生存分析/Weibull Distribution韦布尔分布
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)

机器学习,统计项目合作请联系
QQ:231469242
测试脚本

测试数据

T is an array of durations, E is a either boolean or binary array representing whether the “death” was observed (alternatively an individual can be censored).
import lifelines
from lifelines.datasets import load_waltons df = load_waltons() # returns a Pandas DataFrame T = df['T']
E = df['E'] from lifelines import KaplanMeierFitter
kmf = KaplanMeierFitter()
kmf.fit(T, event_observed=E) # more succiently, kmf.fit(T,E) kmf.survival_function_
'''
Out[7]:
KM_estimate
timeline
0.0 1.000000
6.0 0.993865
7.0 0.987730
9.0 0.969210
13.0 0.950690
15.0 0.938344
17.0 0.932170
19.0 0.913650
22.0 0.888957
26.0 0.858090
29.0 0.827224
32.0 0.821051
33.0 0.802531
36.0 0.790184
38.0 0.777837
41.0 0.734624
43.0 0.728451
45.0 0.672891
47.0 0.666661
48.0 0.616817
51.0 0.598125 ''' kmf.median_
'''
Out[8]: 56.0
'''
kmf.plot()
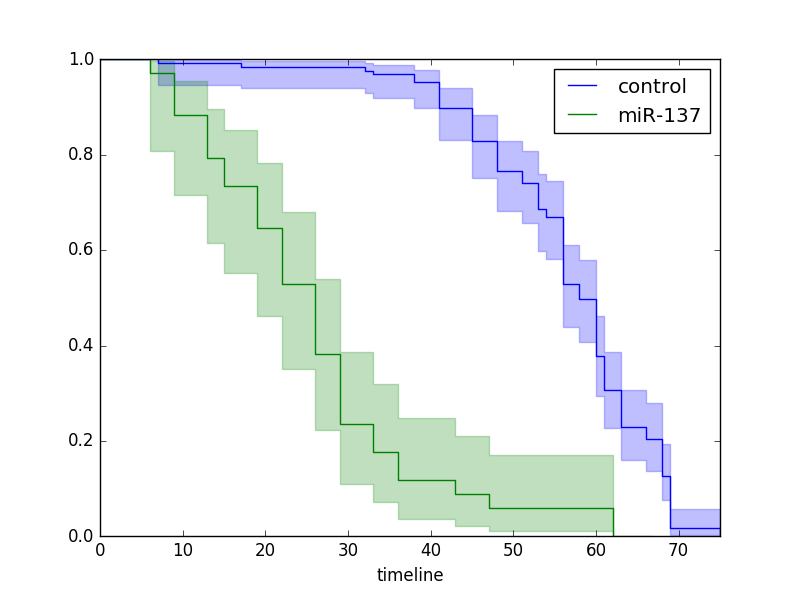
import lifelines
from lifelines.datasets import load_waltons
from lifelines import KaplanMeierFitter
df = load_waltons() # returns a Pandas DataFrame kmf = KaplanMeierFitter()
T = df['T']
E = df['E']
groups = df['group']
ix = (groups == 'miR-137') kmf.fit(T[~ix], E[~ix], label='control')
ax = kmf.plot() kmf.fit(T[ix], E[ix], label='miR-137')
kmf.plot(ax=ax)

import numpy as np
import matplotlib.pyplot as plt
from lifelines.plotting import plot_lifetimes
from numpy.random import uniform, exponential N = 25
current_time = 10
actual_lifetimes = np.array([[exponential(12), exponential(2)][uniform()<0.5] for i in range(N)])
observed_lifetimes = np.minimum(actual_lifetimes,current_time)
observed= actual_lifetimes < current_time plt.xlim(0,25)
plt.vlines(10,0,30,lw=2, linestyles="--")
plt.xlabel('time')
plt.title('Births and deaths of our population, at $t=10$')
plot_lifetimes(observed_lifetimes, event_observed=observed)
print "Observed lifetimes at time %d:\n"%(current_time), observed_lifetimes

