深度学习框架PyTorch一书的学习-第七章-生成对抗网络(GAN)
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter7-GAN生成动漫头像
GAN解决了非监督学习中的著名问题:给定一批样本,训练一个系统能够生成类似的新样本
生成对抗网络的网络结构如下图所示:
- 生成器(generator):输入一个随机噪声,生成一张图片
- 判别器(discriminator):判断输入的图片是真图片还是假图片
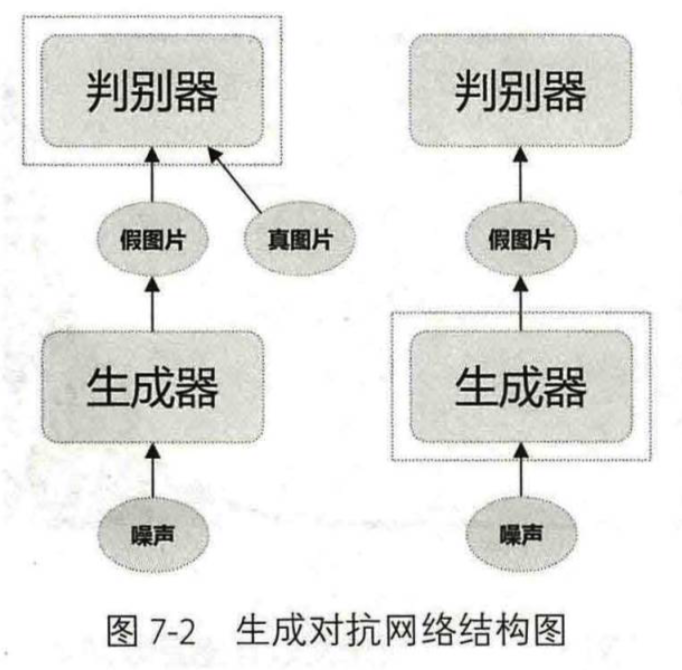
训练判别器D时,需要利用生成器G生成的假图片和来自现实世界的真图片;训练生成器时,只需要使用噪声生成假图片
判别器用来评估生成的假图片的质量,促使生成器相应地调整参数
生成器的目标是尽可能地生成以假乱真的图片,让判别器以为这是真的图片;判别器的目标是将生成器生成的图片和真实世界的图片区分开
可以看出这两者的目标相反,在训练过程中相互对抗,这也是它被称为生成对抗网络的原因
一开始,生成器和判别器的水平都很差,因为两者都是随机初始化的。训练的步骤分两步交替进行:
- 第一步是训练判别器D(只修改判别器的参数,固定生成器),目标是把真图片和假图片区分开
- 第二步是训练生成器(只修改生成器的参数,固定判别器),为的是生成的假图片能够被判别器判别为真图片
这两步交替进行,为的是生成的假图片能够被判别为真图片
1.网络结构的设计
判别器的目标是判断输入的图片是真图片还是假图片,所以可以被看作是二分类网络
生成器的目标是从噪声中生成一张彩色图片
这里我们采用的是广泛使用的DCGAN(Deep Convolutional Generative Adversarial Networks)结构,即采用全卷积网络,如图所示:

网络的输入是一个100维的噪声,输出是一个3*64*64的图片
这里的输入可以看成是一个100*1*1的图片,通过上卷积慢慢增大为4*4、8*8、16*16、32*32和64*64。当上卷集的stride=2时,输出会上采样到输入的两倍
这种上采样的做法可以理解为图片的信息保存于100个向量之中,然后神经网络会根据这100个向量描述的信息,前几步的上采样先勾勒出轮廓、色调等基础信息,后几步上采样慢慢完善细节。网络越深,细节越详细
在DCGAN中,判别器的结构和生成器对称:生成器中采用上采样的卷积,判别器中就采用下采样的卷积。
生成器是根据噪声输出一张64*64*3的图片,而判别器则是根据输出的64*64*3的图片输出图片属于正负样本的分数(即概率)
2.用GAN生成动漫头像
从https://pan.baidu.com/s/1eSifHcA 提取码:g5qa下载数据(275M,约5万多张图片)
把所有图片保存于data/face/目录下,形如:
data/
└── faces/
├── 0000fdee4208b8b7e12074c920bc6166-.jpg
├── 0001a0fca4e9d2193afea712421693be-.jpg
├── 0001d9ed32d932d298e1ff9cc5b7a2ab-.jpg
├── 0001d9ed32d932d298e1ff9cc5b7a2ab-.jpg
├── 00028d3882ec183e0f55ff29827527d3-.jpg
├── 00028d3882ec183e0f55ff29827527d3-.jpg
├── 000333906d04217408bb0d501f298448-.jpg
├── 0005027ac1dcc32835a37be806f226cb-.jpg
即data目录下只有一个文件夹,文件夹中有所有的图片
注意这里图片的分辨率是3*96*96,而不是3*64*64,所以需要相应地调整网络结构,使生成图像的尺寸为96
1)实验的代码结构
checkpoints/ #无代码,用来保存训练好的模型
imgs/ #无代码,用来保存生成的图片
data/ #无代码,用来保存训练所需的图片
main.py #训练和生成代码
model.py #模型定义代码
visualize.py #可视化工具visdom的封装代码
requirements.txt #程序中用到的第三方库
README.MD #说明文档
1》model.py
定义生成器和判别器
判别器:
class NetD(nn.Module):
"""
判别器定义
""" def __init__(self, opt):
super(NetD, self).__init__()
ndf = opt.ndf #判别器channel值
self.main = nn.Sequential(
# 输入 x x
# kernel_size = ,stride = , padding =
# 按式子计算 floor(( + * - *(-) - )/ + ) =
# 是same卷积,/ = stride =
nn.Conv2d(, ndf, , , , bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf) x x #kernel_size = ,stride = , padding =
