Fiddler 网页采集抓包利器__手机app抓包
用curl技术开发了一个微信文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据接口加以显示;
基于weiphp做了一个掌上头条插件,也是用的网页采集技术;和一个创业团队一起在做一个高考志愿填报系统,所有的数据也是从别的地方抓取。
总而言之,网页抓取与网页采集技术是一项非常实用的技能,他能让我们高效快速的获取我们开发产品所需要的一些基本数据。
网页抓取与网页采集过程中难免需要用到抓包技术,所谓抓包,就是我们在访问一个目标网站的时候,需要分析我们提交给浏览器的一些http请求以及提交给浏览器的一些数据,在知道请求是如何发起的以及post了哪些数据之后,我们才能针对目标网页写出相应的采集程序。特别是在模拟登陆一些需要用户进行登陆验证的网站时,抓包分析就变得很重要。
一些浏览器自带抓包分析工具或者有其可扩展的抓包插件,像火狐浏览器有firebug插件,IE浏览器有HttpWatch。每个抓包工具都有其独特的功能,这里就不一一介绍了,今天给大家介绍一个好用的抓包工具Fiddler。
手机APP抓包
现在我们来结合一个具体的例子来讲一下如何抓包分析手机APP的请求数据,并达到自己的需求。我这里给大家讲一个LOL盒子的抓包实例。
我们知道,LOL盒子没有网页版,或者说网页版的功能并不像手机APP一样数据整合的那么齐全。如果我们要做一个微信版的LOL盒子,让用户在微信端回复一些关键词就能查看一些基本信息,比如用户在微信中回复“英雄”就能查看LOL全部的英雄信息,包括出装、符文之类的。那么我们想在微信端实现这些功能,肯定需要数据库的支持,如果我们的数据从LOL官网抓取的话,免不了要写很多匹配规则,所以一个简单高效的方法是直接抓取LOL盒子已经整合了的数据。那么正题开始,我们开始抓LOL盒子集成的全部英雄的数据。
1、首先在手机下载LOL盒子,并进入首页(请忽略我这个战五渣的战斗力指数)

2、打开Fiddler并点Remove all把抓包信息全部清除

3、在LOL盒子中点击英雄进入查看英雄页面
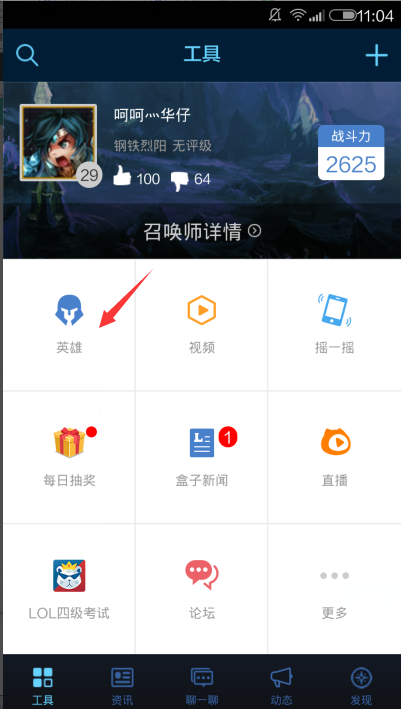
4、可以看到查看英雄页面有免费、我的英雄、全部三个选项

