pandas时间序列常用操作
一、时间序列是什么
时间序列在多个时间点观察或测量到的任何事物,很多都是固定频率出现 的,比如每15秒、每5分钟、每月。
padnas提供了一组标准的时间序列处理工具和数据算法,基本的时间序列类型是以时间戳为索引的Series。
当创建一个带有DatetimeIndex的Series时,pandas就会知道对象是一个时间序列,用Numpy的datetime64数据以纳秒形式存储时间。
dates=[
datetime(2020,1,2),datetime(2020,1,5),datetime(2020,1,7),
datetime(2020,1,8),datetime(2020,1,10),datetime(2020,1,12)
]
ts=pd.Series(np.random.randn(6),index=dates)
ts
2020-01-02 -0.140776
2020-01-05 0.185088
2020-01-07 0.555777
2020-01-08 0.693348
2020-01-10 -0.213715
2020-01-12 -0.259721
dtype: float64
ts.index
DatetimeIndex(['2020-01-02', '2020-01-05', '2020-01-07', '2020-01-08',
'2020-01-10', '2020-01-12'],
dtype='datetime64[ns]', freq=None)
ts.index.dtype
dtype('<M8[ns]')
二、时间序列的选取-时间字符串/at_time/between_time/asof
1.传入一个可以被解释为日期的字符串
ts['1/10/2020']
-0.3216128833894315
ts['2020-01-02']
0.47508960825683716
#也可以只传入年或月
longer_ts['2021']
2021-01-01 1.596179
2021-01-02 -0.458160
2021-01-03 1.380482
...
2021-12-29 0.343524
2021-12-30 0.040584
2021-12-31 -1.616620
Freq: D, Length: 365, dtype: float64
#通过日期进行切片
ts[datetime(2020,1,7):]
2020-01-07 0.555777
2020-01-08 0.693348
2020-01-10 -0.213715
2020-01-12 -0.259721
dtype: float64
ts['1/6/2020':'1/11/2020']
2020-01-07 0.555777
2020-01-08 0.693348
2020-01-10 -0.213715
dtype: float64
2.通过at_time获取指定时间点
# 生成一个交易日内的日期范围和时间序列,以分为纬度
rng=pd.date_range('2020-06-01 09:30','2020-06-01 15:59',freq='T')
#生成5天的时间点
rng=rng.append([rng+pd.offsets.BDay(i) for i in range(1,4)])
ts=pd.Series(np.arange(len(rng),dtype=float),index=rng)
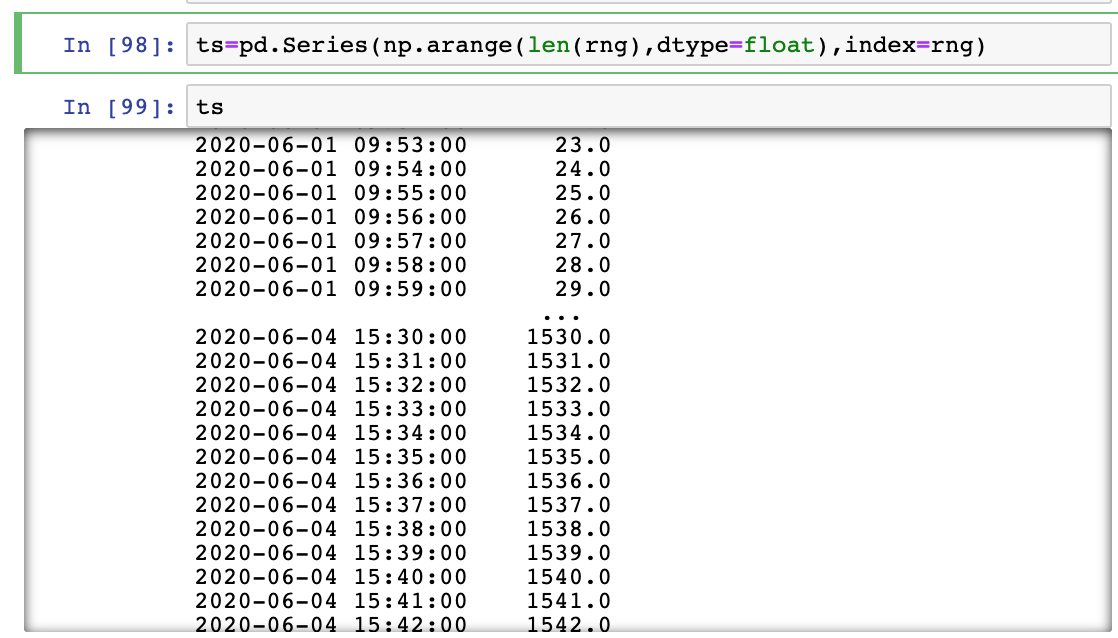
#抽取指定时间点:10点0分的数据
ts.at_time(time(10,0))

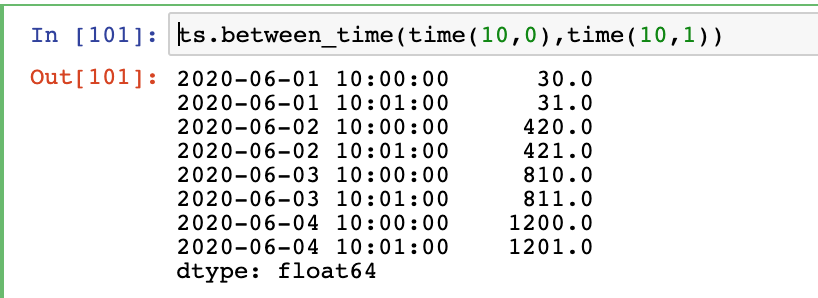
3.通过between_time获取两个时间点之间的数据
ts.between_time(time(10,0),time(10,1))
4.通过asof获取最接近当前时间的数据
asof解释:最后一行不是NaN值的值。通俗的说:假如我有一组数据,某个点的时候这个值是NaN,那就求这个值之前最近一个不是NaN的值是多少
selection=pd.date_range('2020-06-01 10:00',periods=4,freq='B')
ts.asof(selection)
三、时间序列的生成-datetime/date_range(start,end,perios,freq)
1.直接使用date_time生成
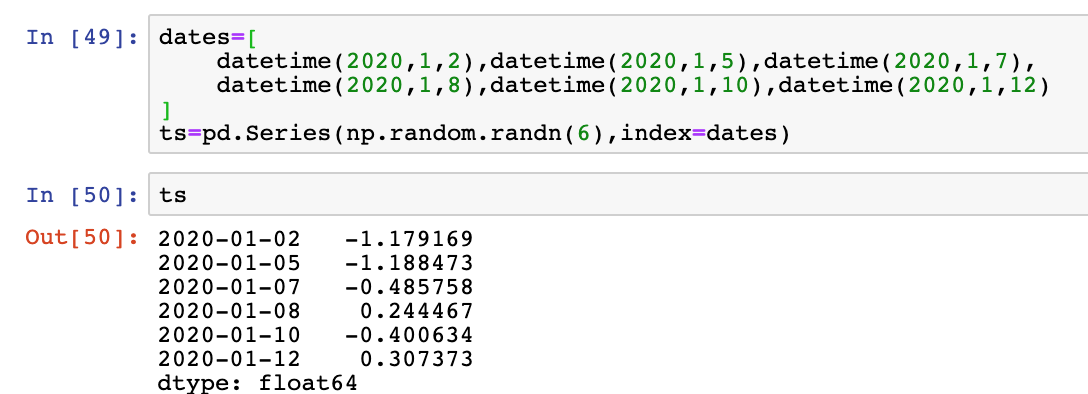
dates=[
