java源码 -- TreeSet
这个TreeSet其实和HashSet类似。HashSet底层是通过HashMap实现的,TreeSet其实底层也是通过TreeMap实现的。
简介
TreeSet的作用是保存无重复的数据,不过还对这些数据进行了排序。
TreeMap的底层是通过红黑树实现的,所以TreeSet底层也是通过红黑树实现的。
TreeSet最主要的特点就是对元素进行了排序。我们对其特点进行总结一下:
(1)TreeSet是基于TreeMap的NavigableSet实现。
(2)TreeSet的元素存储在TreeMap中的key中,TreeMap的value是一个常量对象。
(3)非线程安全 。
(4)java8新增分割器spliterator() 方法。
源码分析
1.继承关系
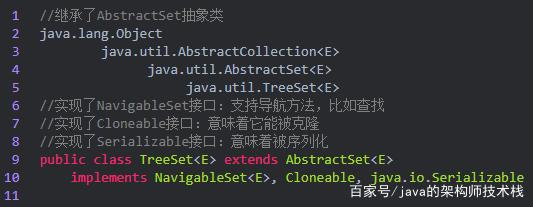
2.参数变量

3.构造器
// 直接使用传进来的NavigableMap存储元素
// 这里不是深拷贝,如果外面的map有增删元素也会反映到这里
// 而且, 这个方法不是public的, 说明只能给同包使用
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
} // 使用TreeMap初始化
public TreeSet() {
this(new TreeMap<E,Object>());
} // 使用带comparator的TreeMap初始化
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
} // 将集合c中的所有元素添加的TreeSet中
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
} // 将SortedSet中的所有元素添加到TreeSet中
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
4 方法
// 迭代器
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
} // 逆序迭代器
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
} // 以逆序返回一个新的TreeSet
public NavigableSet<E> descendingSet() {
return new TreeSet<>(m.descendingMap());
} // 元素个数
public int size() {
return m.size();
} // 判断是否为空【本篇文章由公众号“彤哥读源码”原创】
public boolean isEmpty() {
return m.isEmpty();
} // 判断是否包含某元素
public boolean contains(Object o) {
return m.containsKey(o);
} // 添加元素, 调用map的put()方法, value为PRESENT
public boolean add(E e) {
return m.put(e, PRESENT)==null;
} // 删除元素
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
} // 清空所有元素
public void clear() {
m.clear();
} // 添加集合c中的所有元素
public boolean addAll(Collection<? extends E> c) {
// 满足一定条件时直接调用TreeMap的addAllForTreeSet()方法添加元素
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<?> cc = set.comparator();
Comparator<? super E> mc = map.comparator();
if (cc==mc || (cc != null && cc.equals(mc))) {
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
// 不满足上述条件, 调用父类的addAll()通过遍历的方式一个一个地添加元素
return super.addAll(c);
} // 子set(NavigableSet中的方法)
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
} // 头set(NavigableSet中的方法)
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new TreeSet<>(m.headMap(toElement, inclusive));
} // 尾set(NavigableSet中的方法)
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<>(m.tailMap(fromElement, inclusive));
} // 子set(SortedSet接口中的方法)
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
} // 头set(SortedSet接口中的方法)
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
} // 尾set(SortedSet接口中的方法)
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
} // 比较器
public Comparator<? super E> comparator() {
return m.comparator();
} // 返回最小的元素
public E first() {
return m.firstKey();
} // 返回最大的元素
public E last() {
return m.lastKey();
} // 返回小于e的最大的元素
public E lower(E e) {
return m.lowerKey(e);
} // 返回小于等于e的最大的元素
public E floor(E e) {
return m.floorKey(e);
} // 返回大于等于e的最小的元素
public E ceiling(E e) {
return m.ceilingKey(e);
} // 返回大于e的最小的元素
public E higher(E e) {
return m.higherKey(e);
} // 弹出第一个的元素,就是最小元素
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry();
return (e == null) ? null : e.getKey();
}
//弹出最后一个元素,就是最大元素
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry();
return (e == null) ? null : e.getKey();
} // 克隆方法
@SuppressWarnings("unchecked")
public Object clone() {
TreeSet<E> clone;
try {
clone = (TreeSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
} clone.m = new TreeMap<>(m);
return clone;
} // 序列化写出方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out any hidden stuff
s.defaultWriteObject(); // Write out Comparator
s.writeObject(m.comparator()); // Write out size
s.writeInt(m.size()); // Write out all elements in the proper order.
