自学ConcuurentHashMap源码
自学ConcuurentHashMap源码#
参考:https://my.oschina.net/hosee/blog/675884
http://www.cnblogs.com/ITtangtang/p/3948786.html
本文需要关注的地方。
- 利用分段锁实现多个线程并发写入、删除或者修改(默认16);
- 利用HashEntry的不变性和 volatile 变量的可见性来保证get读几乎不需要加锁(判断获取的entry的value是否为null,为null时才使用加锁的方式再次去获取,原因是put的时候的指令重排序)
- get的三种情况分析
- 每个版本的ConcurrentHashMap几乎都有改动,本文说明的JDK6的源码。JDK8相比前面的版本改动最大,最后有简单的说明
一、基础知识
并发编程实践中,ConcurrentHashMap是一个经常被使用的数据结构,相比于Hashtable以及Collections.synchronizedMap(),ConcurrentHashMap能够提供更高的并发度。同步容器将所有对容器状态的访问都串行化,以实现它们的线程安全性。这种方法的代价是严重降低并发性,当多个线程竞争容器的锁时,吞吐量将严重降低。ConcurrentHashMap关键在于使用了分段锁技术。
在ConcurrentHashMap的实现中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。每一个锁保护的区域称为段(Segment),每个段其实就是一个小的Hashtable,它们有自己的锁。假设散列函数具有合理的分布性,并且关键字能够均匀分布,那么这大约能把对于锁的请求减少到原来的1/16,正是这项技术使得ConcurrentHashMap能够支持多达16个并发的写入器。
ConcurrentHashMap与其他并发容器一起增强了同步容器类:它们提供的迭代器不会抛出 ConcurrentModificationException,因此不需要在迭代过程中对容器加锁。ConcurrentHashMap 返回的迭代器具有弱一致性(Weakly Consistent),而并非“及时失败”。弱一致性的迭代器可以容忍并发的修改,当创建迭代器时会遍历已有的元素,并可以(但是不保证)在迭代器被构造后将修改操作反映给容器。
尽管有这些改进,但仍然有一些需要权衡的因素。对于一些需要在整个Map上进行计算的方法,例如size和isEmpty,这些方法的语义被略微减弱了以反映容器的并发特性。由于size 返回的结果在计算时可能已经过期了,它实际上只是一个估计值,因此允许size返回一个近似值而不是一个精确值。因为:事实上size和isEmpty这样的方法在并发环境下的用处很小,因为它们的返回值总在不断变化。因此,这些操作的需求被弱化了,以换取对其他更重要操作的性能优化,包括get、put、containsKey和remove等。
锁分段的一个劣势在于:与采用单个锁来实现独占访问相比,要获取多个锁来实现独占访问将更加困难并且开销更高。通常,在执行一个操作时最多只需获取一个锁,但在某些情况下需要加锁整个容器,例如当ConcurrentHashMap需要扩展映射范围,以及重新计算键值的散列值要分布到更大的桶集合中时,就需要获取分段锁集合中的所有锁。
1. 实现原理
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
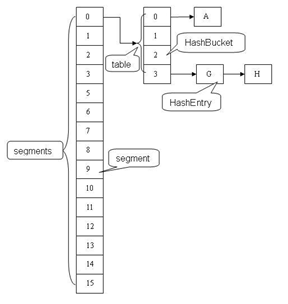
它把区间按照并发级别(concurrentLevel),分成了若干个segment。默认情况下内部按并发级别为16来创建。对于每个segment的容量,默认情况也是16。当然并发级别(concurrentLevel)和每个段(segment)的初始容量都是可以通过构造函数设定的。
2. 源码解读
ConcurrentHashMap中主要实体类就是三个:ConcurrentHashMap(整个Hash表),Segment(充当锁的角色,每个 Segment 对象守护整个散列表的某一个段的若干个桶),HashEntry(键值节点),对应上面的图可以看出之间的关系。
HashEntry 类
在 HashEntry 类中,key,hash 和 next 域都被声明为 final 型,value 域被声明为 volatile 型。
