基于Keras 的VGG16神经网络模型的Mnist数据集识别并使用GPU加速
这段话放在前面:之前一种用的Pytorch,用着还挺爽,感觉挺方便的,但是在最近文献的时候,很多实验都是基于Google 的Keras的,所以抽空学了下Keras,学了之后才发现Keras相比Pytorch而言,基于keras来写神经网络的话太方便,因为Keras高度的封装性,所以基于Keras来搭建神经网络很简单,在Keras下,可以用两种两种方法来搭建网络模型,分别是Sequential()与Model(),对于网络结构简单,层次较少的模型使用sequential方法较好,只需不断地model.add即可,而后者更适用于网络模型复杂的情况,各有各的好处。
论GPU的重要性:在未使用GPU之前,一直用的CPU来训练,那速度,简直是龟速,一个VGG16花了10个小时,费时费力还闹心,然后今天将它加载在实验室的服务器上,只花了不到半个小时就好了。

下面给出代码:
#!/usr/bin/env python 3.6
#_*_coding:utf-8 _*_
#@Time :2019/11/9 15:19
#@Author :hujinzhou
#@FileName: My_frist_keras_moudel.py #@Software: PyCharm
from keras.datasets import mnist
from call_back import LossHistory
from keras.utils.np_utils import to_categorical
import numpy as np
import cv2
import pylab
from keras.optimizers import Adam,SGD
from matplotlib import pyplot as plt
from keras.utils.vis_utils import plot_model
from keras.layers import Dense, Activation, Flatten,Convolution2D,MaxPool2D,Dropout,BatchNormalization
from keras.models import Sequential, Model
from keras.layers.normalization import BatchNormalization
np.random.seed(10)
"""下载mnist数据集,x_train训练集的数据,y_train训练集的标签,测试集依次类推"""
(x_train,y_train),(x_test,y_test)=mnist.load_data()
print(x_train.shape)
print(len(x_train))
print(y_train[0])
"-----------------------------------------------------------------------------------------"
"""通过迭代的方法将训练集中的数据整形为32*32"""
x_train4D = [cv2.cvtColor(cv2.resize(i,(32,32)), cv2.COLOR_GRAY2BGR) for i in x_train]
x_train4D = np.concatenate([arr[np.newaxis] for arr in x_train4D]).astype('float32') x_test4D = [cv2.cvtColor(cv2.resize(i,(32,32)), cv2.COLOR_GRAY2BGR) for i in x_test]
x_test4D = np.concatenate([arr[np.newaxis] for arr in x_test4D]).astype('float32')
print(x_test4D.shape)
print(x_train4D.shape)
"------------------------------------------------------------------------------------"
plt.imshow(x_train4D[0],cmap='gray')
pylab.show()
#x_train4D = x_train4D.astype('float32')
#x_test4D = x_test4D.astype('float32')
"""归一化"""
x_test4D_normalize=x_test4D/255
x_train4D_normalize=x_train4D/255 """one_hot encoding"""
y_trainOnehot=to_categorical(y_train)
y_testOnehot=to_categorical(y_test) """建立模型"""
"--------------------------------------------------------------------------"
model=Sequential()
model.add(Convolution2D(filters=64,
kernel_size=(5,5),
padding='same',
input_shape=(32,32,3), kernel_initializer='he_normal',
name='cnn1' )
)#output32*32*64
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu')) # model.add(Convolution2D(filters=64,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn2'
# )
# )#output32*32*64
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2, 2)))#output16*16*64 model.add(Convolution2D(filters=128,
kernel_size=(5,5),
padding='same', kernel_initializer='he_normal',
name='cnn3'
)
)#output16*16*128
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
# model.add(Convolution2D(filters=128,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn4'
# )
# )#output16*16*128
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2, 2)))#output8*8*128 model.add(Convolution2D(filters=256,
kernel_size=(5,5),
padding='same', kernel_initializer='he_normal',
name='cnn5'
)
)#output8*8*256
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
