spinor/spinand flash之高频通信延迟采样
SPI协议
对于spinor和spinand flash,其通信总线为SPI总线。
SPI有四种工作模式,对应不同的极性和相位组合
极性,一般表示为CPOL(Clock POLarity),即SPI空闲时时钟信号SCLK的电平(0:空闲为低电平; 1:空闲为高电平)
相位,一般表示为CPHA(Clock PHAse),即SPI在SCLK第几个边沿开始采样(0:第一个边沿采样; 1:第二个边沿采样)
四种模式为:
| CPOL | CPHA | |
|---|---|---|
| mode0 | 0 | 0 |
| mode1 | 0 | 1 |
| mode2 | 1 | 0 |
| mode3 | 1 | 1 |
SPI FLASH通信
spinor和spinand,一般都支持mode0和mode3。即都是在下降沿送数据,上升沿采样。
具体一点,在某次读数据的时候,主控端发出一个下降沿,flash收到后,就把数据准备好送到spi总线上,在接下来的上升沿时,主控端就对SPI的数据线进行采样,得到这个bit的数据是0还是1。
接着主控端又送出下降沿,flash收到后又送出1bit的数据,供主控在下一个上升沿的时候读取。
高频下的问题
上面描述的通信过程,一个沿触发送数据一个沿进行采样,一来一往配合默契,看起来没什么问题。
但其实这里面隐含了一个要求,就是flash必须能跟得上节奏,需要在收到主控的下降沿之后,迅速准备好数据,在下一个上升沿到来之前送到总线上。否则主控在下一个上升沿采样到的数据就是错的了。
这个在低频的时候,是没什么问题的,例如在5M的clock下,下降沿到上升沿,时间大概是100ns,这个时间足够flash准备好数据并送上总线了,轻轻松松。
但在更高的时钟频率下,flash就有压力了,在100M的clock下,下降沿到上升沿,时间大概是5ns。如果是104M, 133M等,那时间就更短了。
在这种时钟频率下,flash来得及送数据吗? 很遗憾,来不及,请看规格书


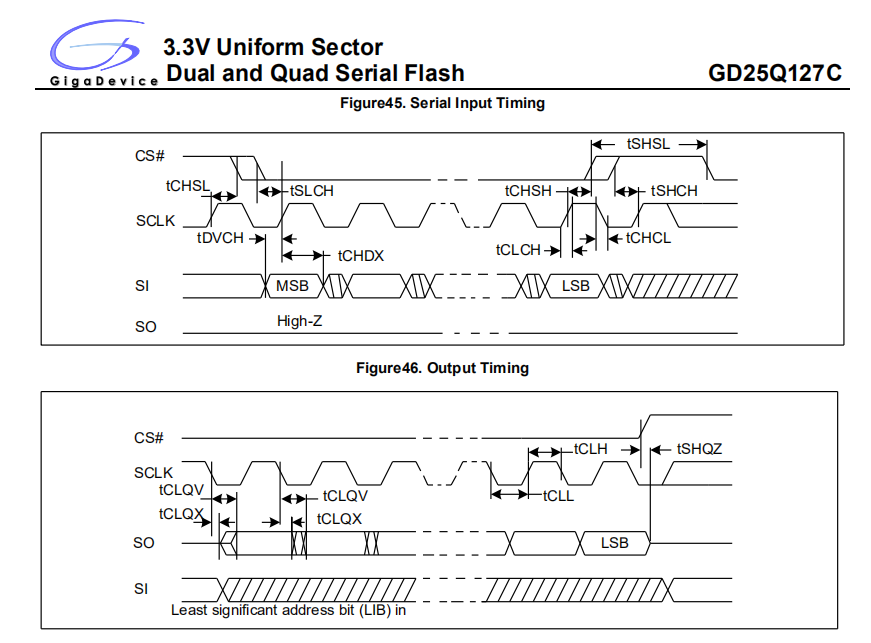

flash规格书标注的 Clock Low to Output Valid, 即从收到时钟下降沿到送出的数据有效,这个耗时就已经超过5ns了。
多找两家看看


