《attention is all you need》解读
Motivation:
- 靠attention机制,不使用rnn和cnn,并行度高
- 通过attention,抓长距离依赖关系比rnn强
创新点:
- 通过self-attention,自己和自己做attention,使得每个词都有全局的语义信息(长依赖
- 由于 Self-Attention 是每个词和所有词都要计算 Attention,所以不管他们中间有多长距离,最大的路径长度也都只是 1。可以捕获长距离依赖关系
- 提出multi-head attention,可以看成attention的ensemble版本,不同head学习不同的子空间语义。
attention表示成k、q、v的方式:
传统的attention(sequence2sequence问题):
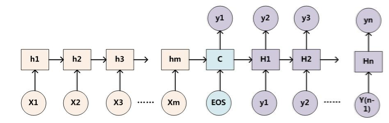
上下文context表示成如下的方式(h的加权平均):
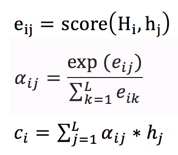
那么权重alpha(attention weight)可表示成Q和K的乘积,小h即V(下图中很清楚的看出,Q是大H,K和V是小h):
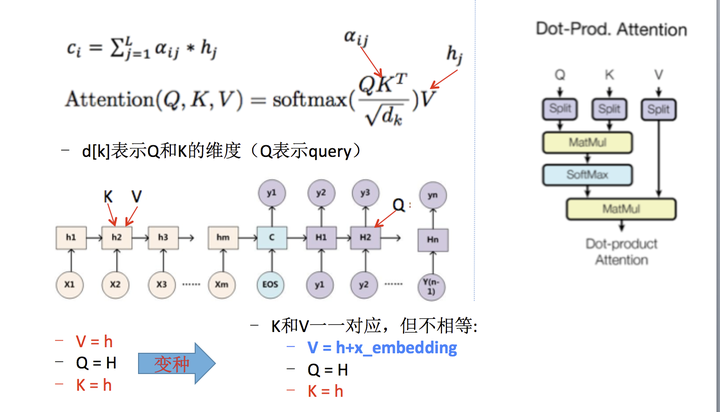
上述可以做个变种,就是K和V不相等,但需要一一对应,例如:
- V=h+x_embedding
- Q = H
- k=h
乘法VS加法attention
加法注意力:
还是以传统的RNN的seq2seq问题为例子,加性注意力是最经典的注意力机制,它使用了有一个隐藏层的前馈网络(全连接)来计算注意力分配:

乘法注意力:
就是常见的用乘法来计算attention score:
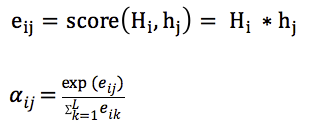
乘法注意力不用使用一个全连接层,所以空间复杂度占优;另外由于乘法可以使用优化的矩阵乘法运算,所以计算上也一般占优。
论文中的乘法注意力除了一个scale factor:
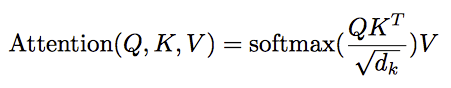
论文中指出当dk比较小的时候,乘法注意力和加法注意力效果差不多;但当d_k比较大的时候,如果不使用scale factor,则加法注意力要好一些,因为乘法结果会比较大,容易进入softmax函数的“饱和区”,梯度较小。
self-attention
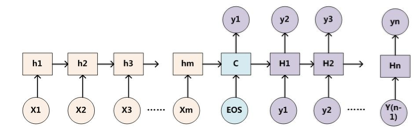
以一般的RNN的S2S为例子,一般的attention的Q来自Decoder(如下图中的大H),K和V来自Encoder(如下图中的小h)。self-attention就是attention的K、Q、V都来自encoder或者decoder,使得每个位置的表示都具有全局的语义信息,有利于建立长依赖关系。

Layer normalization(LN)
batch normalization是对一个每一个节点,针对一个batch,做一次normalization,即纵向的normalization:

layer normalization(LN),是对一个样本,同一个层网络的所有神经元做normalization,不涉及到batch的概念,即横向normalization:

BN适用于不同mini batch数据分布差异不大的情况,而且BN需要开辟变量存每个节点的均值和方差,空间消耗略大;而且 BN适用于有mini_batch的场景。
LN只需要一个样本就可以做normalization,可以避免 BN 中受 mini-batch 数据分布影响的问题,也不需要开辟空间存每个节点的均值和方差。
但是,BN 的转换是针对单个神经元可训练的——不同神经元的输入经过再平移和再缩放后分布在不同的区间,而 LN 对于一整层的神经元训练得到同一个转换——所有的输入都在同一个区间范围内。如果不同输入特征不属于相似的类别(比如颜色和大小,scale不一样),那么 LN 的处理可能会降低模型的表达能力。
encoder:
- 输入:和conv s2s类似,词向量加上了positional embedding,即给位置1,2,3,4...n等编码(也用一个embedding表示)。然后在编码的时候可以使用正弦和余弦函数,使得位置编码具有周期性,并且有很好的表示相对位置的关系的特性(对于任意的偏移量k,PE[pos+k]可以由PE[pos]表示):

- 输入的序列长度是n,embedding维度是d,所以输入是n*d的矩阵
- N=6,6个重复一样的结构,由两个子层组成:
- 子层1:
- Multi-head self-attention
- 残余连接和LN:
- Output = LN (x+sublayer(x))
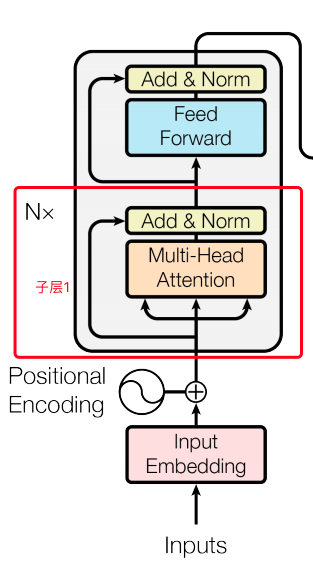
- 子层2:
- Position-wise fc层(跟卷积很像)
- 对n*d的矩阵的每一行进行操作(相当于把矩阵每一行铺平,接一个FC),同一层的不同行FC层用一样的参数,不同层用不同的参数(对于全连接的节点数目,先从512变大为2048,再缩小为512),这里的max表示使用relu激活函数:
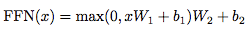
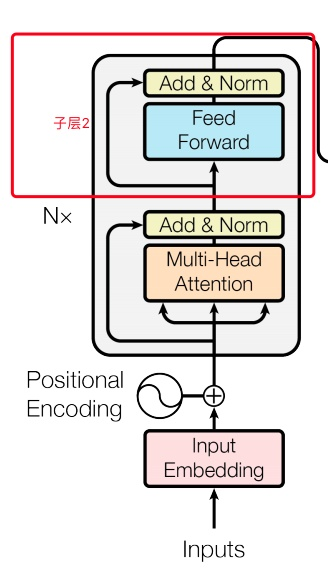
- 整个encoder的输出也是n*d的矩阵

decoder:
•输入:假设已经翻译出k个词,向量维度还是d
•同样使用N=6个重复的层,依然使用残余连接和LN
•3个子层,比encoder多一个attention层,是Decoder端去attend encoder端的信息的层:
- Sub-L1:
self-attention,同encoder,但要Mask掉未来的信息,得到k*d的矩阵
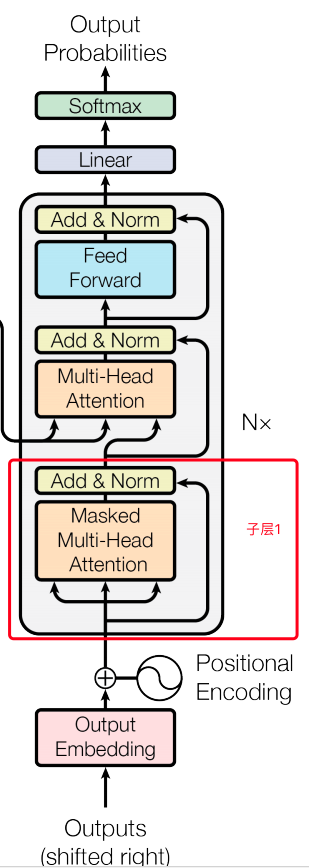
- Sub-L2:和encoder做attention的层,输出k*d的矩阵
- Sub-L3:全连接层,输出k*d的矩阵,用第k行去预测输出y
mutli-head attention:
MultiHead可以看成是一种ensemble方式,获取不同子空间的语义:

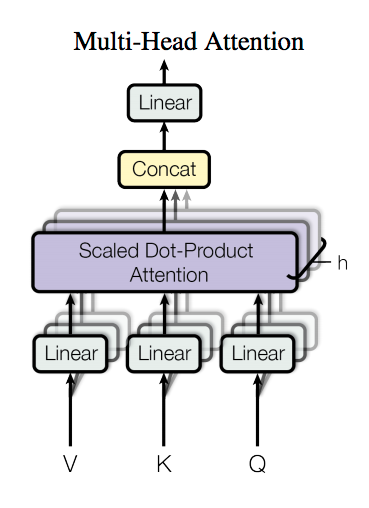
获取每个子任务的Q、K、V:
- 通过全连接进行线性变换映射成多个Q、K、V,线性映射得到的结果维度可以不变、也可以减少(类似降维)
- 或者通过Split对Q、K、V进行划分(分段)
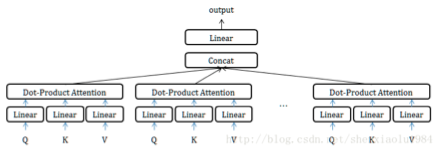
如果采用线性映射的方式,使得维度降低;或者通过split的方式使得维度降低,那么多个head做attention合并起来的复杂度和原来一个head做attention的复杂度不会差多少,而且多个head之间做attention可以并行。
总结
本文提出用attention做翻译,不用RNN和CNN,attention计算快,并行度高,而且任何两个词的距离都是1,抓长距离依赖擅长。但是如果要堆那么多层的话,其实也不见得快到哪里去。
另外,说一些我的经验,不一定放诸四海皆准,仅供参考(我是在语义匹配里的任务的经验,不是翻译):
- positional encoding一般可以加快收敛,但是对提升效果一般作用微小
- multi-head attention在emb较小时,例如128,一般无效果。但是像原文中的512就可能有用。但是对工业界的系统,emb开不到512,内存没那么大。
- attention和gru一起用,效果会有提升,在匹配任务里,attention替换不了gru,但是attention计算快。
参考文献:
https://arxiv.org/abs/1706.03762
https://arxiv.org/pdf/1711.02132.pdf
详解深度学习中的 Normalization,不只是BN(2)

