THE R QGRAPH PACKAGE: USING R TO VISUALIZE COMPLEX RELATIONSHIPS AMONG VARIABLES IN A LARGE DATASET, PART ONE
The R qgraph Package: Using R to Visualize Complex Relationships Among Variables in a Large Dataset, Part One
A Tutorial by D. M. Wiig, Professor of Political Science, Grand View University
In my most recent tutorials I have discussed the use of the tabplot()package to visualize multivariate mixed data types in large datasets. This type of table display is a handy way to identify possible relationships among variables, but is limited in terms of interpretation and the number of variables that can be meaningfully displayed.
Social science research projects often start out with many potential independent predictor variables for a given dependant variable. If these variables are all measured at the interval or ratio level a correlation matrix often serves as a starting point to begin analyzing relationships among variables.
In this tutorial I will use the R packages SemiPar, qgraph and Hmisc in addition to the basic packages loaded when R is started. The code is as follows:
###################################################
#data from package SemiPar; dataset milan.mort
#dataset has 3652 cases and 9 vars
##################################################
install.packages(“SemiPar”)
install.packages(“Hmisc”)
install.packages(“qgraph”)
library(SemiPar)
####################################################
One of the datasets contained in the SemiPar packages is milan.mort. This dataset contains nine variables and data from 3652 consecutive days for the city of Milan, Italy. The nine variables in the dataset are as follows:
rel.humid (relative humidity)
tot.mort (total number of deaths)
resp.mort (total number of respiratory deaths)
SO2 (measure of sulphur dioxide level in ambient air)
TSP (total suspended particles in ambient air)
day.num (number of days since 31st December, 1979)
day.of.week (1=Monday; 2=Tuesday; 3=Wednesday; 4=Thursday; 5=Friday; 6=Saturday; 7=Sunday
holiday (indicator of public holiday: 1=public holiday, 0=otherwise
mean.temp (mean daily temperature in degrees celsius)
To look at the structure of the dataset use the following
#########################################
library(SemiPar)
data(milan.mort)
str(milan.mort)
###############################################
Resulting in the output:
> str(milan.mort)
‘data.frame’: 3652 obs. of 9 variables:
$ day.num : int 1 2 3 4 5 6 7 8 9 10 …
$ day.of.week: int 2 3 4 5 6 7 1 2 3 4 …
$ holiday : int 1 0 0 0 0 0 0 0 0 0 …
$ mean.temp : num 5.6 4.1 4.6 2.9 2.2 0.7 -0.6 -0.5 0.2 1.7 …
$ rel.humid : num 30 26 29.7 32.7 71.3 80.7 82 82.7 79.3 69.3 …
$ tot.mort : num 45 32 37 33 36 45 46 38 29 39 …
$ resp.mort : int 2 5 0 1 1 6 2 4 1 4 …
$ SO2 : num 267 375 276 440 354 …
$ TSP : num 110 153 162 198 235 …
As is seen above, the dataset contains 9 variables all measured at the ratio level and 3652 cases.
In doing exploratory research a correlation matrix is often generated as a first attempt to look at inter-relationships among the variables in the dataset. In this particular case a researcher might be interested in looking at factors that are related to total mortality as well as respiratory mortality rates.
A correlation matrix can be generated using the cor function which is contained in the stats package. There are a variety of functions for various types of correlation analysis. The cor function provides a fast method to calculate Pearson’s r with a large dataset such as the one used in this example.
To generate a zero order Pearson’s correlation matrix use the following:
###############################################
#round the corr output to 2 decimal places
#put output into variable cormatround
#coerce data to matrix
#########################################
library(Hmisc)
cormatround round(cormatround, 2)
#################################################
The output is:
> cormatround > round(cormatround, 2) |
|
|
The matrix can be examined to look at intercorrelations among the nine variables, but it is very difficult to detect patterns of correlations within the matrix. Also, when using the cor() function raw Pearson’s coefficients are reported, but significance levels are not.