#按式子计算 floor(( + * - *(-) - )/ + ) =
#是same卷积,/ = stride =
nn.Conv2d(ndf, ndf * , , , , bias=False),
nn.BatchNorm2d(ndf * ),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*) x x #kernel_size = ,stride = , padding =
#按式子计算 floor(( + * - *(-) - )/ + ) =
#是same卷积,/ = stride =
nn.Conv2d(ndf * , ndf * , , , , bias=False),
nn.BatchNorm2d(ndf * ),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*) x x #kernel_size = ,stride = , padding =
#按式子计算 floor(( + * - *(-) - )/ + ) =
#是same卷积,/ = stride =
nn.Conv2d(ndf * , ndf * , , , , bias=False),
nn.BatchNorm2d(ndf * ),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*) x x #kernel_size = ,stride = , padding =
#按式子计算 floor(( + * - *(-) - )/ + ) =
nn.Conv2d(ndf * , , , , , bias=False),
#输出为1**
nn.Sigmoid() # 返回[,]的值,输出一个数(作为概率值)
) def forward(self, input):
return self.main(input).view(-) #输出从1**1变为1,得到生成器生成假图片的分数,分数高则像真图片
生成器:
class NetG(nn.Module):
"""
生成器定义
""" def __init__(self, opt):
super(NetG, self).__init__()
ngf = opt.ngf # 生成器feature map数channnel,默认为64 self.main = nn.Sequential(
# 输入是一个nz维度(默认为100)的噪声,我们可以认为它是一个1**nz的feature map
# kernel_size = ,stride = , padding =
# 根据计算式子 (-)* - * + + =
nn.ConvTranspose2d(opt.nz, ngf * , , , , bias=False),
nn.BatchNorm2d(ngf * ),
nn.ReLU(True),
# 上一步的输出形状:(ngf*) x x #kernel_size = ,stride = , padding =
#根据计算式子 (-)* - * + + =
nn.ConvTranspose2d(ngf * , ngf * , , , , bias=False),
nn.BatchNorm2d(ngf * ),
nn.ReLU(True),
# 上一步的输出形状: (ngf*) x x #kernel_size = ,stride = , padding =
#根据计算式子 (-)* - * + + =
nn.ConvTranspose2d(ngf * , ngf * , , , , bias=False),
nn.BatchNorm2d(ngf * ),
nn.ReLU(True),
# 上一步的输出形状: (ngf*) x x #kernel_size = ,stride = , padding =
#根据计算式子 (-)* - * + + =
nn.ConvTranspose2d(ngf * , ngf, , , , bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上一步的输出形状:(ngf) x x # kernel_size = ,stride = , padding =
#根据计算式子 (-)* - * + + =
nn.ConvTranspose2d(ngf, , , , , bias=False),
nn.Tanh() # 输出范围 -~ 故而采用Tanh
# 输出形状: x x
) def forward(self, input):
return self.main(input)
可以看出判别器和生成器的网络结构几乎是对称的,从卷积核大小kernel_size到padding、stride等设置,几乎是一模一样。例如生成器的最后一个卷积层的尺度是(5,3,1),判别器的第一个卷积层的尺度也是(5,3,1)