《attention is all you need》解读的更多相关文章
- 解读<!doctype html>
回归简单的doctype声明:http://blog.csdn.net/wangxiaoqin11/article/details/42032037 为何说 HTML5「no longer based ...
- 前端(一)之 HTML
前端之 HTML 前言 python 基础.网络编程.并发编程与数据库要开始告一段落了,从现在开始进入前端的学习.前端的东西多且杂,需要好好地练习. 什么是前端 前端即网站前台部分,运行在 PC 端, ...
- html概念
一.前端 1.什么是前端 前端即网站前台部分,运行在PC端等浏览器上展现给用户浏览的网页.随着互联网技术的发展, HTML5,CSS3,前端框架的应用,跨平台响应式网页设计能够适应各种屏幕分辨率,完美 ...
- 前端html/css/script基础
1. 基础模板 <!DOCTYPE html> <html> <head> <meta charert="utf-8" /> < ...
- front-end——HTML5/CSS3基础
概述 1.什么是前端 前端即网站前台部分,运行在PC端,移动端等浏览器上展现给用户浏览的网页,随着互联网技术的发展,html5,css3,前端框架的应用,跨平台响应式网页设计能够适应各种屏幕分辨率,完 ...
- position:absolute绝对定位解读
position:absolute绝对定位解读 摘要 用四段代码解释absolute的定位问题,进而从概念的角度切实解决html布局问题. 一.背景 常常遇到这样一些问题,很容易混淆.“浏览器屏 ...
- JSP九大内置对象和四种属性范围解读
林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 摘要:本文首先主要解说了JSP中四种属性范围的概念.用法与实例. 然后在这个基础之上又引入了九 ...
- Jsoup代码解读之四-parser
Jsoup代码解读之四-parser 作为Java世界最好的HTML 解析库,Jsoup的parser实现非常具有代表性.这部分也是Jsoup最复杂的部分,需要一些数据结构.状态机乃至编译器的知识.好 ...
- CSS之float属性解读
在web标准的网页中,页面各个元素都是以标准流的方式来进行布局的.即块元素占满指定的宽度,不指定宽度则占满整行(如<p>.<div>元素),内联元素则是在行内一个接一个的从左到 ...
- Shrio登陆验证实例详细解读(转)
摘要:本文采用了Spring+SpringMVC+Mybatis+Shiro+Msql来写了一个登陆验证的实例,下面来看看过程吧!整个工程基于Mavevn来创建,运行环境为JDK1.6+WIN7+to ...
随机推荐
- div代码大全 DIV代码使用说明
一.DIV代码语法 - TOP DIV代码是放入小于与大于符号内,即“<div>”. DIV是一对闭合标签,即“”开始,“结束”的盒子标签. 语法结构: <div>我是内容&l ...
- GIT → 05:Git命令行操作
5.1 打开命令行窗口 安装Git后,在资源管理器的空白处,单击鼠标右键打开窗口,点击 Git Bash Here ,打开Git命令行窗口,在窗口中可直接使用Linux命令操作: 5.2 初始化Git ...
- day 53
目录 orm表关系如何建立 django中间件 路由层 反向解析 路由分发 名称空间 伪静态 虚拟环境 django版本的区别 视图层 orm表关系如何建立 多对多 一对多 一对一 换 ...
- 2019.8.10 NOIP模拟测试16 反思总结【基本更新完毕忽视咕咕咕】
一如既往先放代码,我还没开始改… 改完T1滚过来了,先把T1T2的题解写了[颓博客啊] 今天下午就要走了,没想到还有送行的饯别礼,真是欣喜万分[并没有] 早上刚码完前面的总结,带着不怎么有希望的心情开 ...
- Angungular.js 的过滤器&工具方法
字母大小写 数字 货币 截取字符串 截取数组 用JS操作 ----------------------------------------------------------------------- ...
- linux设置变量的三种方法
1在/etc/profile文件中添加变量对所有用户生效(永久的) 用VI在文件/etc/profile文件中增加变量,该变量将会对Linux下所有用户有效,并且是“永久生效”. 例如:编辑/etc/ ...
- XtraBackup构建MySQL主从环境的方法
环境:HE3主库,HE1从库HE1:192.168.1.248HE3:192.168.1.250从库my.cnf加入以下参数并重启数据库:read_only=1log_slave_updates=1( ...
- 上传同步github
…or create a new repository on the command line echo "# testproject" >> README.md ...
- 30分钟学webpack实战
阅读目录 一:什么是webpack? 他有什么优点? 二:如何安装和配置 三:理解webpack加载器 四:理解less-loader加载器的使用 五:理解babel-loader加载器的含义 六:了 ...
- Etag 和 If-None-Match
ETag是HTTP1.1中才加入的一个属性,用来帮助服务器控制Web端的缓存验证. 它的原理是这样的,当浏览器请求服务器的某项资源(A)时, 服务器根据A算出一个哈希值(3f ...