apriori关联规则
挖掘数据集:贩物篮数据
频繁模式:频繁地出现在数据集中的模式,例如项集,子结构,子序列等
挖掘目标:频繁模式,频繁项集,关联规则等
关联规则:牛奶=>鸡蛋【支持度=2%,置信度=60%】
支持度:分析中的全部事务的2%同时贩买了牛奶和鸡蛋
置信度:贩买了牛奶的筒子有60%也贩买了鸡蛋
最小支持度阈值和最小置信度阈值:由挖掘者戒领域专家设定
项集:项(商品)的集合
k-项集:k个项组成的项集
频繁项集:满足最小支持度的项集,频繁k-项集一般记为L k
强关联规则:满足最小支持度阈值和最小置信度阈值的规则
apriori算法:
两步过程:找出所有频繁项集;由频繁项集产生强关联规则
具体挖掘步骤:
1.依据支持度找出所有频繁项集(频度)
2.依据置信度产生关联规则(强度)
原理:如果一个项集是频繁项集,那么它的所有子集也是频繁项集;按照这个原理的逆否命题——如果一个集合有不是频繁项集的子集,那么该集合一定不是频繁项集
算法工作流程(假设min_sup=2):



候选k项集剪枝生成频繁k项集,频繁k项集自连接生成候选(k+1)项集,注意:频繁k项集自连接的前提是前(k-1)项相同,否则过滤掉该项集,不予连接,例如上图中L2*L2时,没有生成{I1,I3,I5}的原因就是{I1,I3,I5}的一个2项子集{I3,I5}没有出现在频繁2项集列表中,没有出现{I2,I3,I4}{I2,I3,I5}的原因也在这里,连接这步是算法优化的重点,另外一个技巧是增大min_sup,过滤掉相当一部分项集,否则自连接生成的项集会撑爆内存。具体步骤说明如下:
步骤说明
扫描D,对每个候选项计数,生成候选1-项集C1
定义最小支持度阈值为2,从C1生成频繁1-项集L1
通过L1xL1生成候选2-项集C2
扫描D,对C2里每个项计数,生成频繁2-项集L2
计算L3xL3,利用apriori性质:频繁项集的子集必然是频繁的,我们可以删去一部分项
,从而得到C3,由C3再经过支持度计数生成L3
可见Apriori算法可以分成 连接,剪枝(1.扫描事务,去掉小于min_sup的项;2.去掉其子集不是频繁项集的项集) 两个步骤不断循环重复
由频繁项集提取关联规则:
例如:计算出的频繁项集{I1,I2,I5},提取规则步骤如下:

Apriori算法的瓶颈:
1.通过笛卡尔积自连接产生的组合项过多(只能人为提高min_sup减少频繁项集数目,这是以牺牲精度为代价的);
2.每次剪枝都需要去扫描事务数据库,而事务数据库包含难以计数之多的购物篮信息
总之:海量数据下,Apriori算法的时空复杂度都不容忽视。
空间复杂度:如果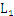 数量达到
数量达到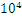 的量级,那么
的量级,那么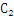 中的候选项将达到
中的候选项将达到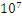 的量级。
的量级。
时间复杂度:每计算一次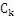 就需要扫描一遍数据库。
就需要扫描一遍数据库。
apriori关联规则的更多相关文章
- Python --深入浅出Apriori关联分析算法(二) Apriori关联规则实战
上一篇我们讲了关联分析的几个概念,支持度,置信度,提升度.以及如何利用Apriori算法高效地根据物品的支持度找出所有物品的频繁项集. Python --深入浅出Apriori关联分析算法(一) 这次 ...
- R语言中的Apriori关联规则的使用
1.下载Matrix和arules包 install.packages(c("Matrix","arules")) 2.载入引入Matrix和arules包 # ...
- apriori && fpgrowth:频繁模式与关联规则挖掘
已迁移到我新博客,阅读体验更佳apriori && fpgrowth:频繁模式与关联规则挖掘 详细代码我放在github上:click me 一.实验说明 1.1 任务描述 1.2 数 ...
- 数据挖掘:关联规则的apriori算法在weka的源码分析
相对于机器学习,关联规则的apriori算法更偏向于数据挖掘. 1) 测试文档中调用weka的关联规则apriori算法,如下 try { File file = new File("F:\ ...
- 顶尖数据挖掘辅助教学套件(TipDM-T6)产品白皮书
顶尖数据挖掘辅助教学套件 (TipDM-T6) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: ht ...
- 顶尖大数据挖掘实战平台(TipDM-H8)产品白皮书
顶尖大数据挖掘实战平台 (TipDM-H8) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: http: ...
- 机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho
机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho 总述 本书是 2014 ...
- R中常用数据挖掘算法包
数据挖掘主要分为4类,即预测.分类.聚类和关联,根据不同的挖掘目的选择相应的算法.下面对R语言中常用的数据挖掘包做一个汇总: 连续因变量的预测: stats包 lm函数,实现多元线性回归 stats包 ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
随机推荐
- 【Ganglia】集群监控系统搭建
参考博客 www.cnblogs.com/atomicbomb/p/6726119.html 操作系统 centos7 机器两台 一. 配置软件环境 操作步骤: 使用yum安装方式安装所需基础依赖包 ...
- 阿里云服务器(Windows)如何下载文件
背景:公司只有我一个技术,在我之前还有一个老技术,属于兼职状态,为了尽快熟悉公司网站及app项目情况,我联系了老技术,请他尽快将代码发给我,他说代码文件过大,问我能不能连上服务器下载.百度了很多,都不 ...
- Android学习之旅(一)
2017-02-27 今天开始,正式开启Android学习之旅,背景从事.Net平台开发快五年了,一直在用C#做Web开发. 前天选购了两本书:<Java 编程思想(第四版)>和<第 ...
- Quartz总结
前言 最近项目中有使用到Quartz,得空便总结总结,顺便记录一下这种设计模式,毕竟"好记性不如烂笔头". 搭建 pom文件: <dependency> <gro ...
- zetcode :: First programs in PyQt5
练习代码,详见网站 http://zetcode.com/gui/pyqt5/firstprograms/ import sys from PyQt5 import QtWidgets from Py ...
- JavaScrpt笔记之第三天
1.JavaScriot代码规范 代码规范通常包括以下几个方面: 变量和函数的命名规则 空格,缩进,注释的使用规则. 其他常用规范-- 规范的代码可以更易于阅读与维护. 2.命名规则 一般很多代码语言 ...
- Centos 7服务启动文件
在Centos 7中,如果要编辑一个脚本服务文件,并使用systemd进行管理,则必须将服务文件命名为/etc/systemd/system/*.service. service unit文件中的选项 ...
- Centos 6启动流程详解
author:JevonWei 版权声明:原创作品 Centos6 启动流程 POST开机自检 当按下电源键后,会启动ROM芯片中的CMOS程序检查CPU.内存等硬件设备是否正常运行,CMOS中的程序 ...
- java中的抛出异常throws与throw
throws与throw throws是方法可能抛出异常的声明.(用在声明方法时,表示该方法可能要抛出异常)语法:[(修饰符)](返回值类型)(方法名)([参数列表])[throws(异常类)]{.. ...
- crontab 各参数详解及如何查看日志记录
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt145 crontab各参数说明: crontab [-u user] [fi ...