工作流调度系统Azkaban的简介和使用
1 概述
1.1 为什么需要工作流调度系统
l 一个完整的数据分析系统通常都是由大量任务单元组成:
shell脚本程序,java程序,mapreduce程序、hive脚本等
l 各任务单元之间存在时间先后及前后依赖关系
l 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
例如,我们可能有这样一个需求,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
1、 通过Hadoop先将原始数据同步到HDFS上;
2、 借助MapReduce计算框架对原始数据进行转换,生成的数据以分区表的形式存储到多张Hive表中;
3、 需要对Hive中多个表的数据进行JOIN处理,得到一个明细数据Hive大表;
4、 将明细数据进行复杂的统计分析,得到结果报表信息;
5、 需要将统计分析得到的结果数据同步到业务系统中,供业务调用使用。
1.2 工作流调度实现方式
简单的任务调度:直接使用linux的crontab来定义;
复杂的任务调度:开发调度平台
或使用现成的开源调度系统,比如ooize、azkaban等
1.3 常见工作流调度系统
市面上目前有许多工作流调度器
在hadoop领域,常见的工作流调度器有Oozie, Azkaban,Cascading,Hamake等
1.4 各种调度工具特性对比
下面的表格对上述四种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考
|
特性 |
Hamake |
Oozie |
Azkaban |
Cascading |
|
工作流描述语言 |
XML |
XML (xPDL based) |
text file with key/value pairs |
Java API |
|
依赖机制 |
data-driven |
explicit |
explicit |
explicit |
|
是否要web容器 |
No |
Yes |
Yes |
No |
|
进度跟踪 |
console/log messages |
web page |
web page |
Java API |
|
Hadoop job调度支持 |
no |
yes |
yes |
yes |
|
运行模式 |
command line utility |
daemon |
daemon |
API |
|
Pig支持 |
yes |
yes |
yes |
yes |
|
事件通知 |
no |
no |
no |
yes |
|
需要安装 |
no |
yes |
yes |
no |
|
支持的hadoop版本 |
0.18+ |
0.20+ |
currently unknown |
0.18+ |
|
重试支持 |
no |
workflownode evel |
yes |
yes |
|
运行任意命令 |
yes |
yes |
yes |
yes |
|
Amazon EMR支持 |
yes |
no |
currently unknown |
yes |
1.5 Azkaban与Oozie对比
对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。
详情如下:
u 功能
两者均可以调度mapreduce,pig,java,脚本工作流任务
两者均可以定时执行工作流任务
u 工作流定义
Azkaban使用Properties文件定义工作流
Oozie使用XML文件定义工作流
u 工作流传参
Azkaban支持直接传参,例如${input}
Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)}
u 定时执行
Azkaban的定时执行任务是基于时间的
Oozie的定时执行任务基于时间和输入数据
u 资源管理
Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作
Oozie暂无严格的权限控制
u 工作流执行
Azkaban有两种运行模式,分别是soloserver mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点)
Oozie作为工作流服务器运行,支持多用户和多工作流
u 工作流管理
Azkaban支持浏览器以及ajax方式操作工作流
Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
2 Azkaban介绍
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
它有如下功能特点:
² Web用户界面
² 方便上传工作流
² 方便设置任务之间的关系
² 调度工作流
² 认证/授权(权限的工作)
² 能够杀死并重新启动工作流
² 模块化和可插拔的插件机制
² 项目工作区
² 工作流和任务的日志记录和审计
2.1 Azkaban安装部署
2.1.1 准备工作
Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
MySQL
目前azkaban只支持 mysql,需安装mysql服务器,本文档中默认已安装好mysql服务器,并建立了 root用户,密码 root.