for (E e : m.keySet())
s.writeObject(e);
} // 序列化写入方法
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in any hidden stuff
s.defaultReadObject(); // Read in Comparator
@SuppressWarnings("unchecked")
Comparator<? super E> c = (Comparator<? super E>) s.readObject(); // Create backing TreeMap
TreeMap<E,Object> tm = new TreeMap<>(c);
m = tm; // Read in size
int size = s.readInt(); tm.readTreeSet(size, s, PRESENT);
} // 可分割的迭代器
public Spliterator<E> spliterator() {
return TreeMap.keySpliteratorFor(m);
} // 序列化id
private static final long serialVersionUID = -2479143000061671589L;
总结
(1)TreeSet底层使用NavigableMap存储元素; (2)TreeSet是有序的【本篇文章由公众号“彤哥读源码”原创】; (3)TreeSet是非线程安全的; (4)TreeSet实现了NavigableSet接口,而NavigableSet继承自SortedSet接口; (5)TreeSet实现了SortedSet接口;
彩蛋
(1)通过之前的学习,我们知道TreeSet和LinkedHashSet都是有序的,那它们有何不同?
LinkedHashSet并没有实现SortedSet接口,它的有序性主要依赖于LinkedHashMap的有序性,所以它的有序性是指按照插入顺序保证的有序性;
而TreeSet实现了SortedSet接口,它的有序性主要依赖于NavigableMap的有序性,而NavigableMap又继承自SortedMap,这个接口的有序性是指按照key的自然排序保证的有序性,
而key的自然排序又有两种实现方式,一种是key实现Comparable接口,一种是构造方法传入Comparator比较器。
(2)TreeSet里面真的是使用TreeMap来存储元素的吗?
通过源码分析我们知道TreeSet里面实际上是使用的NavigableMap来存储元素,虽然大部分时候这个map确实是TreeMap,但不是所有时候都是TreeMap。
因为有一个构造方法是TreeSet(NavigableMap<E,Object> m),而且这是一个非public方法,通过调用关系我们可以发现这个构造方法都是在自己类中使用的,比如下面这个:
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<>(m.tailMap(fromElement, inclusive));
}而这个m我们姑且认为它是TreeMap,也就是调用TreeMap的tailMap()方法:
public NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) {
return new AscendingSubMap<>(this,
false, fromKey, inclusive,
true, null, true);
}可以看到,返回的是AscendingSubMap对象,这个类的继承链是怎么样的呢?
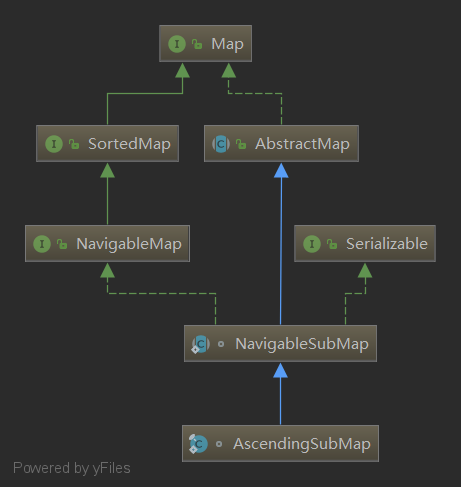
可以看到,这个类并没有继承TreeMap,不过通过源码分析也可以看出来这个类是组合了TreeMap,也算和TreeMap有点关系,只是不是继承关系。
所以,TreeSet的底层不完全是使用TreeMap来实现的,更准确地说,应该是NavigableMap。
对于HashSet是用Hash表来存储数据,而TreeSet是用二叉树来存储数据。
在不需要排序的时候,还是建议优先使用HashSet,因为速度更快;二叉树需要排序就免不了跳转旋转,所以速度会很慢。
java源码 -- TreeSet的更多相关文章
- 【java集合框架源码剖析系列】java源码剖析之TreeSet
本博客将从源码的角度带领大家学习TreeSet相关的知识. 一TreeSet类的定义: public class TreeSet<E> extends AbstractSet<E&g ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- Programming a Spider in Java 源码帖
Programming a Spider in Java 源码帖 Listing 1: Finding the bad links (CheckLinks.java) import java.awt. ...