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
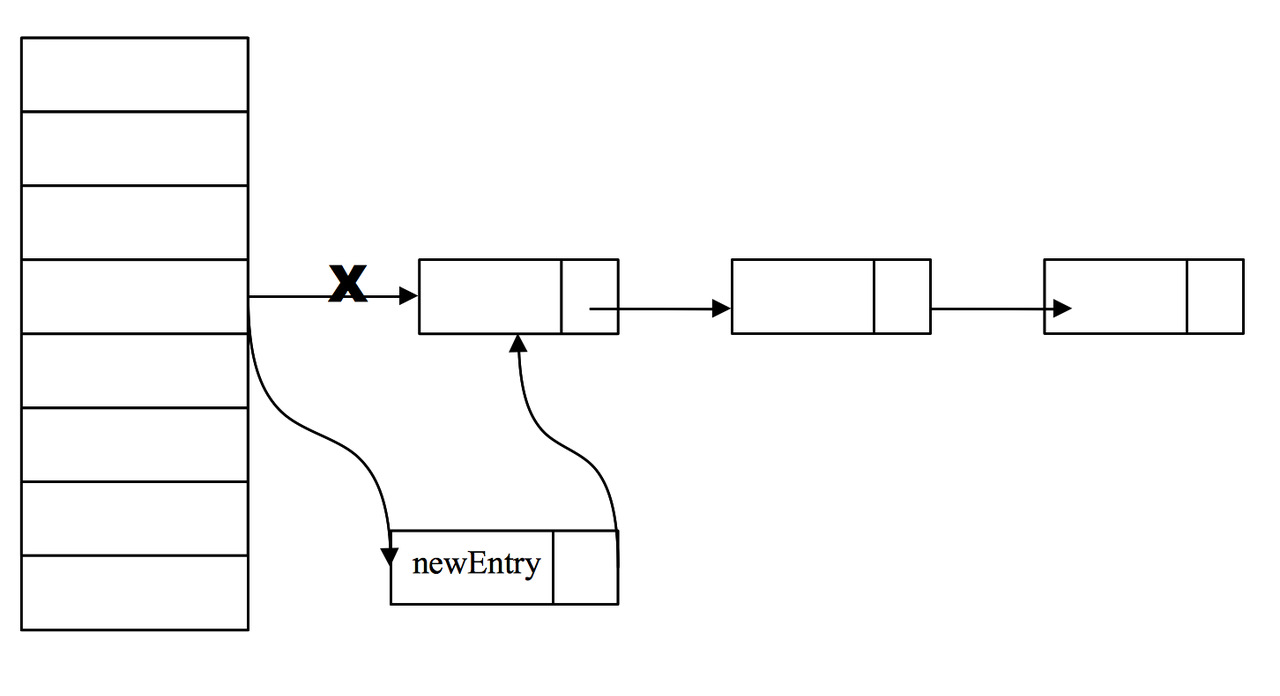
在 ConcurrentHashMap 中,在散列时如果产生“冲突”,将采用“链地址法”来处理“冲突”:把“冲突”的 HashEntry 对象链接成一个单向链表。由于 HashEntry 的 next 域为 final 型,所以新节点只能在链表的表头处插入。 下图是在一个空桶中依次插入 A,B,C 三个 HashEntry 对象后的结构图:

注意:由于只能在表头插入,所以链表中节点的顺序和插入的顺序相反。其实,哪怕next不是final的,也应该从表头插入,因为从表尾插入的话,首先需要遍历到表尾,然后才能插入节点,复杂度O(n)。
Segment 类
Segment 类继承于 ReentrantLock 类,从而每个segment都可以当做一个锁。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
table 是一个由 HashEntry 对象组成的数组。table 数组的每一个数组成员就是散列表的一个桶。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* 在本 segment 范围内,包含的 HashEntry 元素的个数
* 该变量被声明为 volatile 型
*/
transient volatile int count;
/**
* table 被更新的次数
*/
transient int modCount;
/**
* 当 table 中包含的 HashEntry 元素的个数超过本变量值时,触发 table 的再散列
*/
transient int threshold;
/**
* table 是由 HashEntry 对象组成的数组
*/
transient volatile HashEntry<K,V>[] table;
final float loadFactor;
Segment(int initialCapacity, float lf) {
loadFactor = lf;
setTable(HashEntry.<K,V>newArray(initialCapacity));
}
void setTable(HashEntry<K,V>[] newTable) {
threshold = (int)(newTable.length * loadFactor);
table = newTable;
}
/**
* 根据 key 的散列值,找到 table 中对应的那个桶(table 数组的某个数组成员)
*/
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
}
ConcurrentHashMap 类
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable {
/**
* 散列表的默认初始容量为 16,即初始默认为 16 段
*/
static final int DEFAULT_INITIAL_CAPACITY= 16;
static final float DEFAULT_LOAD_FACTOR= 0.75f;
/**
* 散列表的默认并发级别为 16。该值表示当前更新线程的估计数,在构造函数中没有指定这个参数时,使用本参数
*/
static final int DEFAULT_CONCURRENCY_LEVEL= 16;
/**
* segments 的掩码值
* key 的散列码的高位用来选择具体的 segment
*/
final int segmentMask;
/**
* 偏移量
*/
final int segmentShift;
/**
* 由 Segment 对象组成的数组
*/
final Segment<K,V>[] segments;
/**
* 创建一个带有指定初始容量、负载因子和并发级别的新的空散列表
*/
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if(!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if(concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// 寻找最佳匹配参数(不小于给定参数的最接近的 2 次幂)