下载地址:http://azkaban.github.io/downloads.html
2.1.2 安装
将安装文件上传到集群,最好上传到安装 hive、sqoop的机器上,方便命令的执行
在当前用户目录下新建 azkabantools目录,用于存放源安装文件.新建azkaban目录,用于存放azkaban运行程序
2.1.3 azkaban web服务器安装
解压azkaban-web-server-2.5.0.tar.gz
命令: tar –zxvf azkaban-web-server-2.5.0.tar.gz
将解压后的azkaban-web-server-2.5.0 移动到 azkaban目录中,并重新命名 webserver
命令: mv azkaban-web-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-web-server-2.5.0 server
2.1.4 azkaban 执行服器安装
解压azkaban-executor-server-2.5.0.tar.gz
命令:tar –zxvf azkaban-executor-server-2.5.0.tar.gz
将解压后的azkaban-executor-server-2.5.0 移动到 azkaban目录中,并重新命名 executor
命令:mv azkaban-executor-server-2.5.0 ../azkaban
cd ../azkaban
mv azkaban-executor-server-2.5.0 executor
azkaban脚本导入
解压: azkaban-sql-script-2.5.0.tar.gz
命令:tar –zxvf azkaban-sql-script-2.5.0.tar.gz
将解压后的mysql 脚本,导入到mysql中:
进入mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source/home/hadoop/azkaban-2.5.0/create-all-sql-2.5.0.sql;
2.1.5 创建SSL配置
参考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,输入的密码请劳记,信息如下:
输入keystore密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown,L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入<jetty>的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中.如:cp keystore azkaban/server
2.1.6 配置文件
注:先配置好服务器节点上的时区
1、先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可
2、拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
azkaban web服务器配置
进入azkaban web服务器安装目录 conf目录
v 修改azkaban.properties文件
命令vi azkaban.properties
内容说明如下:
|
#Azkaban Personalization Settings azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字 azkaban.label=My Local Azkaban #描述 azkaban.color=#FF3601 #UI颜色 azkaban.default.servlet.path=/index # web.resource.dir=web/ #默认根web目录 default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国 #Azkaban UserManager class user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类 user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文 #Loader for projects executor.global.properties=conf/global.properties # global配置文件所在位置 azkaban.project.dir=projects # database.type=mysql #数据库类型 mysql.port=3306 #端口号 mysql.host=localhost #数据库连接IP mysql.database=azkaban #数据库实例名 mysql.user=root #数据库用户名 mysql.password=root #数据库密码 mysql.numconnections=100 #最大连接数 # Velocity dev mode velocity.dev.mode=false # Jetty服务器属性. jetty.maxThreads=25 #最大线程数 jetty.ssl.port=8443 #Jetty SSL端口 jetty.port=8081 #Jetty端口 jetty.keystore=keystore #SSL文件名 jetty.password=123456 #SSL文件密码 jetty.keypassword=123456 #Jetty主密码 与 keystore文件相同 jetty.truststore=keystore #SSL文件名 jetty.trustpassword=123456 # SSL文件密码 # 执行服务器属性 executor.port=12321 #执行服务器端口 # 邮件设置 mail.sender=xxxxxxxx@163.com #发送邮箱 mail.host=smtp.163.com #发送邮箱smtp地址 mail.user=xxxxxxxx #发送邮件时显示的名称 mail.password=********** #邮箱密码 job.failure.email=xxxxxxxx@163.com #任务失败时发送邮件的地址 job.success.email=xxxxxxxx@163.com #任务成功时发送邮件的地址 lockdown.create.projects=false # cache.directory=cache #缓存目录 |
v azkaban 执行服务器executor配置
进入执行服务器安装目录conf,修改azkaban.properties
vi azkaban.properties
|
#Azkaban default.timezone.id=Asia/Shanghai #时区 # Azkaban JobTypes 插件配置 azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置 #Loader for projects executor.global.properties=conf/global.properties azkaban.project.dir=projects #数据库设置 database.type=mysql #数据库类型(目前只支持mysql) mysql.port=3306 #数据库端口号 mysql.host=192.168.20.200 #数据库IP地址 mysql.database=azkaban #数据库实例名 mysql.user=root #数据库用户名 mysql.password=root #数据库密码 mysql.numconnections=100 #最大连接数 # 执行服务器配置 executor.maxThreads=50 #最大线程数 executor.port=12321 #端口号(如修改,请与web服务中一致) executor.flow.threads=30 #线程数 |
v 用户配置
进入azkaban web服务器conf目录,修改azkaban-users.xml
vi azkaban-users.xml 增加 管理员用户
|
<azkaban-users> <user username="azkaban" password="azkaban" roles="admin" groups="azkaban" /> <user username="metrics" password="metrics" roles="metrics"/> <user username="admin" password="admin" roles="admin,metrics" /> <role name="admin" permissions="ADMIN" /> <role name="metrics" permissions="METRICS"/> </azkaban-users> |
2.1.7 启动
web服务器
在azkaban web服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在web服务器根目录运行
或者启动到后台
nohup bin/azkaban-web-start.sh 1>/tmp/azstd.out 2>/tmp/azerr.out &
执行服务器
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443 ,即可访问azkaban服务了.在登录中输入刚才新的户用名及密码,点击 login.