# model.add(Convolution2D(filters=256,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn6'
# )
# )#output8*8*256
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
# model.add(Convolution2D(filters=256,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn7'
# )
# )#output8*8*256
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2, 2)))#output4*4*256
model.add(Convolution2D(filters=512,
kernel_size=(5,5),
padding='same', kernel_initializer='he_normal',
name='cnn8'
)
)#output4*4*512
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
# model.add(Convolution2D(filters=512,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn9'
# )
# )#output4*4*512
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
# model.add(Convolution2D(filters=512,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn10'
# )
# )#output4*4*512
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2, 2)))#output2*2*512
model.add(Convolution2D(filters=512,
kernel_size=(5,5),
padding='same', kernel_initializer='he_normal',
name='cnn11'
)
)#output2*2*512
model.add(BatchNormalization(axis=-1))
model.add(Activation('relu'))
# model.add(Convolution2D(filters=512,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn12'
# )
# )#output2*2*512
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
# model.add(Convolution2D(filters=512,
# kernel_size=(5,5),
# padding='same',
#
# kernel_initializer='he_normal',
# name='cnn13'
# )
# )#output2*2*512
# model.add(BatchNormalization(axis=-1))
# model.add(Activation('relu'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2, 2)))#output1*1*512
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()
plot_model(model,to_file='model4.png',show_shapes=True,show_layer_names=True)
# for layer in model.layers:
# layer.trainable=False
"--------------------------------------------------------------------------------"
"""训练模型"""
adam=SGD(lr=0.1)
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
epoch=5
batchsize=100
# from keras.models import load_model
# model = load_model('./My_keras_model_weight')
history=model.fit(x=x_train4D_normalize,
y=y_trainOnehot,
epochs=epoch,
batch_size=batchsize,
validation_data=(x_test4D_normalize,y_testOnehot)) """保存模型"""
model.save('./My_keras_model2_weight') #model.load('./My_keras_model_weight')
"""画出损失曲线"""
training_loss=history.history["loss"]
train_acc=history.history["acc"]
test_loss=history.history["val_loss"]
test_acc=history.history["val_acc"] epoch_count=range(1,len(training_loss)+1)
plt.plot(epoch_count,training_loss,'r--')
plt.plot(epoch_count,test_loss,'b--')
plt.plot(epoch_count,train_acc,'r--')
plt.plot(epoch_count,test_acc,'b--')
plt.legend(["Training_loss","Test_loss","train_acc","test_acc"])
plt.xlabel("Epoch")
plt.ylabel("loss")
plt.show()
结果如下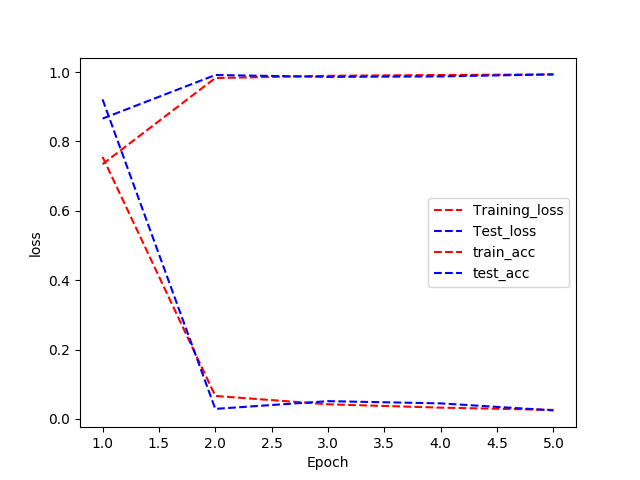
最终的精度可以达到0.993左右
loss: 0.0261 - acc: 0.9932 - val_loss: 0.0246 - val_acc: 0.9933
基于Keras 的VGG16神经网络模型的Mnist数据集识别并使用GPU加速的更多相关文章
- 使用PyTorch构建神经网络模型进行手写识别
使用PyTorch构建神经网络模型进行手写识别 PyTorch是一种基于Torch库的开源机器学习库,应用于计算机视觉和自然语言处理等应用,本章内容将从安装以及通过Torch构建基础的神经网络,计算梯 ...
- 一个简单的TensorFlow可视化MNIST数据集识别程序
下面是TensorFlow可视化MNIST数据集识别程序,可视化内容是,TensorFlow计算图,表(loss, 直方图, 标准差(stddev)) # -*- coding: utf-8 -*- ...
