Storm使用总结
Strom安装
Strom启动
./zkServer.sh start
启动nimbus主节点: nohup bin/storm nimbus >> /dev/null &
启动supervisor从节点: nohup bin/storm supervisor >> /dev/null &
都启动完毕之后,启动strom ui管理界面: bin/storm ui &
使用了drpc,要启动drpc: nohup bin/storm drpc &
Storm简介
- 低延迟。高性能。可扩展。
- 分布式。系统都是为应用场景而生的,如果你的应用场景、你的数据和计算单机就能搞定,那么不用考虑这些复杂的问题了。我们所说的是单机搞不定的情况。
- 容错。一个节点挂了不影响应用。
实现一个实时计算系统。如果仅仅需要解决这5个问题,可能会有无数种方案,使用消息队列+分布在各个机器上的工作进程不就ok啦?
- 容易在上面开发应用程序。设计的系统需要应用程序开发人员考虑各个处理组件的分布、消息的传递吗?那就有点麻烦啊,开发人员可能会用不好,也不会想去用。
- 消息不丢失。用户发布的一个宝贝消息不能在实时处理的时候给丢了;更严格一点,如果是一个精确数据统计的应用,那么它处理的消息要不多不少才行。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
- 消息严格有序。有些消息之间是有强相关性的,比如同一个宝贝的更新和删除操作消息,如果处理时搞乱顺序完全是不一样的效果了。
- 快速。系统的设计保证了消息能得到快速的处理,使用ZeroMQ作为其底层消息队列。
Storm的架构、基本概念
Nimbus:主节点,负责资源分配和任务调度。
Supervisor:每个工作节点都运行了一个名为“Supervisor”的守护进程,负责接收nimbus分配的任务,启动和停止自己管理的N个worker进程。
Worker:运行具体处理组件逻辑的进程。一个Worker对应一个Topo,conf.setNumWorkers(2); 一个worker对应一个端口对应一个JVM进程!不是对应一台机器!
Topology:storm中运行的一个实时应用程序(相当于MR),(Spout + Bolt = Topo = Component,Spout,Bolt的名字就是ComponentId)形成有向图。点是计算节点,边是数据流。
Executor执行线程:就是setBolt制定的那个数字!!用来设置线程数。
Task:task不与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程executor。代表最大并发度。用来设置要执行的task数目,处理逻辑的数目。
Spout:Topology中的数据流源头。通常情况下spout会从外部数据源中读取数据,然后转换为Topology内部的源数据,然后封装成Tuple形式,之后发送到Stream中,Bolt再接收任意多个输入stream, 作一些业务处理。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
Bolt:一个Topology中接受数据然后执行处理的逻辑处理组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数。
Tuple:Bolt之间一次消息传递的基本单元:有序元素的列表。通常建模为一组逗号分隔的值,所以就是一个value list。
Stream:tuple的序列流。
Storm分组机制
Stream Grouping 定义了一个流在Bolt Task间该如何被切分进行接收,由接收数据的bolt来设置。
Bolt在多线程下有7种类型的stream grouping ,单线程下都是All Grouping:
Shuffle Grouping(随机分组): 随机派发stream里面的tuple, 保证Bolt的每个Task接收到的tuple数目相同平均分配。(Spout 100条,Bolt的两个Task每个获得50条Tuple)
Fields Grouping(按字段分组): 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts。
作用:(1)过滤多输出Field中选择某些Field;去重操作,Join。
(2)相同的tuple会分给同一个Task处理,比如WordCount,相同的单词给同一个Task统计才能准确,而使用Shuffle Grouping就不行!!Non Grouping (不分组):不关心到底谁会收到它的tuple。这种分组和Shuffle grouping是一样的效果,不平均分配。
LocalOrShuffleGrouping:如果目标Bolt中的一个或者多个Task和当前产生数据的Task在同一个Worker进程里面,那么就走内部的线程间通信,将Tuple直接发给在当前Worker进程的目的Task。否则,同shuffleGrouping。该方式数据传输性能优于shuffleGrouping,因为在Worker内部传输,只需要通过Disruptor队列就可以完成,没有网络开销和序列化开销。因此在数据处理的复杂度不高,而网络开销和序列化开销占主要地位的情况下,可以优先使用localOrShuffleGrouping来代替shuffleGrouping。
DirectGrouping :这种方式发送者可以指定下游的哪个Task可以接收这个元组。只有在数据流被声明为直接数据流时才能够使用直接分组方式。使用直接数据流发送元组需要使用 OutputCollector 的 emitDirect 方法。Bolt 可以通过 TopologyContext 来获取它的下游消费者的任务 id,也可以通过跟踪 OutputCollector 的 emit 方法(该方法会返回它所发送元组的目标任务的 id)的数据来获取任务 id。
All Grouping (广播发送): 对于每一个tuple, 所有的Bolts都会收到。(Spout 100条,两个Bolt每个获得100条Tuple,一共200条)
Global Grouping (全局分组): tuple被分配到一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
