN网络.该论文最大的 ...
- 轻量级卷积神经网络——MobileNet
谷歌论文题目: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 其他参考: CNN ...
随机推荐
- 1.Hbase简介
1. Hbase简介 1.1. 什么是hbase(面向列) HBASE是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模 结构化存储集群 ...
- PAT Basic 1088 三人行 (20 分)
子曰:“三人行,必有我师焉.择其善者而从之,其不善者而改之.” 本题给定甲.乙.丙三个人的能力值关系为:甲的能力值确定是 2 位正整数:把甲的能力值的 2 个数字调换位置就是乙的能力值:甲乙两人能力差 ...
- mongodb索引 复合索引
当我们的查询条件不只有一个时,就需要建立复合索引,比如插入一条{x:1,y:2,z:3}记录,按照我们之前建立的x为1的索引,可是使用x查询,现在想按照x与y的值查询,就需要创建如下的索引 创 ...
- AtCoder Beginner Contest 133 F Colorful Tree
Colorful Tree 思路: 如果强制在线的化可以用树链剖分. 但这道题不强制在线,那么就可以将询问进行差分,最后dfs时再计算每个答案的修改值, 只要维护两个数组就可以了,分别表示根节点到当前 ...
- JAVA遇见HTML——JSP篇:JavaBeans
Javabeans简介 Javabeans就是符合某种特定的规范的java类.使用Javabeans的好处是解决代码重复编写,减少代码冗余,功能区分明确,提高了代码的维护性. Javabean的设计原 ...
- linux实操_shell流程控制
if判断: 基本语法: if [ 条件判断式 ] then 程序 elif [ 条件判断式 ] then 程序 fi 实例:请编写一个shell程序,如果输入的参数,大于60,则输出“及格了”,如果小 ...
- win10笔记本连接wifi出现:您的计算机配置似乎是正确的,但该配置或资源(DNS服务器)检测到有响应
问题上图: 一直以来连接网线使用,很少使用WiFi了,在网线不好使的时候使用wifi发现并不怎么好用,甚至上不了网页,但是那时候也不怎么在意,不过一会网线就好使了所以也没处理,直到今天,因为接下来好多 ...
- [Google Guava] 6-字符串处理:分割,连接,填充
原文链接 译文链接 译者:沈义扬,校对:丁一 连接器[Joiner] 用分隔符把字符串序列连接起来也可能会遇上不必要的麻烦.如果字符串序列中含有null,那连接操作会更难.Fluent风格的Joine ...
- P3474 [POI2008]KUP-Plot purchase
思路:单调栈 提交:>5次 错因:单调栈写法有问题+前缀和写错 题解: 若有\(>=k\ \&\&\ <=2\times k\)的点,显然直接选他就行了. 否则,我们 ...
- Flutter布局5---Container
Container 容器 简介一个常用的widget,它结合了常见的绘画,定位和大小调整·该容器首先让child填充绘制,然后再将其他的约束应用于填充范围.·在绘画过程中,容器先应用给定的转换,再绘制 ...