- 【Keras篇】---利用keras改写VGG16经典模型在手写数字识别体中的应用
一.前述 VGG16是由16层神经网络构成的经典模型,包括多层卷积,多层全连接层,一般我们改写的时候卷积层基本不动,全连接层从后面几层依次向前改写,因为先改参数较小的. 二.具体 1.因为本文中代码需 ...
- Keras学习:第一个例子-训练MNIST数据集
import numpy as npimport gzip import struct import keras as ks import logging from keras.layers impo ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- CNN算法解决MNIST数据集识别问题
网络实现程序如下 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 用于设置将记 ...
- Keras学习环境配置-GPU加速版(Ubuntu 16.04 + CUDA8.0 + cuDNN6.0 + Tensorflow)
本文是个人对Keras深度学习框架配置的总结,不周之处请指出,谢谢! 1. 首先,我们需要安装Ubuntu操作系统(Windows下也行),这里使用Ubuntu16.04版本: 2. 安装好Ubunt ...
- 机器学习与Tensorflow(3)—— 机器学习及MNIST数据集分类优化
一.二次代价函数 1. 形式: 其中,C为代价函数,X表示样本,Y表示实际值,a表示输出值,n为样本总数 2. 利用梯度下降法调整权值参数大小,推导过程如下图所示: 根据结果可得,权重w和偏置b的梯度 ...
- Keras结合Keras后端搭建个性化神经网络模型(不用原生Tensorflow)
Keras是基于Tensorflow等底层张量处理库的高级API库.它帮我们实现了一系列经典的神经网络层(全连接层.卷积层.循环层等),以及简洁的迭代模型的接口,让我们能在模型层面写代码,从而不用仔细 ...
随机推荐
- C#上传下载文件
方法一.通过Ajax方式上传文件(input file),使用FormData进行Ajax请求 <div > <input type="file" name=& ...
- Sort a list(tuple,dict)
FROM:https://www.pythoncentral.io/how-to-sort-python-dictionaries-by-key-or-value/ AND https://www.p ...
- Guardian of Decency POJ - 2771 【二分匹配,最大独立集】
Problem DescriptionFrank N. Stein is a very conservative high-school teacher. He wants to take some ...
- PHP mysqli_error_list() 函数
返回最近调用函数的最后一个错误代码: <?php // 假定数据库用户名:root,密码:123456,数据库:RUNOOB $con=mysqli_connect("localhos ...
- [Hdoj] Fast Matrix Calculation
题面:http://acm.hdu.edu.cn/showproblem.php?pid=4965 题解:https://www.zybuluo.com/wsndy-xx/note/1153981
- 【csp模拟赛3】bridge.cpp--矩阵加速递推
题目描述 穿越了森林,前方有一座独木桥,连接着过往和未来(连接着上一题和下一题...). 这座桥无限长. 小 Q 在独木桥上彷徨了.他知道,他只剩下了 N 秒的时间,每一秒的时间里,他会向 左或向右移 ...
- JavaScript中BOM的重要内容总结
一.BOM介绍 BOM(Browser Object Model),浏览器对象模型: 用来操作浏览器部分功能的API: BOM由一系列的对象构成,由于主要用于管理窗口和窗口之间的通讯,所以核心对象是w ...
- Python学习日记(四)——Python基本数据类型梳理(int、str、list、tuple、dict)
数字(int) 1.创建方式 n1 = 123 n2 = int(123) 2.内存分配 #共同用一个内存地址的情况 n1 = 123 n2 = n1 #用两个内存地址的情况 n1 = 123 n2 ...
- Atcoder ABC 139A
Atcoder ABC 139A 题意: 给你两个字符串,记录对应位置字符相同的个数 $ (n=3) $ 解法: 暴力枚举. CODE: #include<iostream> #inclu ...
- 调皮捣蛋的Linux下有趣终端的合集
*本文作者:国光,转载自 FreeBuf.COM,原文地址:https://www.freebuf.com/news/144050.html 前言 刚开始接触Linux的我们,肯定认为Linux系统就 ...