5、这时候我们可以看到Fiddler已经抓到我们需要的数据接口了

6、我们在其中一个数据接口上面点击右键,复制url地址并在浏览器中打开
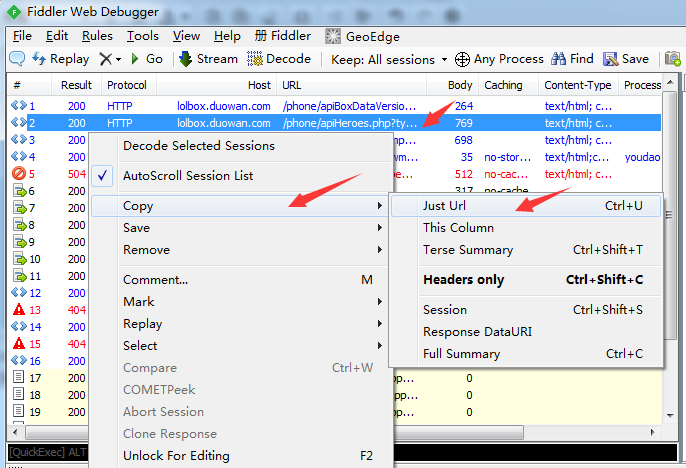
7、就能看到我们需要的周免英雄的数据接口了,是json格式的
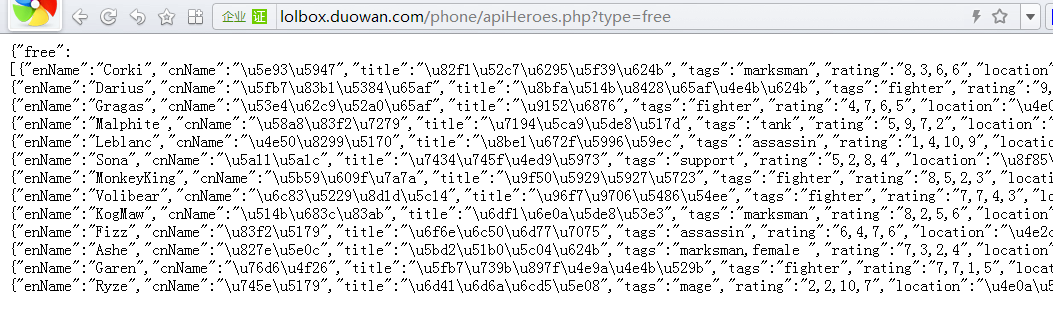
到此为止,抓包分析的整个流程大家一目了然了,得到了json接口之后,我们就能用curl技术把数据采集下来,并把json格式的数据转换成数组或者其他格式,然后就可以存到我们自己的数据库中了,当用户在微信中回复关键词时,我们就从数据库中取出相应的数据并回复给用户就行了。
Fiddler 网页采集抓包利器__手机app抓包的更多相关文章
- Fiddler 网页采集抓包利器
最近这段时间,网页采集方面的工作做得比较多.用curl技术开发了一个微信文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据接口加以显示:基于weiphp做了一个掌上 ...
- fiddler 抓取手机app请求包
今天心血来潮,也不知道怎么了,想着抓抓我们公司手机app的包看看,研究研究我们公司的接口,哎,我们api文档,我自己抓包看看吧.工具选择fiddler,理由免费,用着也舒服,手机设备 iPhone6 ...
- 使用Fiddler抓取手机APP数据包--360WIFI
使用Fiddler抓取手机APP流量--360WIFI 操作步骤:1.打开Fiddler,Tools-Fiddler Options-Connections,勾选Allow remote comput ...
- fiddler抓包+安卓机 完成手机app抓包的配置 遇到的一些问题
fiddler抓包+安卓模拟器完成手机app抓包的配置:fiddler抓包+雷电模拟器 完成手机app抓包的配置 其实在安卓真机上弄比在虚拟机上弄更麻烦一点,它们的步骤都差不多一样,就是在安卓真机上弄 ...
- 爬虫之手机APP抓包教程-亲测HTTP和HTTPS均可实现
当下很多网站都有做自己的APP端产品,一个优秀的爬虫工程师,必须能够绕过难爬取点而取捷径,这是皆大欢喜的.但是在网上收罗和查阅了无数文档和资料,本人亲测无数次,均不能正常获取HTTPS数据,究其原因是 ...
- scrapy之手机app抓包爬虫
手机App抓包爬虫 1. items.py class DouyuspiderItem(scrapy.Item): name = scrapy.Field()# 存储照片的名字 imagesUrls ...
- jmeter旅程第一站:Jmeter抓包浏览器或者抓取手机app的包
学习jmeter?从实际出发,我也是一个初学者,会优先考虑先用来做一些简单的抓包.接口测试,在实践的过程中学习jmeter用途.那么接下来,这篇文章我会以jmeter抓包开启我的jmeter旅程. 这 ...
- 网络爬虫中Fiddler抓取PC端网页数据包与手机端APP数据包
1 引言 在编写网络爬虫时,第一步(也是极为关键一步)就是对网络的请求(request)和回复(response)进行分析,寻找其中的规律,然后才能通过网络爬虫进行模拟.浏览器大多也自带有调试工具可以 ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
随机推荐
- .NET Core使用EF分页查询数据报错:OFFSET语法错误问题
在Asp.Net Core MVC项目中使用EF分页查询数据时遇到一个比较麻烦的问题,系统会报如下错误: 分页查询代码: ) * condition.PageSize).Take(condition. ...
- oracle 不能是用变量来作为列名和表名 ,但使用动态sql可以;
ORACLE 不能使用变量来作为列名 和表名 一下是个人的一些验证: DECLARE ename1 emp.ename%TYPE ; TYPE index_emp_type ) INDEX BY PL ...
- 虚拟机Centos设置静态IP
首先确保虚拟网卡(VMware Network Adapter VMnet8)是开启的,然后在windows的命令行里输入“ipconfig /all”,找到VMware Network Adapte ...
- web.py 中文模版报错
1. 作为模板的html文件,必须是utf-8编码; 2. html文件内容中的charset必须为utf-8,也就是必须包含 <meta http-equiv="Content-Ty ...
- nodejs之Buffer
Buffer是什么? 简单点理解,buff就是固定长度的uint8array.(es6已实现TypedArray). 由于是固定长度所以没有了splice,concat方法. 由于是固定类型所以没有了 ...
- Spring mvc 数据验证框架注解
@AssertFalse 被注解的元素必须为false@AssertTrue 被注解的元素必须为false@DecimalMax(value) 被注解的元素必须为一个数字,其值必须小于等于指定的最小值 ...
- 用PS做PNG格式底色是透明的logo
有时我们需要底色为透明色的logo图片,但是一般的图片底色都是白色的,覆盖在其它图片上会显示白色. 本文介绍如何用PS CS6制作透明底色的图片. 1.首先我们确定所选图片的大小(即分辨率大小),在资 ...
- 【poj2409】Let it Bead Polya定理
题目描述 用 $c$ 种颜色去染 $r$ 个点的环,如果两个环在旋转或翻转后是相同的,则称这两个环是同构的.求不同构的环的个数. $r·c\le 32$ . 题解 Polya定理 Burnside引理 ...
- 🔺 Garbage Remembering Exam UVA - 11637()
题目大意:给你N个单词,有两种方法随机排列,一种随机排成一行,另一种随机排成一圈,当两个单词之间的距离在两种排列中都严格小于K时,则这两个单词构成无效单词,问无效单词的期望. 解题思路:首先对于一排单 ...
- java学习1-环境搭建
1.材料准备 2.配置文档 3.验证java是否安装成功 打开cmd--> java -version 提示以下即成功