int sshift = 0;
int ssize = 1;
while(ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift; // 偏移量值
segmentMask = ssize - 1; // 掩码值
this.segments = Segment.newArray(ssize); // 创建数组
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if(c * ssize < initialCapacity)
++c;
int cap = 1;
while(cap < c)
cap <<= 1;
// 依次遍历每个数组元素
for(int i = 0; i < this.segments.length; ++i)
// 初始化每个数组元素引用的 Segment 对象
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}
/**
* 创建一个带有默认初始容量 (16)、默认加载因子 (0.75) 和 默认并发级别 (16) 的空散列表。
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
put方法
首先,根据 key 计算出对应的 hash 值:
public V put(K key, V value) {
if (value == null) //ConcurrentHashMap 中不允许用 null 作为映射值
throw new NullPointerException();
int hash = hash(key.hashCode()); // 计算键对应的散列码
// 根据散列码找到对应的 Segment
return segmentFor(hash).put(key, hash, value, false);
}
然后,根据 hash 值找到对应的Segment 对象:
/**
* 使用 key 的散列码来得到 segments 数组中对应的 Segment
*/
final Segment<K,V> segmentFor(int hash) {
// 将散列值右移 segmentShift 个位,并在高位填充 0 ,然后把得到的值与 segmentMask 相“与”,从而得到 hash 值对应的 segments 数组的下标值,最后根据下标值返回散列码对应的 Segment 对象
return segments[(hash >>> segmentShift) & segmentMask];
}
最后,在这个 Segment 中执行具体的 put 操作:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); // 加锁,这里是锁定某个 Segment 对象而非整个 ConcurrentHashMap
try {
int c = count;
if (c++ > threshold) // 如果超过再散列的阈值
rehash(); // 执行再散列,table 数组的长度将扩充一倍
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
// 找到散列值对应的具体的那个桶
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { // 如果键值对已经存在
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value; // 替换 value 值
}
else { // 键值对不存在
oldValue = null;
++modCount; // 要添加新节点到链表中,所以 modCont 要加 1
// 创建新节点,并添加到链表的头部
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // 写 count 变量
}
return oldValue;
} finally {
unlock(); // 解锁
}
}
