R_数据操作_初级_03
数据的输入:详见(http://cran.r-project.org/doc/manuals/R-data.pdf下载的R Data Import/Export手册②)
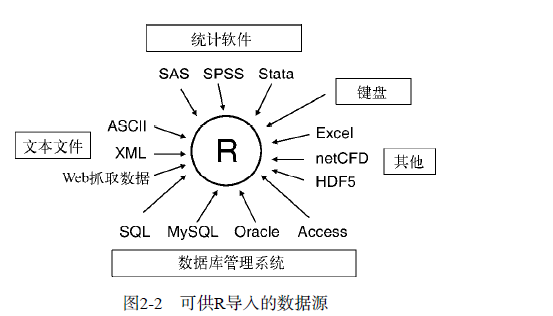
1、键盘输入:使用edit(),会调用文本编辑器,从而创造一个数据框(矩阵)
2、从带分隔符的文本文件中导入数据:mydataframe<-read.table(filename, options)
相关选项有:header 一个表示文件是否在第一行包含了变量名的逻辑型变量
sep 分开数据值的分隔符。默认是sep="",这表示了一个或多个空格、制表符、换行或回车。使用sep=","来读取用逗号来分隔行内数据的文件,使用sep="\t"来读取使用制表符来分割行内数据的文件
row.names 一个用于指定一个或多个行标记符的可选参数
col.names 如果数据文件的第一行不包括变量名(header=FASLE),你可以用col.names 去指定一个包含变量名的字符向量。如果header=FALSE 以及col.names 选项被省略了
变量会被分别命名为V1、V2,以此类推
na.strings 可选的用于表示缺失值的字符向量。比如说,na.strings=c("-9", "?")把-9 和?值在读取数据的时候转换成NA
colClasses 可选的分配到每一列的类向量。比如说,colClasses=c("numeric", "numeric", "character","NULL", "numeric")把前两列读取为数值型变量,把第三列读取为字符型
量,跳过第四列,把第五列读取为数值型向量。如果数据有多余五列,colClasses 的值会被循环。当你在读取大型文本文件的时候,加上colClasses 选项可以可观地提升处理的速度
quote 用于对有特殊字符的字符串划定界限的自负床。默认值是双引号(")或单引号(')
skip 读取数据前跳过的行的数目。这个选项在跳过头注释的时候比较有用
stringsAsFactors 一个逻辑变量,标记处字符向量是否需要转化成因子。默认值是TRUE,除非它被colClases所覆盖。当你在处理大型文本文件的时候,设stringsAsFactors=FALSE
可以提升处理速度
text 一个指定文字进行处理的字符串。如果text 被设置了,file 应该被留空。2.3.1 节给出了一个例子
3、导入excel文件数据 待补充
4、导入XML文件 待补充
5、从网页爬去数据 待补充
6、导入SPSS数据 法一:使用foreign包中的read.spss()函数;法二:使用Hmisc包中的spss.get()函数
7、导入SAS数据 法一:使用foreign包中的read.ssd()函数;法二:使用Hmisc包中的sas.get()函数(安装有SAS的优先选择) 法三:read.sas7bdat()(未安装SAS的选择)
8、导入NetCDF数据 使用ncdf包
9、导入HDF5数据 使用foreign包中的read.dta("文件名")
10、通过数据库系统获取数据 待补充
数据集的标注:标量标签作为变量名,来表示(该向量的意义)
值标签:类型变量的标签(如:描述性别时,男=1,女=0)
处理数据对象时常用的函数:
length(object) 显示对象中元素/成分的数量
dim(object) 显示某个对象的维度
str(object) 显示某个对象的结构
class(object) 显示某个对象的类或类型
mode(object) 显示某个对象的模式
names(object) 显示某对象中各成分的名称
c(object, object,...) 将对象合并入一个向量
cbind(object, object, ...) 按列合并对象
rbind(object, object, ...) 按行合并对象
object 输出某个对象
head(object) 列出某个对象的开始部分
tail(object) 列出某个对象的最后部分
ls() 显示当前的对象列表
rm(object, object, ...) 删除一个或更多个对象。语句rm(list = ls())将
删除当前工作环境中的几乎所有对象①
newobject <- edit(object) 编辑对象并另存为newobject
fix(object) 直接编辑对象
基本数据管理:
创建新变量的3种方法:
mydata<-data.frame(x1 = c(2, 2, 6, 4),
x2 = c(3, 4, 2, 8))
mydata$sumx <- mydata$x1 + mydata$x2
mydata$meanx <- (mydata$x1 + mydata$x2)/2
attach(mydata)
mydata$sumx <- x1 + x2
mydata$meanx <- (x1 + x2)/2
detach(mydata)
mydata <- transform(mydata,
sumx = x1 + x2,
meanx = (x1 + x2)/2)
变量的重编码:对数据框内的数据进行重新编写,例如:年龄改为年龄区间
变量的重命名(改列名):法一:fix(data.frame)调用一个交互窗口进行改写;法二:使用编码 name(data.frame)[第几列]<-"new_name"