看起来都差不多,100M下面,谁也满足不了这个5ns的时间要求。
如何解决
那既然flash无法准时送出数据,那主控在下一个上升沿就必然采样不到正确的数据了,怎么办?降低时钟频率吗
降低时钟频率当然可以解决问题,但还有另外的办法,那就是延迟采样。
主控知道在高频下,flash无法及时送出数据来,那没关系,我就晚一点再采样,等flash的数据到位之后再采样即可。
例如有些主控的SPI控制器可以配置,延迟半个周期采样或延迟一个周期采样,在100M的clock下,一个周期10ns。
那么不延迟的话,flash只有5ns的时间可以准备数据以及送数据,如果延迟半个周期采样,则有10ns,延迟1个周期,则有15ns。
具体应该延迟多少,就得看实际情况了,因为我们刚刚只关注了flash标注的 Clock Low to Output Valid 的值,其实实际的延迟,还会受其他因素影响,例如从主控发出下降沿,到flash实际收到下降沿的延迟。flash发出数据,到主控实际能采样到数据的延迟,如果走线较长的话,这些也是不可忽略的。
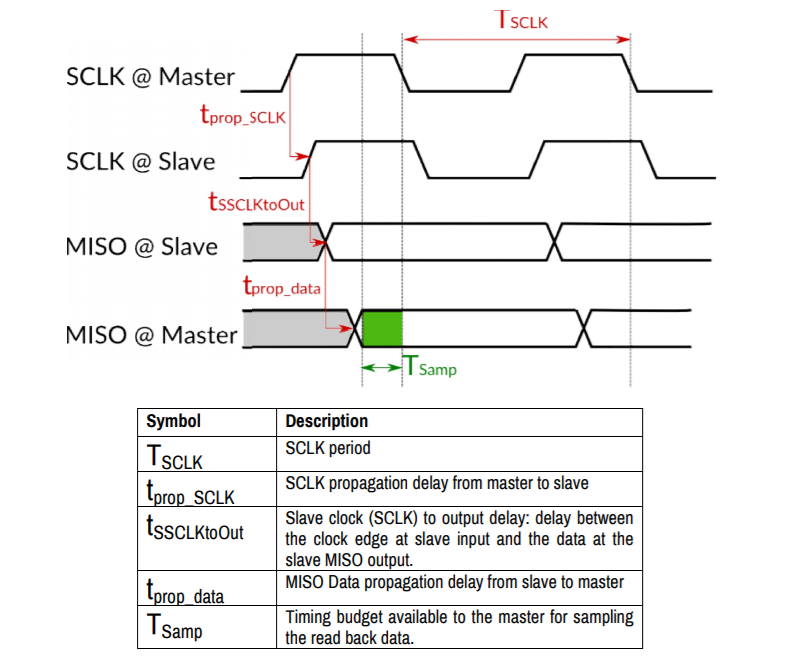
例如这篇文章https://www.byteparadigm.com/files/documents/Using-SPI-Protocol-at-100MHz.pdf 的举例,就算上了信号传播的延迟,从里面截一张图大家看下,更多信息可以看原文,就不搬运了
本文链接,https://www.cnblogs.com/zqb-all/p/12153583.html
spinor/spinand flash之高频通信延迟采样的更多相关文章
- Actionscript Flash Event.ENTER_FRAME 延迟间隔非常大 并且 pre-render 耗时非常严重
我遇到的问题是代码中不断的添加一个图标到舞台上,而且这个图标非常小,所以从内存也看不出什么问题. 但是由于舞台物件太多了,并且不断添加,导致渲染耗时严重. 而且这种错误,开发工具并不会报错,也不属于死 ...
- nor flash之4字节地址模式
背景 容量低于 16M bytes 的 nor,一般使用 3 字节地址模式,即命令格式是 cmd + addr[2] + addr[1] + addr[0] + ... 使用超过 16M bytes ...