注意:这里的加锁操作是针对某个具体的 Segment,锁定的是该 Segment 而不是整个 ConcurrentHashMap。因为插入键 / 值对操作只是在这个 Segment 包含的某个桶中完成,不需要锁定整个ConcurrentHashMap。此时,其他写线程对另外 15 个Segment 的加锁并不会因为当前线程对这个 Segment 的加锁而阻塞。同时,所有读线程几乎不会因本线程的加锁而阻塞(除非读线程刚好读到这个 Segment 中某个 HashEntry 的 value 域的值为 null,此时需要加锁后重新读取该值)。
相比较于 HashTable 和由同步包装器包装的 HashMap每次只能有一个线程执行读或写操作,ConcurrentHashMap 在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap 可以支持 16 个线程执行并发写操作(如果并发级别设置为 16),及任意数量线程的读操作。
get方法
public V get(Object key) {
int hash = hash(key); // throws NullPointerException if key null
return segmentFor(hash).get(key, hash);
}
V get(Object key, int hash) {
if(count != 0) { // 首先读 count 变量
HashEntry<K,V> e = getFirst(hash);
while(e != null) {
if(e.hash == hash && key.equals(e.key)) {
V v = e.value;
if(v != null)
return v;
// 如果读到 value 域为 null,说明发生了重排序,加锁后重新读取
return readValueUnderLock(e);
}
e = e.next;
}
}
return null;
}
ConcurrentHashMap完全允许多个读操作并发进行,读操作并不需要加锁。关键是用 HashEntry 对象的不变性来降低读操作对加锁的需求。只是判断获取的entry的value是否为null,为null时才使用加锁的方式再次去获取。
在代码清单“HashEntry 类的定义”中我们可以看到,HashEntry 中的 key,hash,next 都声明为 final 型。这意味着,不能把节点添加到链接的中间和尾部,也不能在链接的中间和尾部删除节点。这个特性可以保证:在访问某个节点时,这个节点之后的链接不会被改变。这个特性可以大大降低处理链表时的复杂性。
下面分析在get的时候的线程安全性
1、如果get的过程中另一个线程恰好新增entry
HashEntry 类的 value 域被声明为 volatile 型,Java 的内存模型可以保证:某个写线程对 value 域的写入马上可以被后续的某个读线程“看”到。在 ConcurrentHashMap 中,不允许用 null 作为键和值,当读线程读到某个 HashEntry 的 value 域的值为 null 时,便知道发生了指令重排序现象(注意:volatile变量重排序规则,同时也是先行发生原则的一部分:对一个volatile变量的写操作先行发生于后面对这个变量的读操作,这里的“后面”同样是指时间上的先后顺序。所以,在tab[index] = new HashEntry<K,V>(key, hash, first, value);中,可能会出现当前线程得到的newEntry对象是一个没有完全构造好的对象引用。),需要加锁后重新读入这个 value 值。
2、如果get的过程中另一个线程修改了一个entry的value
由于对 volatile 变量的可见性,写线程对链表的非结构性修改能够被后续不加锁的读线程“看到”。
3、如果get的过程中另一个线程删除了一个entry
假设我们的链表元素是:e1-> e2 -> e3 -> e4 我们要删除 e3这个entry
因为HashEntry中next的不可变,所以我们无法直接把e2的next指向e4,而是将要删除的节点之前的节点复制一份,形成新的链表。它的实现大致如下图所示:
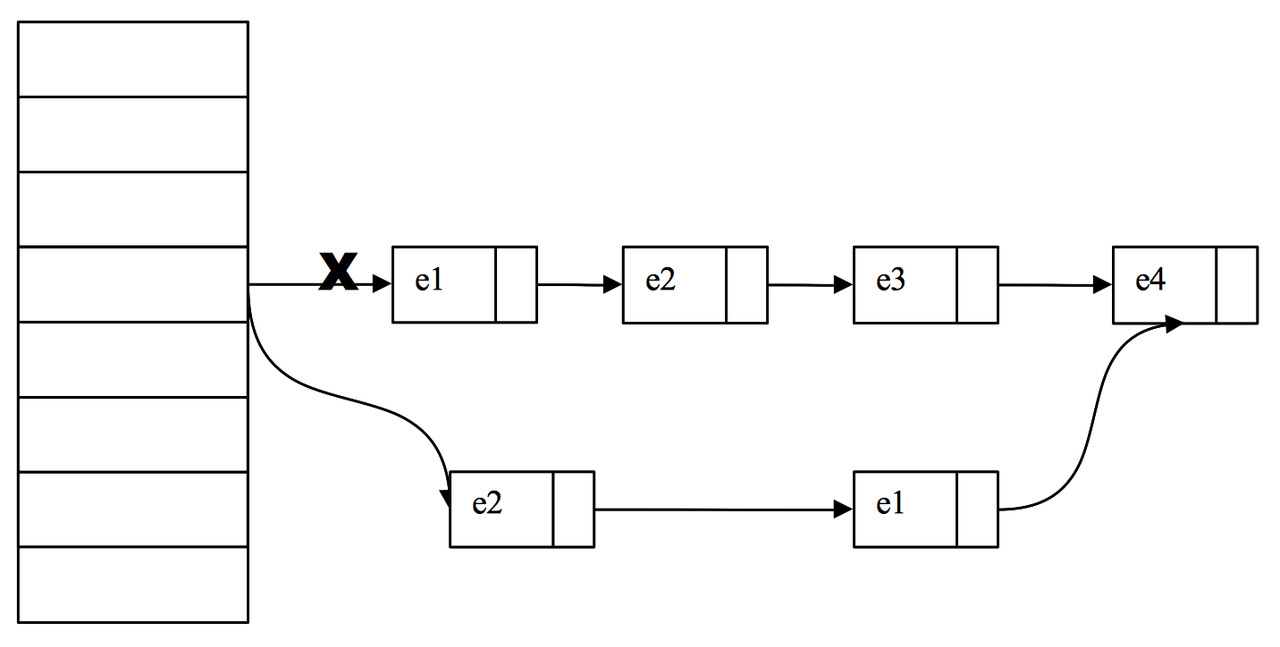