缺失值:is.na(向量)检测缺失值是否存在
重编码某些值为缺失值:即将某些过于奇怪的值定位缺失值(NA)data$y[data$y="."]<-NA
在分析中排除缺失值:na.omit(data)排除缺失值的那一行
日期值:日期值通常以字符串的形式输入到R中,然后转化为以数值形式存储的日期变量。函数as.Date()用于执行这种转化。其语法为as.Date(x, "input_format"),其中x是字符型数据,input_format则给出了用于读入日期的适当格式:
%d 数字表示的日期(0~31) 01~31
%a 缩写的星期名 Mon
%A 非缩写星期名 Monday
%m 月份(00~12) 00~12
%b 缩写的月份 Jan
%B 非缩写月份 January
%y 两位数的年份 07
%Y 四位数的年份 2007
日期值的默认输入格式为yyyy-mm-dd。语句:
mydates <- as.Date(c("2007-06-22", "2004-02-13"))
将默认格式的字符型数据转换为了对应日期。相反,
strDates <- c("01/05/1965", "08/16/1975")
dates <- as.Date(strDates, "%m/%d/%Y")
则使用mm/dd/yyyy的格式读取数据。
Sys.Date()返回当天日期
data()返回当前的日期和时间
将日期转换为字符型变量:as.character(datas)
类型转换函数
is.numeric() as.numeric()
is.character() as.character()
is.vector() as.vector()
is.matrix() as.matrix()
is.data.frame() as.data.frame()
is.factor() as.factor()
is.logical() as.logical()
数据排序:order()降序,默认升序
数据集的合并:
向数据框添列:
要横向合并两个数据框(数据集),请使用merge()函数。在多数情况下,两个数据框是通过一个或多个共有变量进行联结的(即一种内联结,inner join)。例如:total <- merge(dataframeA, dataframeB, by="ID")
clind()横向合并
向数据框添行:
要纵向合并两个数据框(数据集),请使用rbind()函数:total <- rbind(dataframeA, dataframeB)两个数据框必须拥有相同的变量,不过它们的顺序不必一定相同。
如果dataframeA中拥有dataframeB中没有的变量,请在合并它们之前做以下某种处理:
删除dataframeA中的多余变量;
在dataframeB中创建追加的变量并将其值设为NA(缺失)。
纵向联结通常用于向数据框中添加观测。
选入(保留)变量:newdata <- leadership[, c(6:10)]选择6-10列
剔除(丢弃)变量:
myvars <- names(leadership) %in% c("q3", "q4")
newdata <- leadership[!myvars]
剔除变量q3和q4。为了理解以上语句的原理,你需要把它拆解如下。
(1) names(leadership) 生成了一个包含所有变量名的字符型向量:
c("managerID","testDate","country","gender","age","q1", "q2","q3","q4","q5")。
(2) names(leadership) %in% c("q3", "q4") 返回了一个逻辑型向量,
names(leadership)中每个匹配q3或q4的元素的值为TRUE,反之为FALSE:c(FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE)。
(3) 运算符非(!)将逻辑值反转:c(TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE,
FALSE, TRUE)。
(4) leadership[c(TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE,
TRUE)]选择了逻辑值为TRUE的列,于是q3和q4被剔除了。
在知道q3和q4是第8个和第9个变量的情况下,可以使用语句:
newdata <- leadership[c(-8,-9)]
将它们剔除。这种方式的工作原理是,在某一列的下标之前加一个减号(–)就会剔除那一列。
最后,相同的变量删除工作亦可通过:
leadership$q3 <- leadership$q4 <- NULL
简便操作:subset()
随机抽样:
sample()函数中的第一个参数是一个由要从中抽样的元素组成的向量。在这里,这个向量
是1到数据框中观测的数量,第二个参数是要抽取的元素数量,第三个参数表示无放回抽样。
sample()函数会返回随机抽样得到的元素,之后即可用于选择数据框中的行。
使用SQL操作数据框: 待补充
2018-08-07
R_数据操作_初级_03的更多相关文章
- R_数据操作_高级_04
数学函数: abs(x) 绝对值 sqrt(x) 平方根 ceiling(x) 放回不小于x的最小整数 floor(x) 不小于x的最大整数 trunc(x) 先0方向截取x的整数部分 ...