import pandas as pd
import lifelines
from lifelines import KaplanMeierFitter
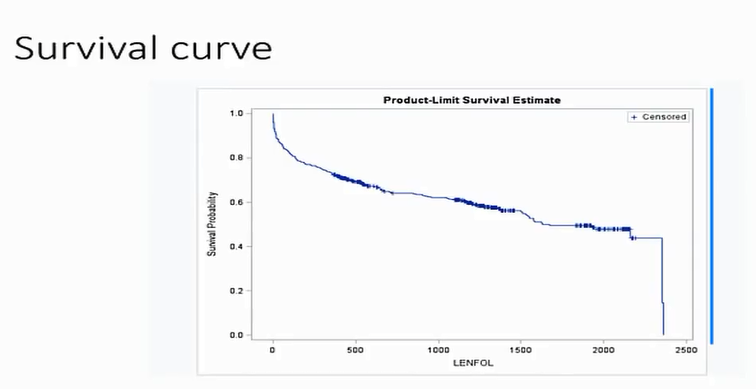
import matplotlib.pyplot as plt data = lifelines.datasets.load_dd()
kmf = KaplanMeierFitter() T = data["duration"]
C = data["observed"] kmf.fit(T, event_observed=C )
plt.title('Survival function of political regimes')
kmf.survival_function_.plot()
kmf.plot() kmf.median_

import pandas as pd
import lifelines
from lifelines import KaplanMeierFitter
import matplotlib.pyplot as plt data = lifelines.datasets.load_dd()
kmf = KaplanMeierFitter() T = data["duration"]
C = data["observed"] kmf.fit(T, event_observed=C )
plt.title('Survival function of political regimes')
kmf.survival_function_.plot()
kmf.plot() ax = plt.subplot(111) dem = (data["democracy"] == "Democracy")
kmf.fit(T[dem], event_observed=C[dem], label="Democratic Regimes")
kmf.plot(ax=ax, ci_force_lines=True)
kmf.fit(T[~dem], event_observed=C[~dem], label="Non-democratic Regimes") plt.ylim(0,1);
plt.title("Lifespans of different global regimes")
kmf.plot(ax=ax, ci_force_lines=True)
应用于保险业,病人治疗,信用卡诈骗
信用卡拖欠


具体文档
http://lifelines.readthedocs.io/en/latest/
https://wenku.baidu.com/view/577041d3a1c7aa00b52acb2e.html?from=search
https://wenku.baidu.com/view/a5adff8b89eb172ded63b7d6.html?from=search


https://github.com/thomas-haslwanter/statsintro_python/tree/master/ISP/Code_Quantlets/10_SurvivalAnalysis/lifelinesDemo

测试代码
# -*- coding: utf-8 -*-
# Import standard packages
import numpy as np
import matplotlib.pyplot as plt
from numpy.random import uniform, exponential
import os # additional packages
from lifelines.plotting import plot_lifetimes
import sys
sys.path.append(os.path.join('..', '..', 'Utilities')) try:
# Import formatting commands if directory "Utilities" is available
from ISP_mystyle import setFonts except ImportError:
# Ensure correct performance otherwise
def setFonts(*options):
return # Generate some dummy data
np.set_printoptions(precision=2)
N = 20
study_duration = 12 # Note: a constant dropout rate is equivalent to an exponential distribution!
actual_subscriptiontimes = np.array([[exponential(18), exponential(3)][uniform()<0.5] for i in range(N)])
observed_subscriptiontimes = np.minimum(actual_subscriptiontimes,study_duration)
observed= actual_subscriptiontimes < study_duration # Show the data
setFonts(18)
plt.xlim(0,24)
plt.vlines(12, 0, 30, lw=2, linestyles="--")
plt.xlabel('time')
plt.title('Subscription Times, at $t=12$ months')
plot_lifetimes(observed_subscriptiontimes, event_observed=observed) print("Observed subscription time at time %d:\n"%(study_duration), observed_subscriptiontimes)








