Spark kafka flume
Flume
Flume 是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,通过监控整个文件目录或者某一个特定文件,用于收集数据;同时Flume也 提供数据写到各种数据接受方(可定制)的能力,用于转发数据。

Kafka
kafka是分布式发布-订阅消息系统。
它的架构包括以下组件:
话题(Topic):是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。
生产者(Producer):是能够发布消息到话题的任何对象。
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
消费者(Consumer):可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。

Spark

参考:Spark Streaming+Hadoop 实时+离线分析

处理流程
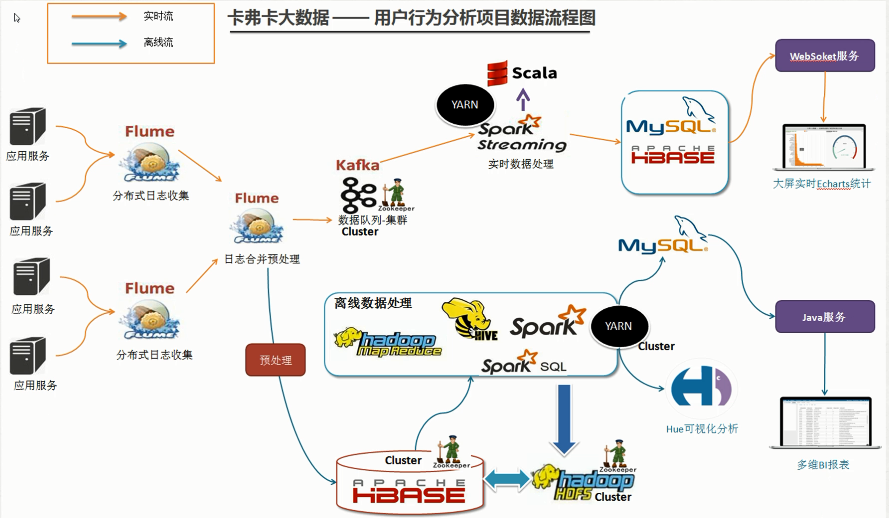
部署架构

————————————————
原文链接:https://blog.csdn.net/wyqwilliam/article/details/81916682
https://blog.csdn.net/u011254180/article/details/80172452
Spark kafka flume的更多相关文章
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现(转)
原文链接:Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现 Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读 ...
- java企业架构 spring mvc +mybatis + KafKa+Flume+Zookeeper
声明:该框架面向企业,是大型互联网分布式企业架构,后期会介绍linux上部署高可用集群项目. 项目基础功能截图(自提供了最小部分) 平台简介 Jeesz是一个分布式的框架,提供 ...
- Spark Streaming + Flume整合官网文档阅读及运行示例
1,基于Flume的Push模式(Flume-style Push-based Approach) Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Stre ...
- [Spark][kafka]kafka 生产者,消费者 互动例子
[Spark][kafka]kafka 生产者,消费者 互动例子 # pwd/usr/local/kafka_2.11-0.10.0.1/bin 创建topic:# ./kafka-topics.sh ...
- 【python】spark+kafka使用
网上用python写spark+kafka的资料好少啊 自己记录一点踩到的坑~ spark+kafka介绍的官方网址:http://spark.apache.org/docs/latest/strea ...
- MySQL数据实时增量同步到Kafka - Flume
转载自:https://www.cnblogs.com/yucy/p/7845105.html MySQL数据实时增量同步到Kafka - Flume 写在前面的话 需求,将MySQL里的数据实时 ...
- <Spark Streaming><Flume><Integration>
Overview Flume:一个分布式的,可靠的,可用的服务,用于有效地收集.聚合.移动大规模日志数据 我们搭建一个flume + Spark Streaming的平台来从Flume获取数据,并处理 ...
- spark与flume整合
spark-streaming与flume整合 push package cn.my.sparkStream import org.apache.spark.SparkConf import org ...
随机推荐
- 关于RiscV的一些资料整理
1. 基于RISC-V架构的开源处理器及SoC研究综述 https://mp.weixin.qq.com/s/qSD-q8y0_MY8R0MBA85ZZg 原文链接: https://blog.csd ...
- Spring Boot自动装配原理源码分析
1.环境准备 使用IDEA Spring Initializr快速创建一个Spring Boot项目 添加一个Controller类 @RestController public class Hell ...
- [兴趣使然]用python在命令行下画jandan像素超载鸡
下午刷煎蛋的时候看到 Dthalo 蛋友发的系列像素超载鸡,就想自己试试用python脚本画一个,老男孩视频里的作业真没兴趣,弄不好吧没意思,往好了写,自己控制不好,能力不够. 所以还是找自己有兴趣的 ...
- Mac-Mysql忘记root密码
cd /usr/local/mysql/bin 切换到root权限 ,需要输入密码: sudo su 输入之后会看见如下信息: sh-3.2# 使用如下命令以安全模式运行mysql ./mysqld_ ...
- Sklearn--(SVR)Regression学习笔记
今天介绍一个机器学习包,sklearn.其功能模块有regression\classification\clustering\Dimensionality reduction\data preproc ...
- HTTP&HTTPS协议详解之HTTP篇
一.HTTP简介 01.什么是HTTP HTTP(HyperText Transfer Protocol ,超文本传输协议),是一个基于请求与响应的,无状态的,应用层的协议,常基于TCP/IP协议传输 ...
- Python3(六) 面向对象
一.类的定义 1. class Student(): name = ' ' #定义变量 age = 0 def print_file(self): #定义函数 ...
- PYTHON 学习笔记3 元组、集合、字典
前言 在上一节的学习中.学习了基本的流程控制语句,if-elif-else for while 等,本节将拓展上一节学习过的一些List 列表当中操作的一些基本方法,以及元祖.序列等. 列表扩展 我们 ...
- VMware 克隆 CentOS 后网卡信息修改
概述 在我们需要多台 CentOS 虚拟机的时候,对已有虚拟机的系统进行克隆或是复制.但是这样做又有一个问题,克隆出来的虚拟机启动的时候你输入命令:ifconfig,eth0 网卡信息没了,只有一个 ...
- 杭电-------2032杨辉三角(C语言写)
#include<stdio.h> ][] = { }; void init() { int i, j; ; i < ; i++) { a[i][] = ; a[i][i] = ; ...