注意:最后才将数组中对应桶位置的链表替换为新链表(也就是在最后一步替换之前,tab[i]指向的始终是删除之前的链表,详细看下面的remove方法)。
如果我们get的也恰巧是e3,可能我们顺着链表刚找到e1,这时另一个线程就执行了删除e3的操作,而我们线程还会继续沿着旧的链表找到e3返回,这时候可能看到被删除的数据,但是在高并发环境下,这种影响是很小的。
remove方法
V remove(Object key, int hash, Object value) {
lock(); // 加锁
try{
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while(e != null&& (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if(e != null) {
V v = e.value;
if(value == null|| value.equals(v)) { // 找到要删除的节点
oldValue = v;
++modCount;
// 所有处于待删除节点之后的节点原样保留在链表中
// 所有处于待删除节点之前的节点被克隆(其实是把所有值取出来放到一个新的HashEntry对象中)到新链表中
HashEntry<K,V> newFirst = e.next;// 待删节点的后继结点
for(HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash, newFirst, p.value);
// 新的头结点是原链表中,删除节点之前的那个节点
tab[index] = newFirst;
count = c; // 写 count 变量
}
}
return oldValue;
} finally{
unlock(); // 解锁
}
}
和 get 操作一样,首先根据散列码找到具体的链表;然后遍历这个链表找到要删除的节点;最后把待删除节点之后的所有节点原样保留在新链表中,把待删除节点之前的每个节点克隆(其实是把所有值取出来放到一个新的HashEntry对象中)到新链表中;最后才将数组中对应桶位置的链表替换为新链表(也就是在替换之前,get的始终是删除之前的链表)。
下面通过图例来说明 remove 操作。假设写线程执行 remove 操作,要删除链表的 C 节点,另一个读线程同时正在遍历这个链表。

执行删除之后的新链表
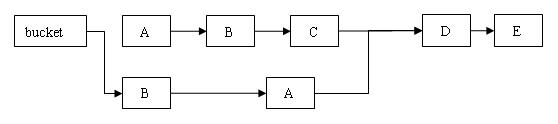
B中的next定义为final,无法修改将它指向D,因此C之前的所有节点都要重新建立。并且它们在新链表中的链接顺序被反转了。
size方法
在 ConcurrentHashMap中,每一个 Segment 对象都有一个 count 对象来表示本 Segment 中包含的 HashEntry 对象的个数。如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加的过程中count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment锁定。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put , remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。
二、比较
每个版本的ConcurrentHashMap几乎都有改动,本文说明的JDK6的源码。JDK8相比前面的版本改动最大,下面简要说一下:
- 它摒弃了Segment(段锁)的概念,而是启用了一种全新的方式实现,利用CAS算法。
- 它沿用了与它同时期的HashMap版本的思想,底层依然由“数组”+链表+红黑树的方式思想,但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
详细看: http://blog.csdn.net/u010723709/article/details/48007881
与Hashtable比较
由于Hashtable无论是读还是写还是遍历,都需要获得对象锁,串行操作,因此在多线程环境下性能比较差。
