Hadoop集群分布搭建
一、准备工作
1、最少三台虚拟机或者实体机(官网上是默认是3台),我这边是3台
s1: 10.211.55.18
s2: 10.211.55.19
s3: 10.211.55.20
2、安装JDK
3、配置SSH
4、修改hosts 文件vi /etc/hosts
在文件中添加:
地址 主机名 10.211.55.18 s1 10.211.55.19 s2 10.211.55.20 s3
5、下载hadoop
二、安装hadoop
1、解压hadoop2.9.0
mkdir -r /usr/soft tar -zxvf hadoop2..0.tar.gz -C /usr/soft #解压到/usr/soft
2、配置环境变量(ps:我这边是centos7)
cd /etc/profile.d/ touch hadoop_envi.sh #创建脚本 vi hadoop_envi.sh #编辑脚本
以下都是 hadoop_envi.sh 文件里面内容,也是添加环境变量
HADOOP_INSTALL=/usr/soft/hadoop-2.9. PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin export HADOOP_INSTALL export PATH
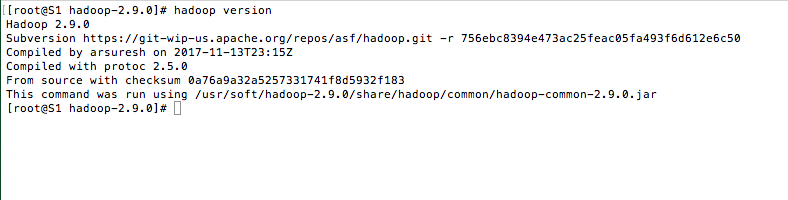
3、测试
hadoop version
三、编写hadoop配置文件,配置文件都在 hadoop2.9.0/etc/hadoop/ 下
1、core-site.xml 通用配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadooptmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>fs.defaultFS</name> #NameNode ip
<value>hdfs://s1/</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name> #资源管理器的主机
<value>s1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3. hdfs-site.xml 分布式文件相关配置
<configuration> <property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hdsf/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name> #文件块的备份数量 默认3个, 2、3都可以
<value></value>
