关于MapReduce的测试
题目:数据清洗以及结果展示
要求:
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip: 城市 city(IP)
time: 2016-11-10 00:01:03
day: 10
traffic: 62
type: article/video
id: 11325
(3)hive数据库表结构:
create table data01(ip string, time string, day string, traffic bigint, type string, id string)
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
解答:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
1.1 数据清洗
原始数据格式
将原始数据文件result.txt上传到HDFS中,然后进行读取清洗
cleanDate.java:(读取清洗)
package com.Use; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class cleanData {
public static class Map extends Mapper<Object , Text , Text , IntWritable>{
private static Text newKey=new Text();
private static String chage(String data) {
char[] str = data.toCharArray();
String[] time = new String[7];
int j = 0;
int k = 0;
for(int i=0;i<str.length;i++) {
if(str[i]=='/'||str[i]==':'||str[i]==32) {
time[k] = data.substring(j,i);
j = i+1;
k++;
}
}
time[k] = data.substring(j, data.length()); switch(time[1]) { case "Jan":time[1]="01";break; case
"Feb":time[1]="02";break; case "Mar":time[1]="03";break; case
"Apr":time[1]="04";break; case "May":time[1]="05";break; case
"Jun":time[1]="06";break; case "Jul":time[1]="07";break; case
"Aug":time[1]="08";break; case "Sep":time[1]="09";break; case
"Oct":time[1]="10";break; case "Nov":time[1]="11";break; case
"Dec":time[1]="12";break; } data = time[2]+"-"+time[1]+"-"+time[0]+" "+time[3]+":"+time[4]+":"+time[5];
return data;
}
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
String line=value.toString();
System.out.println(line);
String arr[]=line.split(","); String ip = arr[0];
String date = arr[1];
String day = arr[2];
String traffic = arr[3];
String type = arr[4];
String id = arr[5]; date = chage(date);