3 Azkaban实战
Azkaba内置的任务类型支持command、java
3.1 Command类型单一job示例
1、创建job描述文件
vi command.job
|
#command.job type=command command=echo 'hello' |
2、将job资源文件打包成zip文件
zip command.job
3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
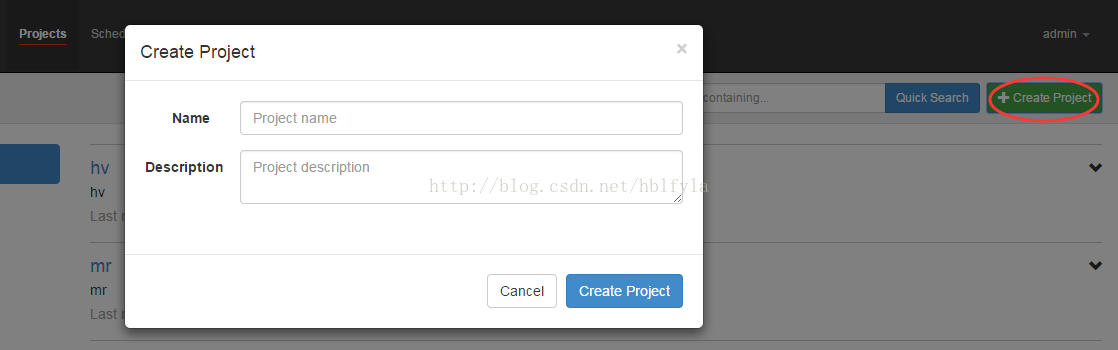
上传zip包

4、启动执行该job

3.2 Command类型多job工作流flow
1、创建有依赖关系的多个job描述
第一个job:foo.job
|
# foo.job type=command command=echo foo |
第二个job:bar.job依赖foo.job
|
# bar.job type=command dependencies=foo command=echo bar |
2、将所有job资源文件打到一个zip包中
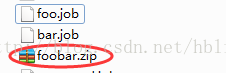
3、在azkaban的web管理界面创建工程并上传zip包
4、启动工作流flow
3.3 HDFS操作任务
1、创建job描述文件
|
# fs.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz |
2、将job资源文件打包成zip文件
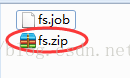
3、通过azkaban的web管理平台创建project并上传job压缩包
4、启动执行该job
3.4 MAPREDUCE任务
Mr任务依然可以使用command的job类型来执行
1、创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的examplejar)
|
# mrwc.job type=command command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout |
2、将所有job资源文件打到一个zip包中

3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
3.5 HIVE脚本任务
l 创建job描述文件和hive脚本
Hive脚本: test.sql
|
use default; drop table aztest; create table aztest(id int,name string) row format delimited fields terminated by ','; load data inpath '/aztest/hiveinput' into table aztest; create table azres as select * from aztest; insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest; |
Job描述文件:hivef.job
|
# hivef.job type=command command=/home/hadoop/apps/hive/bin/hive -f 'test.sql' |
2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
工作流调度系统Azkaban的简介和使用的更多相关文章
- 工作流调度器azkaban(以及各种工作流调度器比对)
1:工作流调度系统的作用: (1):一个完整的数据分析系统通常都是由大量任务单元组成:比如,shell脚本程序,java程序,mapreduce程序.hive脚本等:(2):各任务单元之间存在时间先后 ...
- 工作流调度器azkaban
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 各任务单元之间存在时间先后及前后依赖关系 为了很 ...
- 工作流调度器之Azkaban
Azkaban 1. 工作流调度器概述 1.1. 为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成:shell脚本程序,java程序,mapreduce程序.hive脚本等 ...