datetime(2020,1,2),datetime(2020,1,5),datetime(2020,1,7),
datetime(2020,1,8),datetime(2020,1,10),datetime(2020,1,12)
]
ts=pd.Series(np.random.randn(6),index=dates)
date_range可以生成指定长度的DatetimeIndex
- 指定开始和结束
pd.date_range('4/1/2020','6/1/2020')
DatetimeIndex(['2020-04-01', '2020-04-02', '2020-04-03', '2020-04-04',
'2020-04-05', '2020-04-06', '2020-04-07', '2020-04-08',
'2020-04-09', '2020-04-10', '2020-04-11', '2020-04-12',
'2020-04-13', '2020-04-14', '2020-04-15', '2020-04-16',
'2020-04-17', '2020-04-18', '2020-04-19', '2020-04-20',
'2020-04-21', '2020-04-22', '2020-04-23', '2020-04-24',
'2020-04-25', '2020-04-26', '2020-04-27', '2020-04-28',
'2020-04-29', '2020-04-30', '2020-05-01', '2020-05-02',
'2020-05-03', '2020-05-04', '2020-05-05', '2020-05-06',
'2020-05-07', '2020-05-08', '2020-05-09', '2020-05-10',
'2020-05-11', '2020-05-12', '2020-05-13', '2020-05-14',
'2020-05-15', '2020-05-16', '2020-05-17', '2020-05-18',
'2020-05-19', '2020-05-20', '2020-05-21', '2020-05-22',
'2020-05-23', '2020-05-24', '2020-05-25', '2020-05-26',
'2020-05-27', '2020-05-28', '2020-05-29', '2020-05-30',
'2020-05-31', '2020-06-01'],
dtype='datetime64[ns]', freq='D')
- 指定步长
pd.date_range(start='4/1/2020',periods=20)
DatetimeIndex(['2020-04-01', '2020-04-02', '2020-04-03', '2020-04-04',
'2020-04-05', '2020-04-06', '2020-04-07', '2020-04-08',
'2020-04-09', '2020-04-10', '2020-04-11', '2020-04-12',
'2020-04-13', '2020-04-14', '2020-04-15', '2020-04-16',
'2020-04-17', '2020-04-18', '2020-04-19', '2020-04-20'],
dtype='datetime64[ns]', freq='D')
- 指定偏移量
M:日历月末最后一天
pd.date_range('1/1/2020','12/1/2020',freq='M')
DatetimeIndex(['2020-01-31', '2020-02-29', '2020-03-31', '2020-04-30',
'2020-05-31', '2020-06-30', '2020-07-31', '2020-08-31',
'2020-09-30', '2020-10-31', '2020-11-30'],
dtype='datetime64[ns]', freq='M')
BM:每月的最后个工作日,business end of month
pd.date_range('1/1/2020','12/1/2020',freq='BM')
DatetimeIndex(['2020-01-31', '2020-02-28', '2020-03-31', '2020-04-30',
'2020-05-29', '2020-06-30', '2020-07-31', '2020-08-31',