再这里可见生成器的激活函数使用的是ReLU(),而判别器使用的是LeakyReLU,二者并没有本质的区别,这里的选择不同更多是经验总结导致的
每一个样本经过判别器后,输出一个0~1的数,表示这个样本是真图片的概率
2》main.py
配置参数信息:
class Config(object):
data_path = 'data/' # 数据集存放路径
num_workers = # 多进程加载数据所用的进程数
image_size = # 图片尺寸
batch_size =
max_epoch =
lr1 = 2e- # 生成器的学习率
lr2 = 2e- # 判别器的学习率
beta1 = 0.5 # Adam优化器的beta1参数
gpu = True # 是否使用GPU
nz = # 噪声维度
ngf = # 生成器feature map数
ndf = # 判别器feature map数 save_path = 'imgs/' # 生成图片保存路径 vis = True # 是否使用visdom可视化
env = 'GAN' # visdom的env
plot_every = # 每间隔20 batch,visdom画图一次 debug_file = '/tmp/debuggan' # 存在该文件则进入debug模式
d_every = # 每1个batch训练一次判别器
g_every = # 每5个batch训练一次生成器
save_every = # 没10个epoch保存一次模型
netd_path = None # 'checkpoints/netd_.pth' #预训练模型
netg_path = None # 'checkpoints/netg_211.pth' # 只测试不训练
gen_img = 'result.png'
# 从512张生成的图片中保存最好的64张
gen_num =
gen_search_num =
gen_mean = # 噪声的均值
gen_std = # 噪声的方差 opt = Config()
这些是模型的默认参数,还可以利用Fire等工具通过命令行传入,覆盖默认值。可以用opt.attr的方式来指定使用的参数
这里的参数设置大多是照搬DCGAN论文的默认值,作者经过大量的实验,发现这些参数能够更快地训练出一个不错的模型
数据处理:
使用torchvision.ImageFolder函数读取data/faces中的图片,不必自己写Dataset
数据读取和加载的代码为:
# 数据
transforms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size), #重新设置图片大小,opt.image_size默认值为96
tv.transforms.CenterCrop(opt.image_size), #从中心截取大小为opt.image_size的图片
tv.transforms.ToTensor(), #转为Tensor格式,并将值取在[,]中
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) #标准化,得到在[-,]的值
]) dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms) #从data中读取图片,图片类别会设置为文件夹名faces
dataloader = t.utils.data.DataLoader(dataset, #然后对得到的图片进行批处理,默认一批为256张图,使用4个进程读取数据
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.num_workers,
drop_last=True
)
定义变量:模型,优化器,噪声
# 网络,netg为生成器,netd为判别器
netg, netd = NetG(opt), NetD(opt)
# 把所有的张量加载到CPU中
map_location = lambda storage, loc: storage
# 把所有的张量加载到GPU 1中
#torch.load('tensors.pt', map_location=lambda storage, loc: storage.cuda())
#也可以写成:
#device = torch.device('cpu')
#netd.load_state_dict(t.load(opt.netd_path, map_location=device))
#或:
#netd.load_state_dict(t.load(opt.netd_path))
#netd.to(device)
if opt.netd_path: #是否指定训练好的预训练模型,加载模型参数
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device) # 定义优化器和损失,学习率都默认为2e-,beta1默认为0.
optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999))
optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999))
criterion = t.nn.BCELoss().to(device) # 真图片label为1,假图片label为0
# noises为生成网络的输入
true_labels = t.ones(opt.batch_size).to(device)
fake_labels = t.zeros(opt.batch_size).to(device)
fix_noises = t.randn(opt.batch_size, opt.nz, , ).to(device)#opt.nz为噪声维度,默认为100
noises = t.randn(opt.batch_size, opt.nz, , ).to(device) #AverageValueMeter测量并返回添加到其中的任何数字集合的平均值和标准差,
#对度量一组示例的平均损失是有用的。
errord_meter = AverageValueMeter()
errorg_meter = AverageValueMeter()
再加载预训练模型时,最好指定map_location。因为如果程序之前在GPU上运行,那么模型就会被存为torch.cuda.Tensor,这样加载时会默认将数据加载至显存。如果运行该程序的计算机中没有GPU,加载就会报错,故通过指定map_location将Tensor默认加载入内存(CPU),待有需要再移至显存
训练网络:
1)训练判别器
- 先固定生成器
- 对于真图片,判别器的输出概率值尽可能接近1
- 对于生成器生成的假图片,判别器尽可能输出0
2)训练生成器
- 固定判别器
- 生成器生成图片,尽可能使生成的图片让判别器输出为1
3)返回第一步,循环交替进行
epochs = range(opt.max_epoch)
for epoch in iter(epochs):
for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)):
real_img = img.to(device) if ii % opt.d_every == :
# 训练判别器
# 每d_every=(默认)个batch训练一次判别器
optimizer_d.zero_grad()
## 尽可能的把真图片判别为正确
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward() ## 尽可能把假图片判别为错误
#更新noises中的data值
noises.data.copy_(t.randn(opt.batch_size, opt.nz, , ))
fake_img = netg(noises).detach() # 根据噪声生成假图
output = netd(fake_img)
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
optimizer_d.step() error_d = error_d_fake + error_d_real errord_meter.add(error_d.item()) if ii % opt.g_every == :
# 训练生成器
# 每g_every=5个batch训练一次生成器
optimizer_g.zero_grad()
#更新noises中的data值
noises.data.copy_(t.randn(opt.batch_size, opt.nz, , ))
fake_img = netg(noises)
output = netd(fake_img)
error_g = criterion(output, true_labels)
error_g.backward()
optimizer_g.step()
errorg_meter.add(error_g.item())
注意:
训练生成器时,无须调整判别器的参数;训练判别器时,无须调整生成器的参数
在训练判别器时,需要对生成器生成的图片用detach()操作进行计算图截断,避免反向传播将梯度传到生成器中。因为在训练判别器时,我们不需要训练生成器,也就不需要生成器的梯度
在训练判别器时,需要反向传播两次,一次是希望把真图片判定为1,一次是希望把假图片判定为0.也可以将这两者的数据放到一个batch中,进行一次前向传播和反向传播即可。但是人们发现,分两次的方法更好
对于假图片,在训练判别器时,我们希望判别器输出为0;而在训练生成器时,我们希望判别器输出为1,这样实现判别器和生成器互相对抗提升
可视化:
接下来就是一些可视化代码的实现。每次可视化时使用的噪音都是固定的fix_noises,因为这样便于我们比较对于相同的输入,可见生成器生成的图片是如何一步步提升的
因为对输出的图片进行了归一化处理,值在(-1,1),所以在输出时需要将其还原会原来的scale,值在(0,1),方法就是图片的值*mean + std
# 每间隔20 batch,visdom画图一次
if opt.vis and ii % opt.plot_every == opt.plot_every - :