A correlation matrix with significance can be generated by using thercorr() function, also found in the Hmisc package. The code is:
#############################################
library(Hmisc)
rcorr(as.matrix(milan.mort, type=”pearson”))
###################################################
The output is:
> rcorr(as.matrix(milan.mort, type="pearson")) |
|
|
In a future tutorial I will discuss using significance levels and correlation strengths as methods of reducing complexity in very large correlation network structures.
The recently released package qgraph () provides a number of interesting functions that are useful in visualizing complex inter-relationships among a large number of variables. To quote from the CRAN documentation file qraph() “Can be used to visualize data networks as well as provides an interface for visualizing weighted graphical models.” (see CRAN documentation for ‘qgraph” version 1.4.2. See also http://sachaepskamp.com/qgraph).
The qgraph() function has a variety of options that can be used to produce specific types of graphical representations. In this first tutorial segment I will use the milan.mort dataset and the most basicqgraph functions to produce a visual graphic network of intercorrelations among the 9 variables in the dataset.
The code is as follows:
###################################################
library(qgraph)
#use cor function to create a correlation matrix with milan.mort dataset
#and put into cormat variable
###################################################
cormat=cor(milan.mort) #correlation matrix generated
###################################################
###################################################
#now plot a graph of the correlation matrix
###################################################
qgraph(cormat, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”groups”, vsize=10)
###################################################
This code produces the following correlation network:

The correlation network provides a very useful visual picture of the intercorrelations as well as positive and negative correlations. The relative thickness and color density of the bands indicates strength of Pearson’s r and the color of each band indicates a positive or negative correlation – red for negative and green for positive.
By changing the “layout=” option from “groups” to “spring” a slightly different perspective can be seen. The code is:
########################################################
#Code to produce alternative correlation network:
#######################################################
library(qgraph)
#use cor function to create a correlation matrix with milan.mort dataset
#and put into cormat variable
##############################################################
cormat=cor(milan.mort) #correlation matrix generated
##############################################################
###############################################################
#now plot a circle graph of the correlation matrix
##########################################################
qgraph(cormat, shape=”circle”, posCol=”darkgreen”, negCol=”darkred”, layout=”spring”, vsize=10)
###############################################################
The graph produced is below:
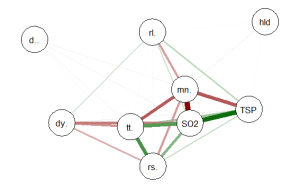
Once again the intercorrelations, strength of r and positive and negative correlations can be easily identified. There are many more options, types of graph and procedures for analysis that can be accomplished with the qgraph() package. In future tutorials I will discuss some of these.
转自:https://dmwiig.net/2017/03/10/the-r-qgraph-package-using-r-to-visualize-complex-relationships-among-variables-in-a-large-dataset-part-one/
THE R QGRAPH PACKAGE: USING R TO VISUALIZE COMPLEX RELATIONSHIPS AMONG VARIABLES IN A LARGE DATASET, PART ONE的更多相关文章
- R安装package报ERROR: a 'NAMESPACE' file is required
R安装package报错: [root@Hadoop-NN-01 mysofts]# R CMD INSTALL trimcluster_0.1-1.tar.gz * installing to li ...
- R(二): http与R脚本通讯环境安装
结合实际的工作环境,在开始R研究的时候,首先着手收集的就是能以Web方式发布R运行结果的基础框架,无耐的是,R一直以来常使用于个人电脑的客户端程序上,大家习惯性的下载R安装包,在自己的电脑上安装 -- ...
- 【R语言系列】R语言初识及安装
一.R是什么 R语言是由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman两个人共同发明. 其词法和语法分别源自Schema和S语言. R定义:一个能够自由幼小的用于统计计算和绘 ...
- python中换行,'\r','\n'及'、'\r\n'
'\r'的本意是回到行首,'\n'的本意是换行. 所以回车相当于做的是'\r\n'或者'\n\r'.'\r'就是换行并回行首, '\n'就是换行并回行首,用'\r\n'表示换行并回行首. window ...