traffic = traffic.substring(0, traffic.length()-1); newKey.set(ip+'\t'+date+'\t'+day+'\t'+traffic+'\t'+type);
//newKey.set(ip+','+date+','+day+','+traffic+','+type);
int click=Integer.parseInt(id);
context.write(newKey, new IntWritable(click));
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
for(IntWritable val : values){
context.write(key, val);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
System.out.println("start");
Job job =new Job(conf,"cleanData");
job.setJarByClass(cleanData.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path in=new Path("hdfs://192.168.137.112:9000/tutorial/in/result.txt");
Path out=new Path("hdfs://192.168.137.112:9000/tutorial/out");
FileInputFormat.addInputPath(job,in);
FileOutputFormat.setOutputPath(job,out);
System.exit(job.waitForCompletion(true) ? 0 : 1); }
}
CleanData
清洗后格式
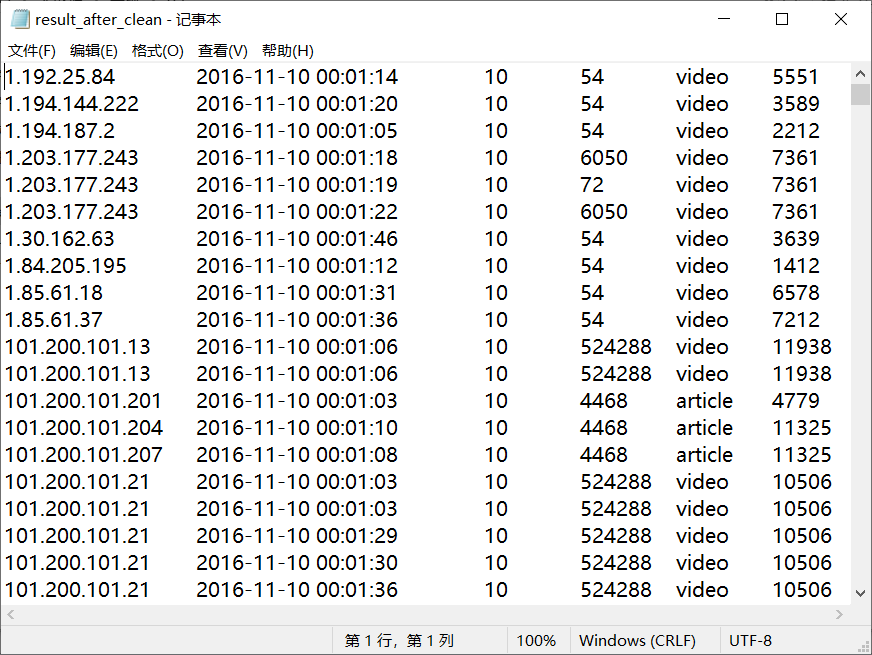
2、数据处理:
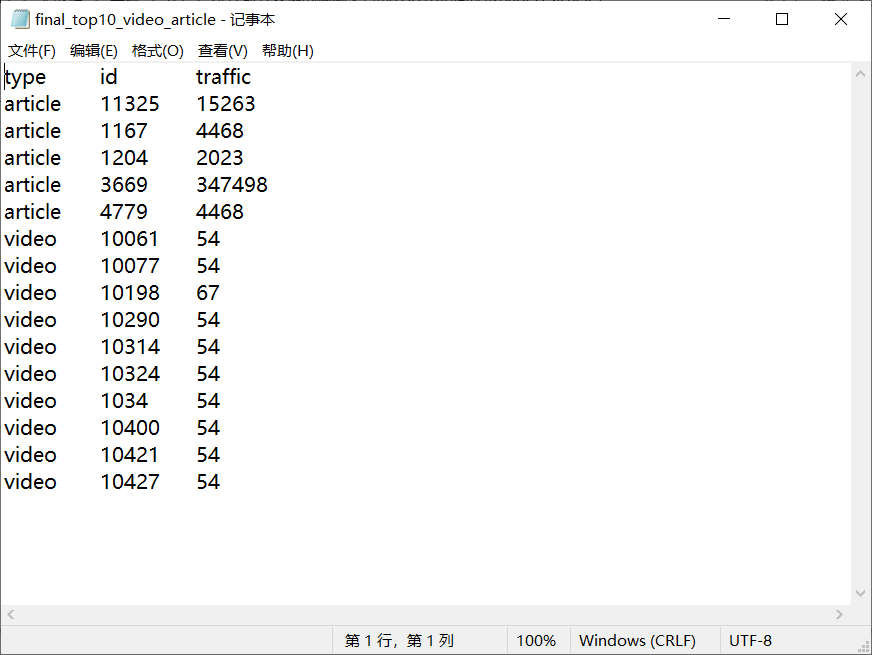
2.1统计最受欢迎的视频/文章的Top10访问次数 (video/article)
读取清洗后数据的.txt文件进行mapreduce
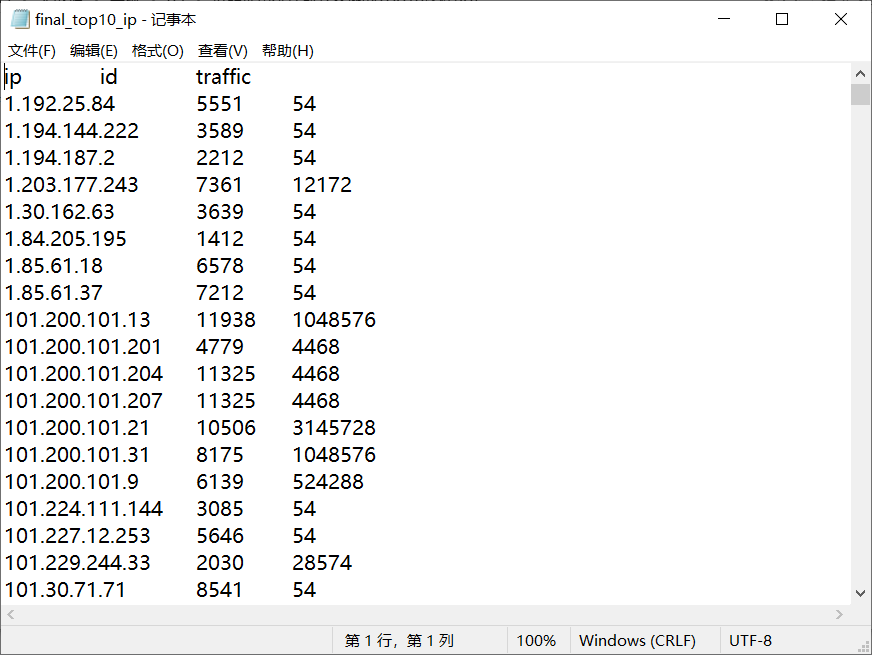
2.2按照地市统计最受欢迎的Top10课程 (ip)
读取清洗后数据的.txt文件进行mapreduce
2.3按照流量统计最受欢迎的Top10课程 (traffic)
读取清洗后数据的.txt文件进行mapreduce
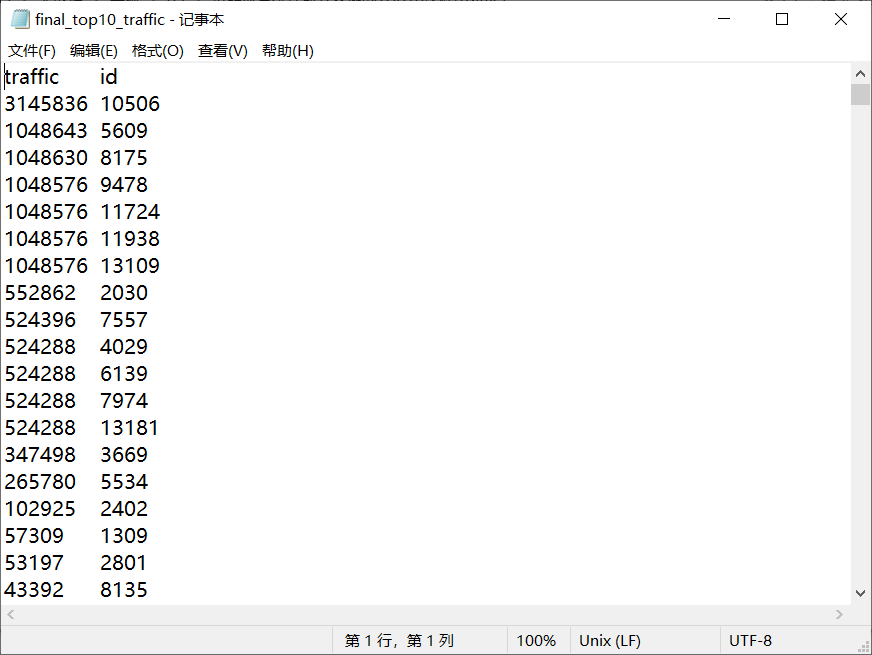
3、数据可视化:将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
2.2的统计结果:图形化展示暂未写出
2.1、2.3的统计结果:将统计结果的.txt导入到mysql数据库中,用EChart图形化进行可视化
-----------------------------------------------------------------------------------------------------------------------------
1、2题的代码:https://github.com/457352727/DSJ_tutorial01
3题的代码:https://github.com/457352727/DSJ_tutorial01_web
关于MapReduce的测试的更多相关文章
- mapreduce课堂测试结果
package mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.h ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- Hadoop系列(三):hadoop基本测试
下面是对hadoop的一些基本测试示例 Hadoop自带测试类简单使用 这个测试类名叫做 hadoop-mapreduce-client-jobclient.jar,位置在 hadoop/share/ ...
