大型SQL文件导入mysql方案
一. 场景
现有俩个体积较大的单表sql文件,一个为8G,一个为4G,要在一天内完整导入到阿里云的mysql中,需要同时蛮子时间和空间这俩种要求。
二. 思路
搜索了网上一堆的方案,总结了如下几个:
方案一:利用navicat远程导入
方案二:在阿里云ECS安装一个mysql-client,用source方案导入
方案三:购买阿里云DBMS高级版服务,可以导入1G以内ZIP压缩包
三. 尝试
折腾了许久的尝试,终于总结了一下的经验:
3.1 尝试navicat远程导入
操作简单,但是缺点很明显:导入效率低,严重占用本地的IO,影响机器的正常工作,所以立马放弃。
3.2 尝试source方案
3.2.1 实现步骤
STEP1 在测试环境的ECS上安装一个mysql-client
STEP2 修改mysql中的max_allowed_packet参数为10G大小,net_buffer_length参数也根据需求适度调大。
STEP3 因为是俩个表,写俩个脚本太麻烦了,可以利用一个sql脚本聚合实现,所以all.sql 的内容可以如下
source /mydata/sql/a.sql;
source /mydata/sql/b.sql;
STEP4 为避免ssh连接掉线而导致执行关闭,需要写一个shell脚本,通过nohup后台执行。
myshell.sh脚本如下
mysql -h host -uxxx -pxxx --database=user_database</mydata/sql/all.sql
STEP5 后台执行指令
nohup ./myshell.sh &
3.2.2 结果
测试速度相对快多了,但是由于第二天就需要,所以俩个表接近4000w行的数据绝对不能完成任务,所以方案取消。但是不是否定该方案,其他场景肯定满足。
3.3 尝试DMBS
由于我们数据库是阿里云的RDS,所以我们购买了对应的DBMS服务升级版,可以支持文件上传导入(包含1G内的ZIP)
3.3.1 压缩文件
压缩单表SQL文件为单独zip文件,压缩下来一个为0.9G,一个为1.2G
3.3.2 拆分文件
第一个sql文件上传后执行很顺利,但是第二个1.2G的zip包需要进行拆分
3.3.3 拆分方案
1.拆分zip压缩包
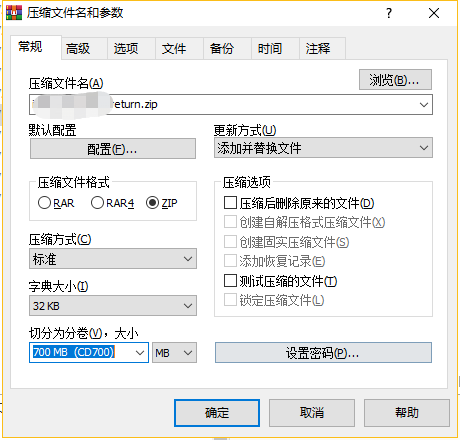
拆分出来的文件,手动改后缀后不满足DBMS的文件规范,失败~
2.高比例压缩文件
利用7z高比例压缩sql为7z后缀,压缩后体积明显小了,只有0.7G的体积,然后通过更改后缀为zip来上传。结果阿里云解析不出这样的格式,失败~
3.使用linux split 命令
split [--help][--version][-<行数>][-b <字节>][-C <字节>][-l <行数>][要切割的文件][输出文件名]
补充说明:
split可将文件切成较小的文件,预设每1000行会切成一个小文件。
-<行数>或-l<行数> 指定每多少行就要切成一个小文件。
-b<字节> 指定每多少字就要切成一个小文件。支持单位:m,k
-C<字节> 与-b参数类似,但切割时尽量维持每行的完整性。
虽然linux可以根据行拆分文件(这也是阿里云工单提供的解决方案),但是这个操作上传上去拆分,在下载下来上传到DBMS,文件体积这么大,来来回回一天过去了,所以放弃~
4.拆分单表sql文件为多份
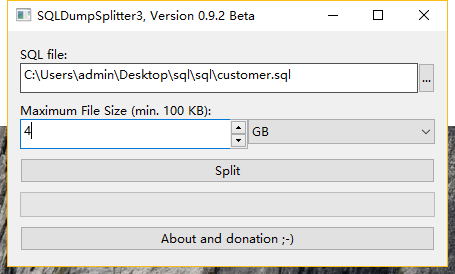
网上有个SQLDumpSplitter的工具可以拆分表为多份,但是搜索记录中和文章中都是推荐SQLDumpSplitter2的版本,版本太老了,体积较大的sql完全不支持,失败~
但是!我在SQLDumpSplitter2里面看到了软件的官网,发现官网有SQLDumpSplitter3版本,不抱希望的尝试了一下,居然支持大体积文件。成功了!!!