## 可视化
## 存在该文件则进入debug模式
if os.path.exists(opt.debug_file):
ipdb.set_trace()
fix_fake_imgs = netg(fix_noises)
vis.images(fix_fake_imgs.detach().cpu().numpy()[:] * 0.5 + 0.5, win='fixfake')
vis.images(real_img.data.cpu().numpy()[:] * 0.5 + 0.5, win='real')
vis.plot('errord', errord_meter.value()[])
vis.plot('errorg', errorg_meter.value()[])
保存模型:
# 每10个epoch保存一次模型
if (epoch+) % opt.save_every == :
# 保存模型、图片
tv.utils.save_image(fix_fake_imgs.data[:], '%s/%s.png' % (opt.save_path, epoch), normalize=True,
range=(-, ))
t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch)
t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch)
errord_meter.reset()#重置,清空里面的值
errorg_meter.reset()
验证:
使用训练好的模型进行验证
@t.no_grad()
def generate(**kwargs):#进行验证
"""
随机生成动漫头像,并根据netd的分数选择较好的
"""
for k_, v_ in kwargs.items():
setattr(opt, k_, v_) device=t.device('cuda') if opt.gpu else t.device('cpu') netg, netd = NetG(opt).eval(), NetD(opt).eval()
noises = t.randn(opt.gen_search_num, opt.nz, , ).normal_(opt.gen_mean, opt.gen_std)
noises = noises.to(device) map_location = lambda storage, loc: storage
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device) # 生成图片,并计算图片在判别器的分数
fake_img = netg(noises)
scores = netd(fake_img).detach() # 挑选最好的某几张,默认opt.gen_num=64张,并得到其索引
indexs = scores.topk(opt.gen_num)[]
result = []
for ii in indexs:
result.append(fake_img.data[ii])
# 保存图片
tv.utils.save_image(t.stack(result), opt.gen_img, normalize=True, range=(-, ))
2)开始训练
使用gpu,并且visdom实现可视化
python main.py train --gpu=True --vis=True
进行了200次迭代,生成的图片存储在imgs文件夹中,第一次10轮迭代后生成的结果为:

20次迭代后的结果为:

一直到200次迭代的结果为,多训练几轮可能效果会更好:

在该基础上又训练了200轮:
python main.py train --netd-path=checkpoints/netd_199.pth --netg-path=checkpoints/netg_199.pth
得到的结果是:

3)验证
使用最后一次迭代的到的训练网络进行验证,生成器网络为--netd-path=checkpoints/netd_199.pth,判别器网络为--netg-path=checkpoints/netg_199.pth,会输出结果最好的64张图,并存储在本地,命名为result.png:
(deeplearning) userdeMBP:DCGAN user$ python main.py generate --gpu=False --vis=False --netd-path=checkpoints/netd_199.pth --netg-path=checkpoints/netg_199.pth
得到的result.png为:

深度学习框架PyTorch一书的学习-第七章-生成对抗网络(GAN)的更多相关文章
- 深度学习框架PyTorch一书的学习-第五章-常用工具模块
https://github.com/chenyuntc/pytorch-book/blob/v1.0/chapter5-常用工具/chapter5.ipynb 希望大家直接到上面的网址去查看代码,下 ...
- 深度学习框架PyTorch一书的学习-第六章-实战指南
参考:https://github.com/chenyuntc/pytorch-book/tree/v1.0/chapter6-实战指南 希望大家直接到上面的网址去查看代码,下面是本人的笔记 将上面地 ...