- hadoop工作流调度系统
常见工作流调度系统 Oozie, Azkaban, Cascading, Hamake 各种调度工具特性对比 特性 Hamake Oozie Azkaban Cascading 工作流描述语言 XML ...
- 【Hadoop离线基础总结】工作流调度器azkaban
目录 Azkaban概述 工作流调度系统的作用 工作流调度系统的实现 常见工作流调度工具对比 Azkaban简单介绍 安装部署 Azkaban的编译 azkaban单服务模式安装与使用 azkaban ...
- 大数据学习——azkaban工作流调度系统
azkaban的安装部署 在/root/apps 1目录下新建azkaban文件夹 上传安装包到azkaban 2解压 .tar.gz 3删掉安装包 [root@mini1 azkaban]# .ta ...
- azkaban工作流调度器及相关工具对比
本文转载自:工作流调度器azkaban,主要用于架构选型,安装请参考:Azkaban安装与简介,azkaban的简单使用 为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: ...
- Azkaban工作流调度器
Azkaban工作流调度器 在Hadoop领域常用的工作流调度系统 Oozie,Azkaban,Cascading,Hamake等等. 性能对比: 安装: 创建ssl配置 keytool -keyst ...
- Azkaban 工作流调度器
Azkaban 工作流调度器 1 概述 1.1 为什么需要工作流调度系统 a)一个完整的数据分析系统通常都是由大量任务单元组成,shell脚本程序,java程序,mapreduce程序.hive脚本等 ...
随机推荐
- 谷歌浏览器调试手机app内置网页
当自己的H5项目内置于手机app内时,遇到了样式问题或者想查看H5页面代码.数据交互以及缓存等情况来检查数据,此时可以使用谷歌浏览器的控制台远程调试手机,步骤如下: 一.手机开启允许usb调试 二.手 ...
- stm32F1 DMA
DMA,全称是Direct Memory Access,中文意思为直接存储器访问 DMA可用于实现外设与存储器之间或者存储器与存储器之间数据传输的高效性 DMA请求映像 各通道的DMA1请求: 各通道 ...
- Join 和 App
在关系型数据库系统中,为了满足第三范式(3NF),需要将满足“传递依赖”的表分离成单独的表,通过Join 子句将相关表进行连接,Join子句共有三种类型:外连接,内连接,交叉连接:外连接分为:left ...
- Centos超详细安装步骤
Linux中三大主流操作系统 Ubuntu 优点:用户界面友好.工具完善 缺点:vps(虚拟服务器)成本较高.不具备商业化服务器操作系统 Centos--目前常用centos6.x,centos7.x ...
- Linux命令——gzip、zcat、bzip2、bzcat、tar
参考:Linux命令——ar 为什么文件要压缩? 当文件过大时,无论是本地做备份,复制都很麻烦,而且还浪费磁盘空间.如果用网络传输,大文件无疑会浪费大量宝贵带宽.文件压缩技术可以有效解决这个问题,但是 ...
- PropTypes没有定义的问题
今天做项目遇到了一个坑 import React, { Component,PropTypes} from 'react'; console.log(PropTypes); //undefined 用 ...
- Oracle 安装步骤
目录 Oracle 安装步骤 一.安装流程 二.登录流程 三.新建数据库 四.图形化连接 Oracle 安装步骤 一.安装流程 解压oracle 11g两个压缩文件 点击安装,修改目录,新建一个文件夹 ...
- 标准库类型之vector
上篇中遗留了一个小作业,就是用string中的find_first_not_of和find_last_not_of函数来实现字符串左右空格的去除,先来完成它,实现的思路是先来编写去除左空格,然后再编写 ...
- jmeter分布式运行
一.设置windows远程启动 1).Jmeter分布式测试时,选择其中一台作为控制机(Controller),其它机器做为代理机(Agent). 2).执行时,Controller会把脚本发送到每台 ...
- 大数据之路week05--day01(JDBC 初识之实现一个系统 实现用户选择增删改查 未优化版本)
要求,实现用户选择增删改查. 给出mysql文件,朋友们可以自己运行导入到自己的数据库中: /* Navicat MySQL Data Transfer Source Server : mysql S ...