'2020-09-30', '2020-10-30', '2020-11-30'],
dtype='datetime64[ns]', freq='BM')
自定义时间偏移,如h、4h、1h30min
pd.date_range('1/1/2020',periods=10,freq='1h30min')
DatetimeIndex(['2020-01-01 00:00:00', '2020-01-01 01:30:00',
'2020-01-01 03:00:00', '2020-01-01 04:30:00',
'2020-01-01 06:00:00', '2020-01-01 07:30:00',
'2020-01-01 09:00:00', '2020-01-01 10:30:00',
'2020-01-01 12:00:00', '2020-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
四、时间序列的偏移量对照表-freq
| 名称 | 偏移量类型 | 说明 |
|---|---|---|
| D | Day | 每日 |
| B | BusinessDay | 每工作日 |
| H | Hour | 每小时 |
| T或min | Minute | 每分 |
| S | Second | 每秒 |
| L或ms | Milli | 每毫秒 |
| U | Micro | 每微秒 |
| M | MounthEnd | 每月最后一个日历日 |
| BM | BusinessMonthEnd | 每月最后一个工作日 |
| MS | MonthBegin | 每月每一个工作日 |
| BMS | BusinessMonthBegin | 每月第一个工作日 |
| W-MON、W-TUE... | Week | 指定星期几(MON、TUE、WED、THU、FRI、SAT、SUM) |
| WOM-1MON、WMON-2MON | WeekOfMonth | 产生每月第一、第二、第三或第四周的星期几 |
| Q-JAN、Q-FEB... | QuaterEnd | 对于以指定月份(JAN、FEB、MAR、APR、MAY、JUN、JUL、AUG、SEP、OCT、NOV、DEC)结束的年度,每季度最后一月的最后一个日历日 |
| BQ-JAN、BQ-FEB... | BusinessQuaterEnd | 对于以指定月份结束的年度,每季度最后一月的最后一个工作日 |
| QS-JAN、QS-FEB... | QuaterBegin | 对于以指定月份结束的年度,每季度最后一月的第一个日历日 |
| QS-JAN、QS-FEB... | BusinessQuaterBegin | 对于指定月份结束的年度,每季度最后一月的第一个工作日 |
| A-JAN、A-FEB... | YearEnd | 每年指定月份的最后一个日历日 |
| BA-JAN、BA-FEB | BusinessYearEnd | 每年指定月份的最后一个日历日 |
| AS-JAN、AS-FEB | YearBegin | 每年指定月份的第一个日历日 |
| BAS-JAN、BAS-FEB | BusinessYearBegin | 每年指定月份的第一个工作日 |
例如,每月第3个星期五
pd.date_range('1/1/2020','9/1/2020',freq='WOM-3FRI')
DatetimeIndex(['2020-01-17', '2020-02-21', '2020-03-20', '2020-04-17',
'2020-05-15', '2020-06-19', '2020-07-17', '2020-08-21'],
dtype='datetime64[ns]', freq='WOM-3FRI')
五、时间序列的前移或后移-shift/通过Day或MonthEnd
shift方法用于执行单纯的前移或后移操作
ts=pd.Series(np.random.randn(4),
index=pd.date_range('1/1/2020',periods=4,freq='M'))
ts
2020-01-31 0.185458
2020-02-29 0.549704
2020-03-31 0.146584
2020-04-30 0.983613
Freq: M, dtype: float64
向后移动一个月
ts.shift(1,freq='M')
2020-02-29 0.185458
2020-03-31 0.549704