- 【R笔记】给R加个编译器——notepad++
R的日记-给R加个编译器 转载▼ R是一款强大免费且开源的统计分析软件,这是R的长处,可也是其“缺陷”的根源:不似商业软件那样user-friendly.记得初学R时,给我留下最深印象的不是其功能的强 ...
- 【R语言入门】R语言中的变量与基本数据类型
说明 在前一篇中,我们介绍了 R 语言和 R Studio 的安装,并简单的介绍了一个示例,接下来让我们由浅入深的学习 R 语言的相关知识. 本篇将主要介绍 R 语言的基本操作.变量和几种基本数据类型 ...
- R下载package的一些小问题
1.Error in install.packages : unable to create ‘C:/Users/???/Documents/R/win-library\3.5 采用管理员身份运行,先 ...
- R统计建模与R软件
教材目录 第一章 概率统计的基本知识 第二章 R软件的使用 第三章 数据描述性分析 第四章 参数估计 第五章 假设检验 第六章 回归分析 第七章 方差分析 第八章 应用多元分析(I) 第九章 应用多元 ...
- linux CentOS 权限问题修复(chmod 777 -R 或者chmod 755 -R问题修复)
我个人曾经有一次经历: 就是在修改文件夹权限的时候,本来该执行: #chmod 777 -R ./ 结果我漏掉了那个".";执行的命令是chmod 777 -R /. 这个命令一定 ...
随机推荐
- Vuex随笔
最近在项目中使用到了vuex,但是在配合vue使用时,也还是遇到了不少的问题,最终还是解决了问题,因此写一篇随笔来记录期间遇到的问题吧 项目概要: Vuex中所储存的的状态如下: Vue中:有一个ta ...
- dd命令的使用简介
dd命令: convert and copy a file 用法: dd if=/PATH/FROM/SRC of=/PATH/TO/DEST bs=#: block size, 复制单元大小 ...
- (转)混乱的First、Follow、Firstvt和Lastvt
转自: http://dongtq2010.blog.163.com/blog/static/1750224812011520113332714/ 学编译原理的时候,印象最深的莫过于这四个集合了,而且 ...
- oracle实现like多关键字查询
oracle实现like多关键字查询: select * from contract_info tt where 1=1 and REGEXP_LIKE(tt.contract_name,'关键字1| ...
- 【DevExpresss】3、LookUpEdit详解(转载)
[DevExpresss]3.LookUpEdit详解 哈,今天又用到了LookUpEdit控件,主要是用来实现模糊查询和自由输入功能,然而由于长时间没用了,一阵手忙脚乱的,这里把网上收集的一部分教程 ...
- 图片裁剪(cropper)后上传问题
最近工作需要处理头像裁剪以及上传,研究了几天,写点心得,提醒自己记住踩过的坑,能帮助别人当然更好. 功能基本就是这样: 这里需要注意的是:拿到需求后,不要急于直接上手,花费半个小时,甚至更长时间缕清整 ...
- JS 部分常见循环、分支、嵌套练习
图形题思路:1.确定图形一共几行,即为外层的循环次数2.确定每行有几种元素,代表有几个内层循环3.确定每种元素的个数,即为每个内层循环的次数 通常,找出每种元素个数,与行号的关系式,即为当前内层循 ...
- 最新的css3动画按钮效果
效果演示 插件下载
- jQuery修炼心得-DOM节点的删除
要移除页面上节点是开发者常见的操作,jQuery提供了几种不同的方法用来处理这个问题. 1.empty empty 顾名思义,清空方法,但是与删除又有点不一样,因为它只移除了 指定元素中的所有子节点. ...
- 在Visual Studio中入门F#
写在前面的话 个人由某方面的兴趣需要学习 F#,网络上有关F#的中文资料很少,微软官方有很不错的文档,但是很可惜的是绝大部分的章节都是英文的.个人是一位.NET爱好者,想自己将 F# 的官方文档翻译出 ...