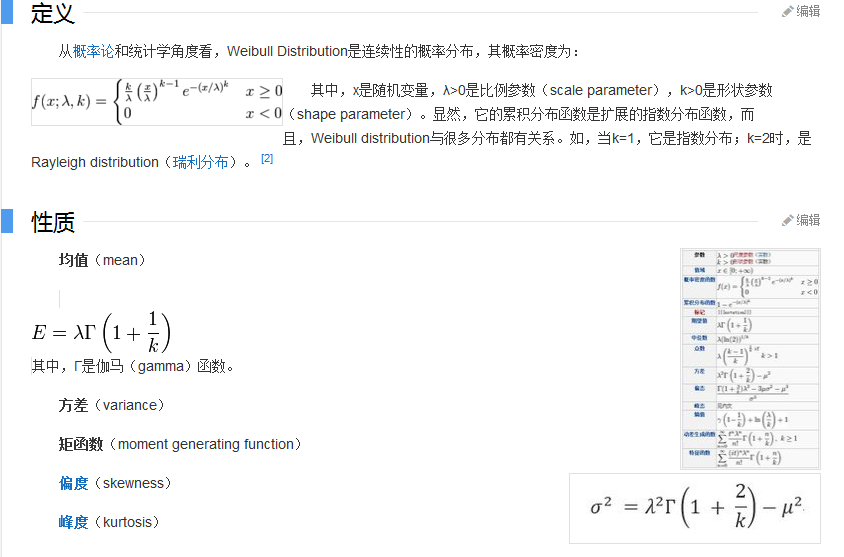
where k > 0 is the shape parameter and > 0 is the scale parameter of the
distribution. (It is one of the rare cases where we use a shape parameter different
from skewness and kurtosis.) Its complementary cumulative distribution function is
a stretched exponential function.
If the quantity x is a “time-to-failure,” theWeibull distribution gives a distribution
for which the failure rate is proportional to a power of time. The shape parameter, k,
is that power plus one, and so this parameter can be interpreted directly as follows:
• Avalueofk < 1 indicates that the failure rate decreases over time. This happens
if there is significant “infant mortality,” or defective items failing early and the
failure rate decreasing over time as the defective items are weeded out of the
population.
• Avalueofk D 1 indicates that the failure rate is constant over time. This might
suggest random external events are causing mortality, or failure.
• Avalueofk > 1 indicates that the failure rate increases with time. This happens
if there is an “aging” process, or parts that are more likely to fail as time goes on.
An example would be products with a built-in weakness that fail soon after the
warranty expires.
In the field of materials science, the shape parameter k of a distribution of
strengths is known as the Weibull modulus.
瑞典工程师威布尔从30年代开始研究轴承寿命,以后又研究结构强度和疲劳等问题。他采用了“链式”模型来解释结构强度和寿命问题。这个模型假设一个结构
是由若干小元件(设为n个)串联而成,于是可以形象地将结构看成是由n个环构成的一条链条,其强度(或寿命)取决于最薄弱环的强度(或寿命)。单个链的强
度(或寿命)为一随机变量,设各环强度(或寿命)相互独立,分布相同,则求链强度(或寿命)的概率分布就变成求极小值分布问题,由此给出威布尔分布函数。
由于零件或结构的疲劳强度(或寿命)也应取决于其最弱环的强度(或寿命),也应能用威布尔分布描述。
根据1943年苏联格涅坚科的研究结果,不管随机变量的原始分布如何,它的极小值的渐近分布只能有三种,而威布尔分布就是第Ⅲ种极小值分布。
由于威布尔分布是根据最弱环节模型或串联模型得到的,能充分反映材料缺陷和应力集中源对材料疲劳寿命的影响,而且具有递增的失效率,所以,将它作为材料或零件的寿命分布模型或给定寿命下的疲劳强度模型是合适的。
威布尔分布有多种形式,包括一参数威布尔分布、二参数威布尔分布、三参数威布尔分布或混合威布尔分布。三参数的威布尔分布由形状、尺度(范围)和位置三
个参数决定。其中形状参数是最重要的参数,决定分布密度曲线的基本形状,尺度参数起放大或缩小曲线的作用,但不影响分布的形状。通过改变形状参数可以表示
不同阶段的失效情况;也可以作为许多其他分布的近似,如,可将形状参数设为合适的值以近似正态、对数正态、指数等分布。
劳试验,三参数的威布尔分布用于低应力水平的材料及某些零件的寿命试验,一般而言,它具有比对数正态分布更大的适用性。但是,威布尔分布参数的分析法估计
较复杂,区间估计值过长,实践中常采用概率纸估计法,从而降低了参数的估计精度.这是威布尔分布目前存在的主要缺点,也限制了它的应用[1]
历史
应用





































https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章)