</property> </configuration>
4. mapre-site.xml 这个问题通过 mapred-site.xml.template复制而来的
<configuration>
<property>
<name>mapreduce.framework.name</name> #MapReduce框架名称
<value>yarn</value>
</property>
</configuration>
5、编辑slave
vi slaves
以下是 slaves 需要添加的内容
s2 #表示s2和s3 为数据节点,s2就是 10.211.55.19,s3就是 10.211.55.20
s3
四、启动hadoop
hadoop namenode -format #

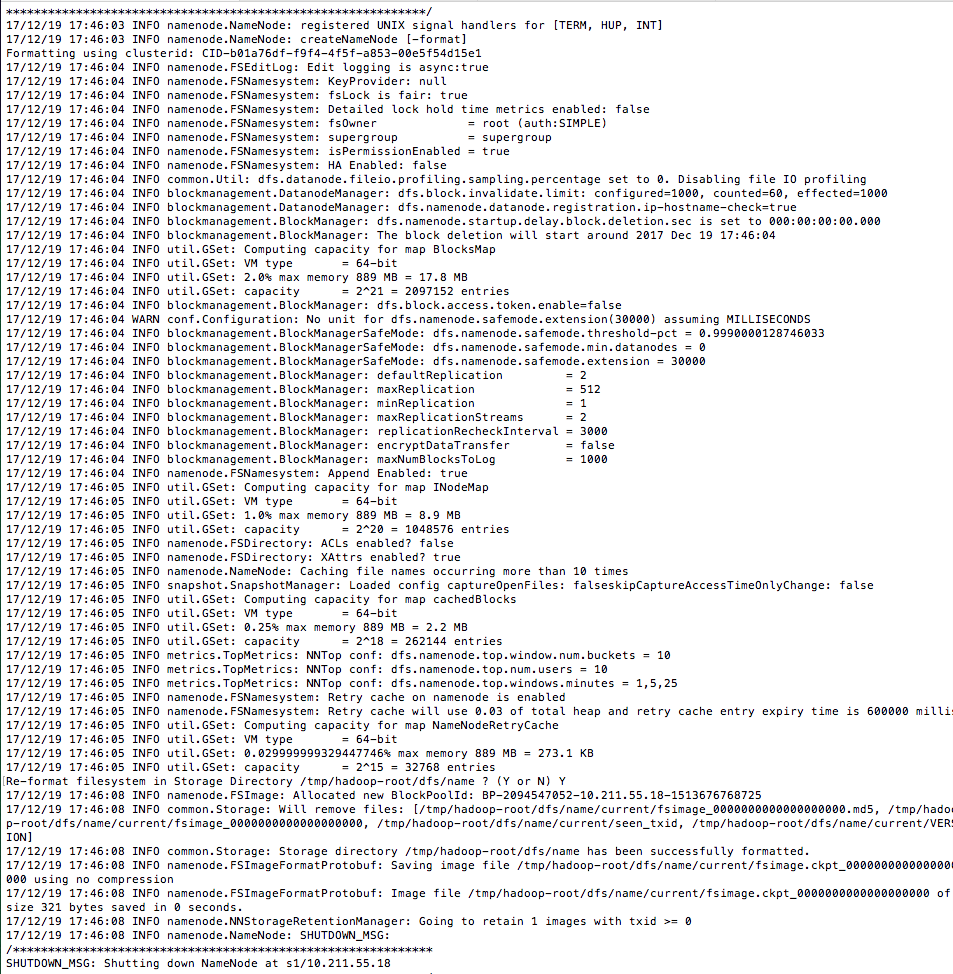
名称节点格式化成功
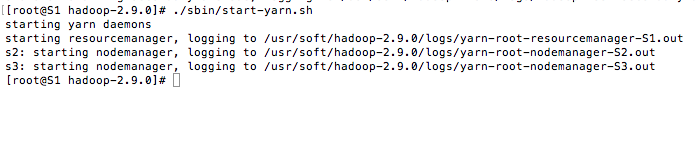
启动 dfs 和 yarn 这两个脚本文件都在 hadoop2.9.0/sbin 下
./sbin/start-dfs.sh

./sbin/start-yarn.sh
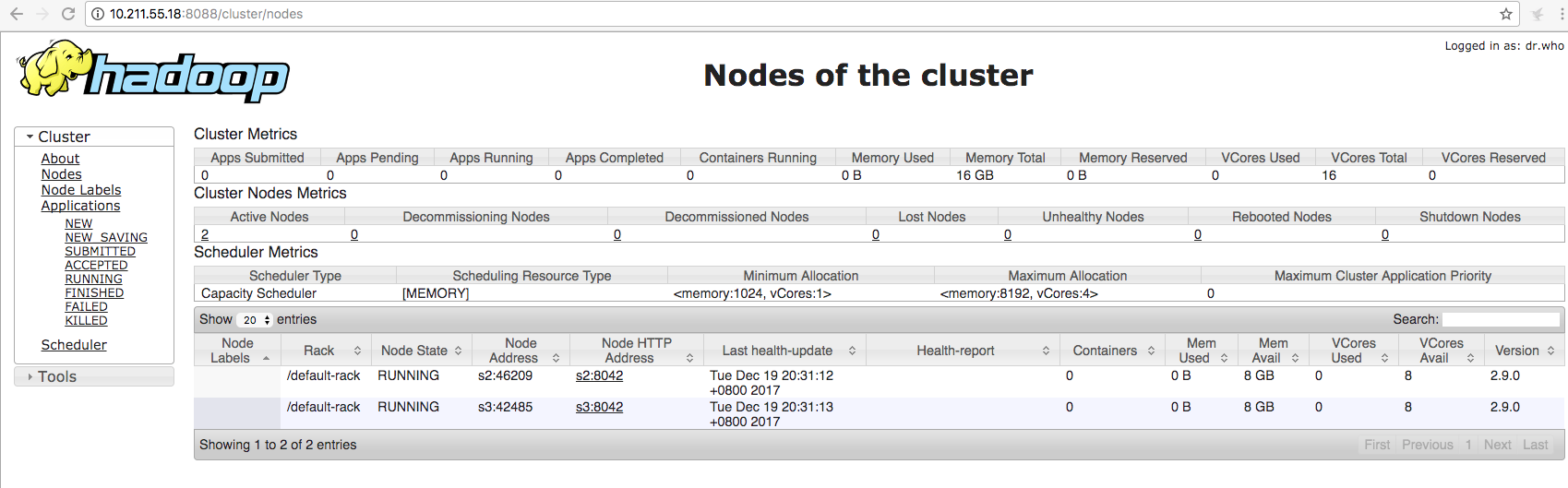
五、测试hadoop
前提:开发8088 和 50070端口 10.211.55.18是namenode 节点
http://10.211.55.18:8088
http://10.211.55.18:50070/

Hadoop集群分布搭建的更多相关文章
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- hadoop集群的搭建与配置(2)
对解压过后的文件进行从命名 把"/usr/hadoop"读权限分配给hadoop用户(非常重要) 配置完之后我们要创建一个tmp文件供以后的使用 然后对我们的hadoop进行配置文 ...
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...
- 关于hadoop集群管理系统搭建的规划说明
Hadoop集群管理系统搭建是每个入门级新手都非常头疼的事情,因为你可能花费了很久的时间在搭建运行环境,最终却不知道什么原因无法创建成功.但对新手来说,运行环境搭建不成功的概率还蛮高的. 在之前的分享 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- Hadoop集群上搭建Ranger
There are two types of people in the world. I hate both of them. Hadoop集群上搭建Ranger 在搭建Ranger工程之前,需要完 ...
随机推荐