2020-04-30 0.146584
2020-05-31 0.983613
Freq: M, dtype: float64
向前移动3天
ts.shift(-3,freq='D')
2020-01-28 0.185458
2020-02-26 0.549704
2020-03-28 0.146584
2020-04-27 0.983613
dtype: float64
通过Day或MonthEnd移动
from pandas.tseries.offsets import Day,MonthEnd
now=datetime(2020,1,27)
now+3*Day()
Timestamp('2020-01-30 00:00:00')
now+MonthEnd()
Timestamp('2020-01-31 00:00:00')
五、时区处理-tz/tz_convert
python的时区信息来自第三方库pytz,pandas包装了pytz的功能
查看所有时区
pytz.common_timezones
转换时区- tz_convert
rng=pd.date_range('3/9/2020 9:30',periods=6,freq='D',tz='UTC')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts
2020-03-09 09:30:00+00:00 -1.779006
2020-03-10 09:30:00+00:00 -0.293860
2020-03-11 09:30:00+00:00 -0.174114
2020-03-12 09:30:00+00:00 0.749316
2020-03-13 09:30:00+00:00 0.342134
2020-03-14 09:30:00+00:00 1.101283
Freq: D, dtype: float64
ts.tz_convert('Asia/Shanghai')
2020-03-09 17:30:00+08:00 -1.779006
2020-03-10 17:30:00+08:00 -0.293860
2020-03-11 17:30:00+08:00 -0.174114
2020-03-12 17:30:00+08:00 0.749316
2020-03-13 17:30:00+08:00 0.342134
2020-03-14 17:30:00+08:00 1.101283
Freq: D, dtype: float64
六、时期及算术运算-period
时期(period)表示的是时间区间,比如数日、数月、数季、数年等
下面这个Period对象表示从2020年1月1日到2020年12月31日之间的整段时间
p=pd.Period(2020,freq='A-DEC')
p
Period('2020', 'A-DEC')
创建规则的时期范围
#季度为Q生成13个时间
pd.period_range("2019-01", periods=13, freq="Q")
#Q代表季度为频率,默认的后缀为DEC代表一年以第1个月为结束【最后一个月为1月份】
pd.period_range("2019-01", periods=13, freq="Q-JAN")
# 以季度Q【年为频率】生成13个时间
pd.period_range("2019-01", periods=13, freq="Y")
#以季度Q【2个月为频率】生成13个时间
pd.period_range("2019-01", periods=13, freq="2m")
PeriodIndex类保存了一组Period,可以在pandas数据结构中用作轴索引
rng=pd.period_range('1/1/2020','6/30/2020',freq='M')
rng
PeriodIndex(['2020-01', '2020-02', '2020-03', '2020-04', '2020-05', '2020-06'], dtype='period[M]', freq='M')
pd.Series(np.random.randn(6),rng)
2020-01 -1.050150
2020-02 -0.828435
2020-03 1.648335
2020-04 1.476485
2020-05 0.779732
2020-06 -1.394688
Freq: M, dtype: float64
使用字符串创建PeriodIndex
Q代表季度为频率,默认的后缀为DEC代表一年以第12个月为结束