- [SQL]SQL语言入门级教材_SQL数据操作基础(二)
SQL数据操作基础(初级) netnova 于 -- :: 加贴在 数据库探讨: 为了建立交互站点,你需要使用数据库来存储来自访问者的信息.例如,你要建立一个职业介绍服务的站点,你就需要存储诸如个人简 ...
- coreData数据操作
// 1. 建立模型文件// 2. 建立CoreDataStack// 3. 设置AppDelegate 接着 // // CoreDataStack.swift // CoreDataStackDe ...
- oracle-2-sql数据操作和查询
主要内容: >oracle 数据类型 >sql建表和约束 >sql对数九的增删改 >sql查询 >oracle伪例 1.oracle的数据类型 oracle数据库的核心是 ...
- MySQL(一) -- MySQL学习路线、数据库的基础、关系型数据库、关键字说明、SQL、MySQL数据库、MySQL服务器对象、SQL的基本操作、库操作、表操作、数据操作、中文数据问题、 校对集问题、web乱码问题
1 MySQL学习路线 基础阶段:MySQL数据库的基本操作(增删改查),以及一些高级操作(视图.触发器.函数.存储过程等). 优化阶段:如何提高数据库的效率,如索引,分表等. 部署阶段:如何搭建真实 ...
- BZOJ_1858_[Scoi2010]序列操作_线段树
BZOJ_1858_[Scoi2010]序列操作_线段树 Description lxhgww最近收到了一个01序列,序列里面包含了n个数,这些数要么是0,要么是1,现在对于这个序列有五种变换操作和询 ...
- Database学习 - mysql 数据库 数据操作
mysql数据操作 查询语法 select * | field1,field1 ... from 表名 where 条件 group by 字段 having 筛选 order by 字段 limit ...
- 第八章| 2. MySQL数据库|数据操作| 权限管理
1.数据操作 SQL(结构化查询语言),可以操作关系型数据库 通过sql可以创建.修改账号并控制账号权限: 通过sql可以创建.修改数据库.表: 通过sql可以增删改查数据: 可以通过SQL语句中 ...
- MySQL表操作及数据操作
表操作 表相当于一个文件,其形式与现实中的表格相同.表中的每条记录都有相应的字段,字段就类似于表格的表头. 表操作详细: #对表进行操作(文件) #首先要切换到指定库(即文件夹)下:use db1; ...
随机推荐
- ISO/IEC 9899:2011 条款6.4——词法元素
6.4 词法元素 1.token(标记): keyword(关键字) identifier(标识符) constant(常量) string-literal(字符串字面量) punctuator(标点 ...
- 004-行为型-05-职责链模式(Chain of Responsibility)
一.概述 为请求创建一个接收此次请求对象的链 该模式构造一系列分别担当不同的职责的类的对象来共同完成一个任务,这些类的对象之间像链条一样紧密相连,所以被称作职责链模式. 在这种模式中,通常每个接收者都 ...
- matlab基本函数find
一起来学演化计算-matlab基本函数find 觉得有用的话,欢迎一起讨论相互学习~Follow Me 找到非零元素的索引和值 语法 k = find(X) k = find(X)返回一个向量,其中包 ...
- Linux系统调优——磁盘I/O(三)
(1).查看I/O运行状态相关工具 1)查看文件系统块大小 对于ext4文件系统,查看文件系统块大小 [root@CentOS6 ~]# tune2fs -l /dev/sda1 | grep siz ...
- mybatis 级联
级联是一个数据库实体的概念.一对多的级联,一对多的级联,在MyBatis中还有一种被称为鉴别器的级联,它是一种可以选择具体实现类的级联. 级联不是必须的,级联的好处是获取关联数据十分便捷,但是级联过多 ...
- 0010.Regular Expression Matching(H)
jjc . Regular Expression Matching(hard) Given an input string (s) and a pattern (p), implement regul ...
- 【Leetcode_easy】860. Lemonade Change
problem 860. Lemonade Change solution class Solution { public: bool lemonadeChange(vector<int> ...
- velocity 自定义工具类接入
网上的教程几乎都是同一篇: velocity 自定义工具类 - eggtk - CSDN 博客 但是教程有不完善的地方,我就补充一下. 补充: 引入的jar包和版本要一致.我们项目中因为没有定义确切版 ...
- 初步了解 Netty
精通并发与 Netty (一)如何使用 精通并发与 Netty Netty 是一个异步的,事件驱动的网络通信框架,用于高性能的基于协议的客户端和服务端的开发. 异步指的是会立即返回,并不知道到底发送过 ...
- springboot的mapper.xml在src下问题
在pom.xml里面的build标签加上resources说明 <resources> <!-- mapper.xml文件在java目录下 --> <resource&g ...