- 深度学习框架PyTorch一书的学习-第四章-神经网络工具箱nn
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 本章介绍的nn模块是构建与autogr ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-2-autograd
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 torch.autograd就是为了方 ...
- 深度学习框架PyTorch一书的学习-第一/二章
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 pytorch的设计遵循tensor- ...
- 深度学习框架PyTorch一书的学习-第三章-Tensor和autograd-1-Tensor
参考https://github.com/chenyuntc/pytorch-book/tree/v1.0 希望大家直接到上面的网址去查看代码,下面是本人的笔记 Tensor Tensor可以是一个数 ...
- 人工智能中小样本问题相关的系列模型演变及学习笔记(二):生成对抗网络 GAN
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手] [再啰嗦一下]本文衔接上一个随笔:人工智能中小样本问题相关的系列模型演变及学习 ...
- 深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成: 生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器 判别器D(Discriminator):判断这张图像是真实的 ...
- 《深度学习框架PyTorch:入门与实践》的Loss函数构建代码运行问题
在学习陈云的教程<深度学习框架PyTorch:入门与实践>的损失函数构建时代码如下: 可我运行如下代码: output = net(input) target = Variable(t.a ...
随机推荐
- 用BCB 画 Code128 B模式条码
//--------------------------------------------------------------------------- #include <vcl.h> ...
- 轻院校赛-zzuli 2266: number【用每位的二进制的幂的和来进行hash(映射)处理】
zzuli 2266: number 大致题意: 给定n,问有多少数对<x, y>满足: x, y∈[1, n], x < y x, y中出现的[0, 9] ...
- MaxPlus WStr Python 中的字符串传递给 MaxPlus
MaxPlus WStr Python 中的字符串传递给 MaxPlus 在 MaxPlus 中,很多方法的参数使用的字符串的类是 WStr,所以在 Python 中,我们传递字符串的时候,就要把 P ...
- UML再论关系extend和include
我在画用例图时,图中既有extend关系也有include关系,师父就问我这两种关系的区别,我在画的时候确实查阅了很多资料,可是在问的时候还是回答不上来,这就是这篇博客得来的缘由了. [include ...
- 04-Dockerfile介绍与使用
什么是dockerfileDockerfile是由一系列命令和参数构成的脚本,这些命令用一基础镜像并最终创建一个新的镜像.1.对于开发人员:可以为开发团队提供一个完全一致的开发环境.2.对于测试人员: ...
- 创建型模式(一) 单例模式(Singleton)
一.动机(Motivation) 在软件系统中,经常有这样一些特殊的类,必须保证它们在系统中只存在一个实例,才能确保它们的逻辑正确性.以及良好的效率. 如何绕过常规的构造器,提供一种机制来保证一个类只 ...
- Django REST framework+Vue 打造生鲜电商项目(笔记六)
(部分代码来自https://www.cnblogs.com/derek1184405959/p/8836205.html) 九.个人中心功能开发 1.drf的api文档自动生成 (1) url #d ...
- 用于异步事件驱动的 P 语言 P Language
微软最近开源了P语言,致力于在Linux.macOS和Windows上编写安全的异步事件驱动程序. 微软将P描述为一种领域特定语言,对异步系统的组件间通信进行建模,例如嵌入式.网络或分布式系统.P程序 ...
- Mac+Appium+Python+Pycharm环境搭建
为什么优先选择Mac做自动化测试? 1.既可以做iOS端的测试也可以进行Android端测试 2.Mac运行效率相对于Win要高很多,可以真正发挥appium的功能 以下是在Mac上完整搭建过程 一. ...
- 发布一个在Web下输入密码时提示大写锁定键的Jquery插件
功能介绍:在Web下输入密码时提示大写锁定键,封装成jq插件方便有需要的同学!使用:$("#txtPWD").capsLockTip();截图预览:代码(2012-05-03 10 ...