pd.PeriodIndex(['2020Q3','2020Q2','2020Q1'],freq='Q-DEC')
Period和PeriodIndex互转-asfreq
p=pd.Period('2020',freq='A-DEC')
p.asfreq('M',how='start')
Period('2020-01', 'M')
p=pd.Period('2020-08',freq='M')
p.asfreq('A-JUN')
Period('2021', 'A-JUN')
to_period可以将datetime转period
rng=pd.date_range('1/1/2020',periods=6,freq='D')
ts=pd.Series(np.random.randn(6),index=rng)
ts
2020-01-01 -1.536552
2020-01-02 -0.550879
2020-01-03 0.601546
2020-01-04 -0.103521
2020-01-05 0.445024
2020-01-06 1.127598
Freq: D, dtype: float64
ts.to_period('M')
2020-01 -1.536552
2020-01 -0.550879
2020-01 0.601546
2020-01 -0.103521
2020-01 0.445024
2020-01 1.127598
Freq: M, dtype: float64
to_timespame可以将Period转换为时间戳
ts.to_period('M').to_timestamp()
七、频率转换-resample
重采样(resampling)指将时间序列从一个频率转换到另一个频率的处理过程
pandas对象都带有一个resample方法,是各种频率转换的函数
降采样率
#查看100天的采样
rng=pd.date_range('1/1/2020',periods=100,freq='D')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
# 转为一月的
ts.resample('M').mean()
2020-01-31 -0.049213
2020-02-29 -0.155195
2020-03-31 -0.000091
2020-04-30 -0.023561
Freq: M, dtype: float64
分钟的采样转为5分钟的
rng=pd.date_range('1/1/2020',periods=12,freq='T')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts.resample('5min').sum()
2020-01-01 00:00:00 1.376219
2020-01-01 00:05:00 0.883248
2020-01-01 00:10:00 -0.939534
Freq: 5T, dtype: float64
通过groupby进行采样,传入一个能够访问时间序列的索引上字段的函数
rng=pd.date_range('1/1/2020',periods=100,freq='D')
ts=pd.Series(np.random.randn(len(rng)),index=rng)
ts.groupby(lambda x:x.month).mean()
2020-01-31 0.182420
2020-02-29 0.200134
2020-03-31 -0.108818
2020-04-30 -0.187426
Freq: M, dtype: float64
升采样率
示例: 周数据转为日
# 周数据
frame=pd.DataFrame(
np.random.randn(2,4),
index=pd.date_range('1/1/2020',periods=2,freq='W-WED'),
columns=['Colorado','Texa','New York','Ohio']
)
# #转为日
frame.resample('D').asfreq()
#用前面的值填充
frame.resample('D').ffill()
#用后面的值填充
frame.resample('D').bfill()
八、如何格式化时间序列
可以使用strftime格式化为相应的字符串,具体方法可以参考Series的API文档的Datetime操作
x=pd.date_range('2020-01-01',periods=30)
x.strftime('%Y-%m')