- 为集群配置Impala和Mapreduce
FROM: http://www.importnew.com/5881.html -- 扫描加关注,微信号: importnew -- 原文链接: Cloudera 翻译: ImportNew.com ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop 全分布模式 平台搭建
现将博客搬家至CSDN,博主改去CSDN玩玩~ 传送门:http://blog.csdn.net/sinat_28177969/article/details/54138163 Ps:主要答疑区在本帖 ...
- hadoop-ha QJM 架构部署
公司之前老的hadoop集群namenode有单点风险,最近学习此链接http://www.binospace.com/index.php /hdfs-ha-quorum-journal-manage ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- Ambari安装之部署单节点集群
前期博客 大数据领域两大最主流集群管理工具Ambari和Cloudera Manger Ambari架构原理 Ambari安装之Ambari安装前准备(CentOS6.5)(一) Ambari安装之部 ...
随机推荐
- 【原创】运维基础之Amplify
官方:https://www.nginx.com/products/nginx-amplify/ NGINX Amplify is a SaaS‑based monitoring tool for t ...
- 服务端相关知识学习(四)之Zookeeper启动过程
在上一篇,我们了解了zookeeper最基本的配置,也从中了解一些配置的作用,那么这篇文章中,我们将介绍Zookeeper的启动过程,我们在了解启动过程的时候还要回过头看看上一篇中各个配置参数在启动时 ...
- Ubuntu12.04+Caffe (+OpenCV+CPU-only)
经过一天的努力发现12.04 的pcre的库太低了, 要解决这个bug只能升级系统到16.04 麻蛋!!! 1. 下载大神MTCNN 源码,内含caffe https://github.co ...
- H5移动端弹幕动画实现
思路 把单个内容编辑好,计算自身宽度,确定初始位置 移动的距离是屏幕宽度 js动态的添加css动画函数,将高度.动画移动时间.动画延迟时间都用随机数控制 代码: html骨架结构 (以三个为例,如果觉 ...
- HttpClient的GET请求(post)请求
一.不带参数的GET请求 // 创建Httpclient对象 CloseableHttpClient httpclient = HttpClients.createDefault(); // 创建ht ...
- 操作MongoDB好用的图形化工具,Robomongo -> 下载 -> 安装
一 下载 点击下载 -> https://robomongo.org/download 二 安装 直接下一步就行了 -> 择安装位置之后 -> 确认安装
- JavaScript事件的基本学习
- 《python解释器源码剖析》第7章--python中的set对象
7.0 序 集合和字典一样,都是性能非常高效的数据结构,性能高效的原因就在于底层使用了哈希表.因此集合和字典的原理本质上是一样的,都是把值映射成索引,通过索引去查找. 7.1 PySetObject ...
- zencart更改css按钮的宽度css buttons
includes\functions\html_output.php 大概323行的zenCssButton函数 function zenCssButton($image = '', $text, $ ...
- Websocket @serverendpoint 404
今天写一个前后端交互的websocket , 本来写着挺顺利的,但测试的时候蒙了,前端websocket发的连接请求竟然连接不上 返回状态Status 报了个404 ,然后看后台onError方法也没 ...