- 性能tips
Latch 闩 锁的平级 采样时间不能太长,太频繁 一般情况下,性能图应该是一种趋势图,看的是趋势,不看某些单个点 在压测收集数据时,可能多种工具收集到的性能数据有少许差异,原因: 网络延迟,导致收集 ...
- Android IOS WebRTC 音视频开发总结(三五)-- chatroulette介绍
本文主要从技术角度介绍chatroulette,文章来自博客园RTC.Blacker,支持原创,转载请说明出处. 很多人不知道或没用过chatroulette,下面先来张界面截图让大家有个整体了解: ...
- [转帖]深度: NVMe SSD存储性能有哪些影响因素?
深度: NVMe SSD存储性能有哪些影响因素? http://www.itpub.net/2019/07/17/2434/ 之前有一个误解 不明白NVME 到底如何在队列深度大的情况下来提高性能, ...
- 存储系统设计——NVMe SSD性能影响因素一探究竟
目录1 存储介质的变革 2 NVME SSD成为主流 2.1 NAND FLASH介质发展 2.2 软件层面看SSD——多队列技术 2.3 深入理解SSD硬件 3 影响NVME SSD的性能因素 3. ...
- OFDM通信系统的MATLAB仿真(2)
关于OFDM系统的MATLAB仿真实现的第二篇随笔,在第一篇中,我们讨论的是信号经过AWGN信道的情况,只用添加固定噪声功率的高斯白噪声就好了.但在实际无线信道中,信道干扰常常是加性噪声.多径衰落的结 ...
- 记一次 spinor flash 读速度优化
背景 某个项目使用的介质是 spinor, 其 bootloader 需要从 flash 中加载 os. 启动速度是一个关键指标,需要深入优化.其他部分的优化暂且略过,此篇主要记录对 nor 读速度的 ...
- 一些VR延迟优化方法
http://m.blog.csdn.net/article/details?id=50667507 VR中的”延迟”, 特指”Motion-To-Photon Latency”, 指的是从用户运动开 ...
随机推荐
- Nacos: Namespace 和 Endpoint 在生产环境下的最佳实践
随着使用 Nacos 的企业越来越多,遇到的最频繁的两个问题就是:如何在我的生产环境正确的来使用 namespace 以及 endpoint.这篇文章主要就是针对这两个问题来聊聊使用 nacos 过程 ...
- BLOB类型对应Long binary,CLOB对应Long characters
BLOB类型对应Long binary,CLOB对应Long characters
- 阿里云CDN技术掌舵人文景:相爱相杀一路狂奔的这十年
导读:提到阿里云CDN,不得不提技术掌舵人姚伟斌(文景),虽然他不是团队中最“老”的同学,但他却历经了淘宝业务发展最为飞速的几年,见证了从最初服务淘宝和集团内部的CDN,到如今国内服务客户最多的云CD ...
- Codeforces Round #577 (Div 2)
A. Important Exam 水题 #include<iostream> #include<string.h> #include<algorithm> #in ...
- 在linux上安装pear
在搭建centreon的过程中,需要pear模块支持. 什么是pear pear是PHP扩展与应用库(the PHP Extension and Application Repository)的缩写. ...
- hsqldb使用
1 hsqldb介绍 HyperSQL DataBase 是一个现代的关系数据库管理软件,比较彻底遵从SQL:2008标准和JDBC4规范.支持SQL:2008标准所以的核心特性和很多的可选特性. H ...
- php 变量名前加一个下划线含义
https://segmentfault.com/q/1010000006467833 一个下划线是私有变量以及私有方法两个下划线是PHP内置变量. 以下划线开头,表示为类的私有成员. 这只是个不成文 ...
- HashMap和HashSet的使用,区别。集合,Array、Collection(List/Set/Queue)、Map
HashMap和HashSet的区别 HashMap和HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collectio ...
- springboot中各个版本的redis配置问题
今天在springboot中使用数据库,springboot版本为2.0.2.RELEASE,通过pom引入jar包,配置文件application.properties中的redis配置文件报错,提 ...
- H3C 单路径网络中环路产生过程(2)