并发度相关概念
Executor数代表实际并发数(worker进程中的线程数),这样设置一个并发数:setBolt(xx, xx, 1);。
Task数代表最大并发度,是具体的处理逻辑实例,这样设置2个task:setBolt(xx, xx, 1).setTask(2);
这样就两个task共享一个executor线程,互相抢executor线程来执行bolt的execute方法。
通过storm rebalance命令:一个component的task数是不会改变的, 但是一个componet的executer数目是会发生变化的。
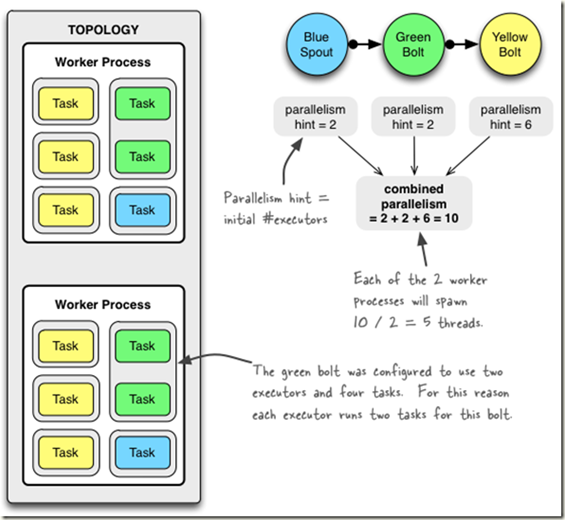
看看下面的例子:
Config conf = new Config();
// 2个进程
conf.setNumWorkers(2);
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());
通过setBolt和setSpout一共定义 2 + 2 + 6 = 10个 executor threads;
前面 setNumWorkers 设置2个workers, 所以storm会平均在每个worker上run 5个executors !!!!
而对于green-bolt, 定义了4个tasks, 所以每个executor中有2个tasks。
Storm使用总结的更多相关文章
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
- 理解Storm并发
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 注:本文主要内容翻译自understanding-the-parall ...
- Storm构建分布式实时处理应用初探
最近利用闲暇时间,又重新研读了一下Storm.认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算.对于Hadoop, ...
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- Storm介绍(二)
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文是Storm系列之一,主要介绍Storm的架构设计,推荐读者在阅读 ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- 交易系统使用storm,在消息高可靠情况下,如何避免消息重复
概要:在使用storm分布式计算框架进行数据处理时,如何保证进入storm的消息的一定会被处理,且不会被重复处理.这个时候仅仅开启storm的ack机制并不能解决上述问题.那么该如何设计出一个好的方案 ...
- 由提交storm项目jar包引发对jar的原理的探索
序:在开发storm项目时,提交项目jar包当把依赖的第三方jar包都打进去提交storm集群启动时报了发现多个同名的文件错误由此开始了一段对jar包的深刻理解之路. java.lang.Runtim ...
随机推荐
- Ubuntu里node命令无效解决方法
在ubuntu里用sudo apt-get install nodejs安装Node.js后, 会发现terminals里运行node命令(比如node –-version)时候会有No such f ...
- MacOS配置双网
目的 日常工作中,我们可能会同时需要用到公司的内网以及互联网,为了避免来回的切换,我们可以通过配置电脑的两个网卡来实现同时访问内网和互联网. 环境说明 互联网 无线网卡 网关 子网掩码 内网 有线网卡 ...
- 小爬爬6: 网易新闻scrapy+selenium的爬取
1.https://news.163.com/ 国内国际,军事航空,无人机都是动态加载的,先不管其他我们最后再搞中间件 2. 我们可以查看到"国内"等板块的位置 新建一个项目,创建 ...
- Python学习之路12☞模块与包
一 模块 1.1 什么是模块? 一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 1.2 为何要使用模块? 如果你退出python解释器然后重新进入,那么你之前 ...
- QT 中如何实现一个简单的动画
QT可以实现一下简单的动画,比如 运动的时钟 闪烁的按钮. 动画的实现: (1)创建一个定时器 (2)调用QWidget::update()通知界面重绘 实现一个按钮闪烁的例子: circlewidg ...
- Python collections的使用
collections是Python内建的一个集合模块,提供了许多有用的集合类. 本文将介绍以下几种方法: namedtuple Counter() deque OrderedDict 一.named ...
- Python多版本pip安装库的问题
引 机器上总是会有Python2.7的版本和Python3.x的版本,今天接触到一台服务器上面有Python2.7和Python3.4,想在Python3.4下安装一个TensorFlow,但不管怎么 ...
- windows 和 linux 安装 tensorflow
安装 跟往常一样,我们用 Conda 来安装 TensorFlow.你也许已经有了一个 TensorFlow 环境,但要确保你安装了所有必要的包. OS X 或 Linux 运行下列命令来配置开发环境 ...
- day7_python之面向对象高级-反射
反射:通过字符串去找到真实的属性,然后去进行操作 python面向对象中的反射:通过字符串的形式操作对象相关的属性.python中的一切事物都是对象(都可以使用反射) 1.两种方法访问对象的属性 cl ...
- caffe 下一些参数的设置
weight_decay防止过拟合的参数,使用方式:1 样本越多,该值越小2 模型参数越多,该值越大一般建议值:weight_decay: 0.0005 lr_mult,decay_mult关于偏置与 ...