附带下载链接:https://philiplb.de/sqldumpsplitter3/ 太值得推广了。
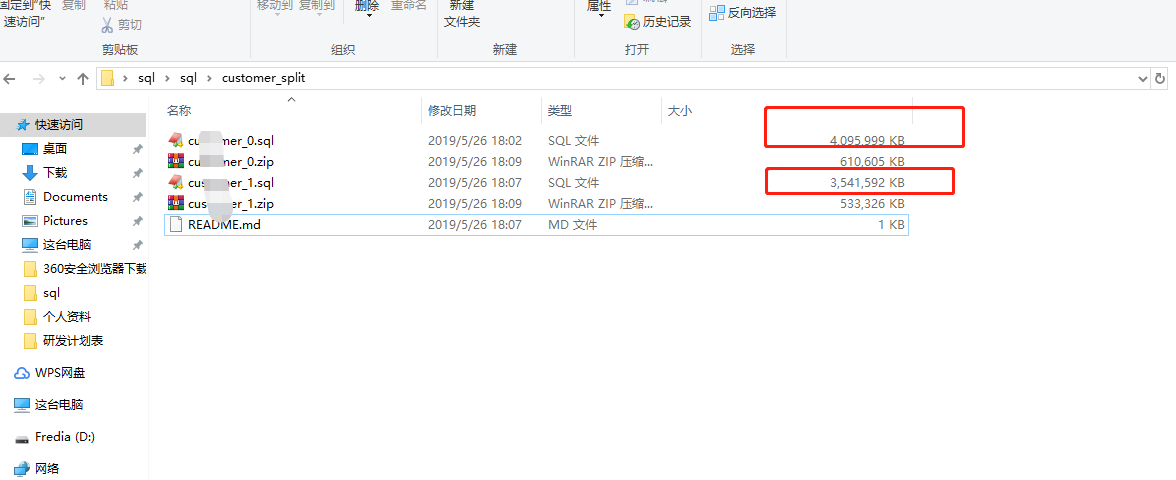
剩下就是按序上传对应文件即可完成,不得不得夸阿里云这方面做得真的好!
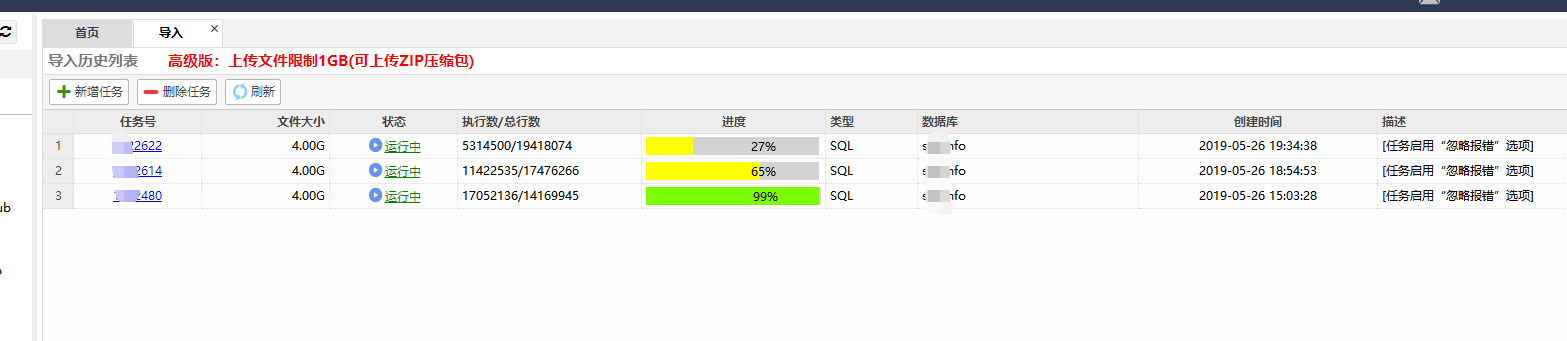
执行效率上面来说,也是可圈可点的:

四. 总结
今天针对这个需求,我首先查询了网上的大体方案,然后挑选了几个可执行的方案进行测试。排除了多个方案的情况下,采用了第三方的解决方案来完成这个问题。在阿里云DBMS的支持下,我们又尝试了多种文件的切割方案,最后通过SQLDumpSplitter3+DBMS来实现了,并且效率可观。过程中也发现,常用的client-source方案可以满足自建mysql+效率要求不是极致的场景。
综上,对于大型sql,最好的方案也是先切割(确保顺序性),然后利用一些更高效率的软件执行来实现最终结果,也需要根据时间空间场景灵活选用方案。
原文地址:https://www.jianshu.com/p/968fa5963d07
大型SQL文件导入mysql方案的更多相关文章
- 本地sql文件导入mysql数据库
mysql中配置my.ini interactive_timeout = 120 wait_timeout = 120 max_allowed_packet = 32M 导入sql运行命令 sourc ...