- 解密随机数生成器(二)——从java源码看线性同余算法
Random Java中的Random类生成的是伪随机数,使用的是48-bit的种子,然后调用一个linear congruential formula线性同余方程(Donald Knuth的编程艺术 ...
- Java--Eclipse关联Java源码
打开Eclipse,Window->Preferences->Java 点Edit按钮后弹出: 点Source Attachment后弹出: 选择Java安装路径下的src.zip文件即可 ...
- 使用JDT.AST解析java源码
在做java源码的静态代码审计时,最基础的就是对java文件进行解析,从而获取到此java文件的相关信息: 在java文件中所存在的东西很多,很复杂,难以用相关的正则表达式去一一匹配.但是,eclip ...
随机推荐
- windows server2012 搭建.netcore+nginx+nssm运行环境
1.linux+.netcore+sqlserver的坑 linux不支持访问sqlserver2008及以下的版本(由于System.Data.SqlClient.dll的限制.windows上面访 ...
- mvn ssm 异常 org.springframework.beans.factory.BeanCreationException:Error creating bean with name 'multipartResolver'
解决方案: 添加 commons-fileupload-1.2.jar <!-- https://mvnrepository.com/artifact/commons-fileupload/co ...
- 一个类中域(field)的首字母不要大写
首先这种写法不规范, 其次,至少在AJAX交互的情况下, 如果首字母大写,会无法与前端相同名称的JSON属性相绑定. 如 data:{'Name':'2017-10-19'} public NameI ...
- linux 编写定时任务,查询服务是否挂掉
shell 脚本 #!/bin/bash a=`netstat -unltp|grep fdfs|wc -l` echo "$a" if [ "$a" -ne ...
- 第五章、web服务器
一.web服务器 Web服务器就是整个万维网的骨干,广义上来说Web服务器既可以用来表示Web服务器的软件,也可以用来表示提供Web页面的特定设备和计算机.我们在网络上获取的所以资源,都需要有服务器来 ...
- 小程序开发--WePy框架
现如今mvvm框架如此火热,其核心思想即js逻辑层不直接操作DOM,只改变组件状态:而视图层则通过模板template进行渲染. 1.WePy项目的目录结构 ├── dist 小程序运行代码目录 ├─ ...
- 网络中的tarpit/tar pit
最近看haproxy源码,里面有个TARPIT的概念不能理解,找了很久才找到对应的意思.特此记录. tarpit 本意是“沼泽地.地洼地”,这里显然把它引申为“捕获或者困住某个物体”. 在网络语义中提 ...
- Mybatis 中的转义字符(转帖)
下文来自:https://www.cnblogs.com/dato/p/7028723.html 在此感谢作者的辛勤付出. 记录以下mybatis中的转义字符,方便以后自己看一下 Mybatis转义 ...
- 项目管理工具-OmniPlan 3 for Mac
链接:https://pan.baidu.com/s/1tp_37fHXHwJuklL1nNSwig 密码:l0sf 激活迷药(里面自带的keygen不能用,用这个好使): Name: Appked ...
- 连接池设置导致的“血案” 原创: 一页破书 一页破书 5月6日 这个问题被投诉的几个月了,一直没重视——内部客户嘛😿 问题现象: 隔几周就会出现 A服务调用B服务超时 脚趾头想就是防火墙的问题,A、B两服务之间有防火墙 找运维查看防火墙日志确实断掉了tcp连接,但是是因为B服务5分钟没有回包,下面这个表情就是我当时的心情——其实我们在防火墙、A服务、B服务都抓包了,几十个G的t
连接池设置导致的“血案” 原创: 一页破书 一页破书 5月6日 这个问题被投诉的几个月了,一直没重视——内部客户嘛