pandas时间序列常用操作的更多相关文章
- Pandas库常用函数和操作
1. DataFrame 处理缺失值 dropna() df2.dropna(axis=0, how='any', subset=[u'ToC'], inplace=True) 把在ToC列有缺失值 ...
- pandas_时间序列和常用操作
# 时间序列和常用操作 import pandas as pd # 每隔五天--5D pd.date_range(start = '',end = '',freq = '5D') ''' Dateti ...
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- pandas中常用的操作一
pandas中常用的功能: 1.显示所有的列的信息,999表示显示最大的列为999 pd.options.display.max_columns=999 2.读取excel时设置使用到列的名称,和列的 ...
- Pandas 时间序列处理
目录 Pandas 时间序列处理 1 Python 的日期和时间处理 1.1 常用模块 1.2 字符串和 datetime 转换 2 Pandas 的时间处理及操作 2.1 创建与基础操作 2.2 时 ...
- Python——Pandas 时间序列数据处理
介绍 Pandas 是非常著名的开源数据处理库,我们可以通过它完成对数据集进行快速读取.转换.过滤.分析等一系列操作.同样,Pandas 已经被证明为是非常强大的用于处理时间序列数据的工具.本节将介绍 ...
- Pandas时间序列
Pandas时间序列 pandas 提供了一组标准的时间序列处理工具和数据算法 数据类型及操作 Python 标准库的 datetime datetime 模块中的 datetime. time. c ...
- Pandas的基础操作(一)——矩阵表的创建及其属性
Pandas的基础操作(一)——矩阵表的创建及其属性 (注:记得在文件开头导入import numpy as np以及import pandas as pd) import pandas as pd ...
- python数据结构:pandas(2)数据操作
一.Pandas的数据操作 0.DataFrame的数据结构 1.Series索引操作 (0)Series class Series(base.IndexOpsMixin, generic.NDFra ...
随机推荐
- VJhrbustacm0304专题一题解
L:搬果子 用一般的priority_queue做就可以了. 优先队列//扔进去就能自动排序的序列,记得T组数据要pop干净 #include<iostream> #include< ...
- HDU - 5015 233 Matrix (矩阵快速幂)
In our daily life we often use 233 to express our feelings. Actually, we may say 2333, 23333, or 233 ...
- wpf遮罩~~~(搬运过来的)
方便自己以后用,原文:https://blog.csdn.net/lwwl12/article/details/78472235 直接上代码 public partial class BaseWind ...
- ORACLE 两表关联更新三种方式
不多说了,我们来做实验吧. 创建如下表数据 select * from t1 ; select * from t2; 现需求:参照T2表,修改T1表,修改条件为两表的fname列内容一致. 方式1,u ...
- spring boot 多数据源加载原理
git代码:https://gitee.com/wwj912790488/multiple-data-sources DynamicDataSourceAspect切面 必须定义@Order(-10) ...
- 16python的map函数,filter函数,reduce函数
map num_l = [1,6,8,9] def map_test(func,array): ret = [] for i in array: res = func(i) ret.append(re ...
- 在springboot环境下tk-mybatis的使用记录
1. 新建springboot工程 访问https://start.spring.io/,新建一个springboot工程. 自动生成的工程主要的注意点如下: 1)pom.xml <parent ...
- saltstack的配置配置
一.为不同的环境设置不同的文件目录 1.1 修改配置文件 /etc/salt/master [root@node1 salt]# vim /etc/salt/master file_roots: ba ...
- 使用poi读写excel、向excel追加数据等,包括.xls和.xlsx文档
1.使用maven引入jar包 <dependency> <groupId>org.apache.poi</groupId> <artifactId>p ...
- 什么是特性(Attribute)?
由面向对象思想,我们诞生了很多种面向对象编程语言,比如常用的Java,C#,这些语言中都共有类(Class)的概念,并用各自的方式去阐述.编写Class,或许方式不同,但它们都有一个共同点,即“类是对 ...