- mysql导入大型sql文件时注意事项
原文:http://blog.csdn.net/k21325/article/details/70808563 大型sql文件,需要在my.ini(windows)或者my.cnf(Linux)中设置 ...
- [转]csv文件导入Mysql
本文转自:https://blog.csdn.net/quiet_girl/article/details/71436108 本篇博客主要讲将csv文件导入Mysql的方法(使用命令行). Step1 ...
- 将.sql文件导入powerdesigner的实现方法详解
将.sql文件导入powerdesigner的步骤是本文我们主要要介绍的内容,步骤如下: 第一步:将要导入的库的所有表的表结构(不要表数据,只要表结构)导出成一个.sql文件. 第二步:在powerd ...
- mysql通过sql文件导入数据时出现乱码的解决办法
首先在新建数据库时一定要注意生成原数据库相同的编码形式,如果已经生成可以用phpmyadmin等工具再整理一次,防止数据库编码和表的编码不统一造成乱码. 方法一: 通过增加参数 –default-ch ...
- php+mysql将大数据sql文件导入数据库
<?php $file_name = "d:test.sql"; $dbhost = "localhost"; $dbuser = "root& ...
- 将本地sql文件导入到mysql中
cmd命令操作:先创建一个同名数据库,然后通过source导入sql文件 1.启动mysql 2.mysql -uroot -p 输入密码运行mysql 3.创建一个同名数据库 create data ...
- MySql 从SQL文件导入
1. 运行cmd进入命令模式,进入Mysql安装目录下的bin目录(即mysql.exe所在的目录): cd c:\"program Files"\MySQL\"MySQ ...
- linux 操作之一 如何在linux将本地数据*.sql文件导入到linux 云服务器上的mysql数据库
liunx 版本ubuntu 16.4 mysql 版本 5.6 1)准备*.sql文件 (* 是准备导入的sql文件的名字) 2)liunx 远程客户端 SecureCRT 7.0 alt+p ...
随机推荐
- Download QT
http://download.qt.io/archive/qt/
- poi之Excel(在线生成)下载
Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程序对Microsoft Office格式档案读和写的功能. poi之Excel下载 @RequestMappi ...
- 并查集+multiset+双指针——cf982D
感觉自己的解法很复杂,写了一大堆代码 但核心是从小到大枚举每个元素的值,然后把<=当前元素的值进行合并,由于这个过程是单调的,所以可以直接将新的元素合并到旧的并查集里去 维护并查集的同时维护每 ...
- NX二次开发-UFUN写入本地文本文档uc4524
1 NX9+VS2012 2 3 #include <uf.h> 4 #include <uf_cfi.h> 5 #include <uf_ui.h> 6 7 us ...
- NX二次开发-如何在类外面定义一个结构体
#include <uf.h> #include <uf_obj.h> #include <uf_part.h> using namespace NXOpen; u ...
- NX二次开发-C++time函数计时
NX11+VS2013 #include <uf.h> #include <uf_modl.h> #include <uf_ui.h> #include <t ...
- I/O与NIO(异步I/O)
1.原来的I/O库与NIO最重要的区别是数据打包和传输方式的不同,原来的I/O以流的方式处理数据,而NIO以块的方式处理数据. 面向流的I/O系统一次一个字节地处理数据.一个输入流产生一个字节的数据, ...
- hdu多校第五场1005 (hdu6628) permutation 1 排列/康托展开/暴力
题意: 定义一个排列的差分为后一项减前一项之差构成的数列,求对于n个数的排列,差分的字典序第k小的那个,n<=20,k<=1e4. 题解: 暴力打表找一遍规律,会发现,对于n个数的排列,如 ...
- CometOJ Contest #3 C
题目链接:https://cometoj.com/contest/38/problem/C?problem_id=1542&myself=0&result=0&page=1&a ...
- Python 文件处理一
1.路径下所有文件(不包含子文件) import os dirs = os.listdir(path) 注:dirs 是一个list 2.遍历路径下所有文件 def file_name(file_di ...