但是ConcurrentHashMap不能完全取代Hashtable:HashTable的迭代器是强一致性的,而ConcurrentHashMap是弱一致的。其实 ConcurrentHashMap的get,clear,iterator 都是弱一致性的。 Doug Lea 也将这个判断留给用户自己决定是否使用ConcurrentHashMap。
弱一致性:不保证数据完全处于一致性状态。比如:
get方法:
可能在get的时候获得一个还没完全构造好的HashEntry对象,导致获得的entry的value为null,此时需要加锁重新读取。
clear方法
public void clear() {
for (int i = 0; i < segments.length; ++i)
segments[i].clear();
}
因为没有全局的锁,在清除完一个segments之后,正在清理下一个segments的时候,已经清理segments可能又被加入了数据,因此clear返回的时候,ConcurrentHashMap中是可能存在数据的。因此,clear方法是弱一致的。
迭代器
java.util 包中的集合类都返回 fail-fast 迭代器,这意味着它们假设线程在集合内容中进行迭代时,集合不会更改它的内容。如果 fail-fast 迭代器检测到在迭代过程中进行了更改操作,那么它会抛出 ConcurrentModificationException。
ConcurrentHashMap中的迭代器主要包括entrySet、keySet、values方法。它们大同小异,这里选择entrySet解释。当我们调用entrySet返回值的iterator方法时,返回的是EntryIterator,在EntryIterator上调用next方法时,最终实际调用到了HashIterator.advance()方法,看下这个方法:
final void advance() {
if (nextEntry != null && (nextEntry = nextEntry.next) != null)
return;
while (nextTableIndex >= 0) {
if ( (nextEntry = currentTable[nextTableIndex--]) != null)
return;
}
while (nextSegmentIndex >= 0) {
Segment<K,V> seg = segments[nextSegmentIndex--];
if (seg.count != 0) {
currentTable = seg.table;
for (int j = currentTable.length - 1; j >= 0; --j) {
if ( (nextEntry = currentTable[j]) != null) {
nextTableIndex = j - 1;
return;
}
}
}
}
}
在这种迭代方式中,比如我们删除了链表的某个entry,但是在完成之前,迭代器获得了旧的链表指针,那么就会遍历旧的链表,并且不会报异常。
自学ConcuurentHashMap源码的更多相关文章
- 自学LinkedBlockingQueue源码
自学LinkedBlockingQueue源码 参考:http://www.jianshu.com/p/cc2281b1a6bc 本文需要关注的地方 生产者-消费者模式好处: 读取和插入操作所使用的锁 ...
- 自学Java HashMap源码
自学Java HashMap源码 参考:http://zhangshixi.iteye.com/blog/672697 HashMap概述 HashMap是基于哈希表的Map接口的非同步实现.此实现提 ...
- 自学Linux Shell9.4-基于Red Hat系统工具包存在两种方式之二:源码包
点击返回 自学Linux命令行与Shell脚本之路 9.4-基于Red Hat系统工具包存在两种方式之二:源码包 本节主要介绍基于Red Had的系统(测试系统centos) 1. 工具包存在两种方式 ...
- openWRT自学---自己编译的第一个 backfire10.03 版本的过程记录 --- 实际是由于下载了错误的backfire源码包导致的
基于 backfire10.03(从http://downloads.openwrt.org/backfire/10.03/ 中下砸的源码包backfire_10.03_source.tar.bz2: ...