生存分析/Weibull Distribution韦布尔分布的更多相关文章
- R生存分析AFT
γ = 1/scale =1/0.902 α = exp(−(Intercept)γ)=exp(-(7.111)*γ) > library(survival) > myfit=survre ...
- 生存分析(survival analysis)
一.生存分析(survival analysis)的定义 生存分析:对一个或多个非负随机变量进行统计推断,研究生存现象和响应时间数据及其统计规律的一门学科. 生存分析:既考虑结果又考虑生存时间的一种统 ...
- SPSS数据分析—生存分析
生存分析是对生存时间进行统计分析的一种技术,所谓生存时间,就是指从某一时间点起到所关心的事件发生的这段时间.这里的时间不一定就是钟表日历上的时间,也有可能是其他的度量单位,比如长度单位等. 生存时间有 ...
- survival analysis 生存分析与R 语言示例 入门篇
原创博客,未经允许,不得转载. 生存分析,survival analysis,顾名思义是用来研究个体的存活概率与时间的关系.例如研究病人感染了病毒后,多长时间会死亡:工作的机器多长时间会发生崩溃等. ...
- Cox回归模型【生存分析】
参考:<复杂数据统计方法--基于R的应用> 吴喜之 在生存分析中,研究的主要对象是寿命超过某一时间的概率.还可以描述其他一些事情发生的概率,例如产品的失效.出狱犯人第一次犯罪.失业人员第一 ...
- 生存分析与R--转载
生存分析与R 生存分析是将事件的结果和出现这一结果所经历的时间结合起来分析的一类统计分析方法.不仅考虑事件是否出现,而且还考虑事件出现的时间长短,因此这类方法也被称为事件时间分析(time-to-ev ...
- R语言学习 - 非参数法生存分析--转载
生存分析指根据试验或调查得到的数据对生物或人的生存时间进行分析和推断,研究生存时间和结局与众多影响因素间关系及其程度大小的方法,也称生存率分析或存活率分析.常用于肿瘤等疾病的标志物筛选.疗效及预后的考 ...
- Spark2 生存分析Survival regression
在spark.ml中,实现了加速失效时间(AFT)模型,这是一个用于检查数据的参数生存回归模型. 它描述了生存时间对数的模型,因此它通常被称为生存分析的对数线性模型. 不同于为相同目的设计的比例风险模 ...
- 生存分析与R
生存分析与R 2018年05月19日 19:55:06 走在码农路上的医学狗 阅读数:4399更多 个人分类: R语言 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
随机推荐
- How to pass an Amazon account review
Have you ever sold products on Amazon? How about sold so much within the first week that amazon deci ...
- eBay报告:德国或将成为外贸电商热门市场
[亿邦动力网讯]1月3日消息,日前,跨境电商平台eBay发布公告称,自2014年1月中旬起,卖家在eBay德国 ( eBay.de ).eBay 奥地利 ( eBay.at ) 或eBay瑞士 ( e ...
- 2018-2019-20172321 《Java软件结构与数据结构》第四周学习总结
2018-2019-20172321 <Java软件结构与数据结构>第四周学习总结 教材学习内容总结 第六章 6.1列表集合 列表集合是一种概念性表示法,其思想是使事物以线性列表的方式进行 ...
- OpenCV学习笔记——图像平滑处理
1.blur 归一化滤波器Blurs an image using the normalized box filter.C++: void blur(InputArray src, OutputArr ...
- 在html中怎么格式化输出json字符串
#今天的项目用到,看俊哥找到,特此记录下来 步骤: 1.在html页面中输入下面的标签,必须是在pre标签内输出格式才会生效: <pre id="songReqJson"&g ...
- 阅读笔记《我是一只IT小小鸟》
我是一只IT小小鸟 我们在尝试新的事物的时候,总是会遇到各种各样的困难,不同的人会在碰壁不同的次数之后退出.用程序员喜欢的话来说就是,我们都在for循环,区别在于你是什么情况下break;的.有的人退 ...
- OC创建对象并访问成员变量
1.创建一个对象 Car *car =[Car new] 只要用new操作符定义的实体,就会在堆内存中开辟一个新空间 [Car new]在内存中 干了三件事 1)在堆中开辟一段存储空间 2)初始化成员 ...
- Scrum团队成立及《构建之法》第六、七章读后感
5.Scrum团队成立 5.1 团队名称:喳喳 团队目标:突破渣渣 团队口号:吱吱喳喳 团队照: 5.2 角色分配 产品负责人: 112冯婉莹 Scrum Master: ...
- DELL服务器PXE前期处理
thaks:https://www.cnblogs.com/520ZXL/ PXE批量推系统,服务器要具备条件:raid处理好,设置为pxe启动,与PXE服务器网络要通 先进入磁盘阵列(ctrl+R) ...
- 个人项目----词频统计WEB(部分功能)
需求分析 1.使用web上传txt文件,对上传的txt进行词频统计. 2.将统计后的结果输出到web页面,力求界面优美. 3.在界面上展示所给url的文章词频统计,力求界面优美. 3.将每个单词同四. ...