- [Oracle] - 关于星期(IW和WW)的算法
1. 查看数据库字符集(如果字符集不同,可能显示乱码) select DECODE(parameter, 'NLS_TERRITORY', 'TERRITORY', 'NLS_LANGUAGE', ' ...
- Zuul【文件上传】
1.搭建一个eureka-server注册中心工程 该工程比较简洁,没有太多配置,不在描述,单节点,服务端口:8888 2.创建zuul-gateway网关工程 2.1.工程pom依赖 <dep ...
- Object 方法的 hashCode,equals方法源码
文章目录 hashCode方法注释 equals 方法注释 equals 方法 hashCode方法注释 Object 的 hashCode 方法,是本地方法: Returns a hash code ...
- 【Linux】一步一步学Linux——Linux版本(03)
目录 00. 目录 01. Linux内核版本 02. Linux内核官方网站 03. Linux发行版本 04. Linux发行版本介绍 4.1 Ubuntu 4.2 RedHat 4.3 Debi ...
- errgroup 分析
errgroup 在 WaitGroup 的基础上实现子协程错误传递, 同时使用 context 控制协程的生命周期. 使用 errgroup 的使用非常简单 package main import ...
- Scratch 少儿编程之旅(四)— Scratch入门动画《小猫捉蝴蝶》(中)
本期内容概括: 了解Scratch的更多操作,用[无限循环]来更改“小猫”角色的代码: 添加[碰到边缘就反弹]积木块指令: 更改角色的旋转模式和造型,让”小猫”走路更生动: 两种[循环]语句的区别: ...
- Windows下的Android Studio环境搭建、安装使用
https://jingyan.baidu.com/article/20b68a88ff2ca4796cec6232.html https://blog.csdn.net/jklinux/articl ...
- 多个div并排不换行
1.所有div的父元素不换行 white-space: nowrap; 2.所有div设置为行内元素 display: inline-block; 基于java记账管理系统[尚学堂·百战程序员]
- English-培训6-Do you like rap?
- [原]Object-Oriented Programming With ANSI-C
前一段时间面试被问到一个问题,怎么用C去实现面向对象的特性,比如封装.继承和多态.我心想这不是闲的蛋疼么,好吧,我承认我不会...[大哭].然后去网上找相关的文章,有文章推荐了<Object-O ...