- JDK源码阅读-------自学笔记(一)(java.lang.Object重写toString源码)
一.前景提要 Object类中定义有public String toString()方法,其返回值是 String 类型. 二.默认返回组成 类名+@+16进制的hashcode,当使用打印方法打印的 ...
- JDK源码阅读-------自学笔记(五)(浅析数组)
一.数组基础 1.定义和特点 数组也可以看做是对象,数组变量属于引用类型,数组中每个元素相当于该队形的成员变量,数组对象存储在堆中. 2.初始化数组 常用类初始化 // 整型初始化 int[] int ...
- JDK源码阅读-------自学笔记(二十五)(java.util.Vector 自定义讲解)
Vector 向量 Vector简述 1).Vector底层是用数组实现的List 2).虽然线程安全,但是效率低,所以并不是安全就是好的 3).底层大量方法添加synchronized同步标记,sy ...
- ZFPlayer 源码解读
源码下载地址:https://github.com/renzifeng/ZFPlayer 之前自己实现过一个模仿百思不得姐的demo https://github.com/agelessman/FFm ...
- 在Xcode中使用Git进行源码版本控制
http://www.cocoachina.com/ios/20140524/8536.html 资讯 论坛 代码 工具 招聘 CVP 外快 博客new 登录| 注册 iOS开发 Swift Ap ...
随机推荐
- 201521123121 《Java程序设计》第14周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. 数据库的基本特点 1.实现数据共享 数据共享包含所有用户可同时存取数据库中的数据,也包括用户可以用各种方式通过接 ...
- Winfrom 简单的安卓手机屏幕获取和安卓简单操作
为啥我要做这个东西了,是因为经常要用投影演示app ,现在有很多这样的软件可以把手机界面投到电脑上 ,但都要安装,比如说360的手机助手,我又讨厌安装,于是就自己捣鼓了下 做了这个东西, 实现了以下简 ...
- Oracle与Mysql区别简述
在Mysql中,一个用户下可以创建多个库: 而在Oracle中,Oracle服务器是由两部分组成 数据库实例[理解为对象,看不见的] 数据库[理解为类,看得见的] 一个数据库实例可拥有多个用户,一个用 ...
- python装饰器练习题
练习题1. 请使用python, 对下面的函数进行处理, def hello(name): print "hello, %s" % name 在函数被调用时打印耗时详情 <f ...
- 框架基础:ajax设计方案(六)--- 全局配置、请求格式拓展和优化、请求二进制类型、浏览器错误搜集以及npm打包发布
距离上一次博客大概好多好多时间了,感觉再不搞点东西出来,感觉就废了的感觉.这段时间回老家学习驾照,修养,然后7月底来上海求职(面了4家,拿了3家office),然后入职同程旅游,项目赶进度等等一系列的 ...
- 指定路径下建立Access数据库并插入数据
今天刚刚开通博客,想要把我这几天完成小任务的过程,记录下来.我从事软件开发的时间不到1年,写的不足之处,还请前辈们多多指教. 上周四也就是2016-04-14号上午,部门领导交给我一个小任务,概括来讲 ...
- 分享ES6中比较常用又强大的新特性
前言 es6有很多新东西,但是感觉常用的并不是很多,这里学习记录了一些我自己认为非常常用又强大的新特性. scoping 实用的块级作用域,let x = xxx 可以声明一个块级作用域的局部变量,简 ...
- 上传本地项目到githup仓库
1.在网上下载Git,然后安装 点击下一步 2.默认选择,下一步 3.选择使用命令行环境,下一步 4.后续步骤默认选择,点击下一步,等待安装完成 5.在githup上面新建一个仓库存放项目代码,具体方 ...
- vue环境搭建
1.Window 上安装Node.js 1.Windows 安装包(.msi) 32 位安装包下载地址 : https://nodejs.org/dist/v4.4.3/node-v4.4.3-x86 ...
- PHP CodeBase: 生成N个不重复的随机数
有25幅作品拿去投票,一次投票需要选16幅,单个作品一次投票只能选择一次.前面有个程序员捅了漏子,忘了把投票入库,有200个用户产生的投票序列为空.那么你会如何填补这个漏子? <?php /* ...