apriori关联规则
挖掘数据集:贩物篮数据
频繁模式:频繁地出现在数据集中的模式,例如项集,子结构,子序列等
挖掘目标:频繁模式,频繁项集,关联规则等
关联规则:牛奶=>鸡蛋【支持度=2%,置信度=60%】
支持度:分析中的全部事务的2%同时贩买了牛奶和鸡蛋
置信度:贩买了牛奶的筒子有60%也贩买了鸡蛋
最小支持度阈值和最小置信度阈值:由挖掘者戒领域专家设定
项集:项(商品)的集合
k-项集:k个项组成的项集
频繁项集:满足最小支持度的项集,频繁k-项集一般记为L k
强关联规则:满足最小支持度阈值和最小置信度阈值的规则
apriori算法:
两步过程:找出所有频繁项集;由频繁项集产生强关联规则
具体挖掘步骤:
1.依据支持度找出所有频繁项集(频度)
2.依据置信度产生关联规则(强度)
原理:如果一个项集是频繁项集,那么它的所有子集也是频繁项集;按照这个原理的逆否命题——如果一个集合有不是频繁项集的子集,那么该集合一定不是频繁项集
算法工作流程(假设min_sup=2):



候选k项集剪枝生成频繁k项集,频繁k项集自连接生成候选(k+1)项集,注意:频繁k项集自连接的前提是前(k-1)项相同,否则过滤掉该项集,不予连接,例如上图中L2*L2时,没有生成{I1,I3,I5}的原因就是{I1,I3,I5}的一个2项子集{I3,I5}没有出现在频繁2项集列表中,没有出现{I2,I3,I4}{I2,I3,I5}的原因也在这里,连接这步是算法优化的重点,另外一个技巧是增大min_sup,过滤掉相当一部分项集,否则自连接生成的项集会撑爆内存。具体步骤说明如下:
步骤说明
扫描D,对每个候选项计数,生成候选1-项集C1
定义最小支持度阈值为2,从C1生成频繁1-项集L1
通过L1xL1生成候选2-项集C2
扫描D,对C2里每个项计数,生成频繁2-项集L2
计算L3xL3,利用apriori性质:频繁项集的子集必然是频繁的,我们可以删去一部分项
,从而得到C3,由C3再经过支持度计数生成L3
可见Apriori算法可以分成 连接,剪枝(1.扫描事务,去掉小于min_sup的项;2.去掉其子集不是频繁项集的项集) 两个步骤不断循环重复
由频繁项集提取关联规则:
例如:计算出的频繁项集{I1,I2,I5},提取规则步骤如下:

Apriori算法的瓶颈:
1.通过笛卡尔积自连接产生的组合项过多(只能人为提高min_sup减少频繁项集数目,这是以牺牲精度为代价的);
2.每次剪枝都需要去扫描事务数据库,而事务数据库包含难以计数之多的购物篮信息
总之:海量数据下,Apriori算法的时空复杂度都不容忽视。
空间复杂度:如果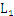 数量达到
数量达到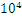 的量级,那么
的量级,那么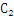 中的候选项将达到
中的候选项将达到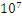 的量级。
的量级。
时间复杂度:每计算一次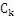 就需要扫描一遍数据库。
就需要扫描一遍数据库。
apriori关联规则的更多相关文章
- Python --深入浅出Apriori关联分析算法(二) Apriori关联规则实战
上一篇我们讲了关联分析的几个概念,支持度,置信度,提升度.以及如何利用Apriori算法高效地根据物品的支持度找出所有物品的频繁项集. Python --深入浅出Apriori关联分析算法(一) 这次 ...
- R语言中的Apriori关联规则的使用
1.下载Matrix和arules包 install.packages(c("Matrix","arules")) 2.载入引入Matrix和arules包 # ...
- apriori && fpgrowth:频繁模式与关联规则挖掘
已迁移到我新博客,阅读体验更佳apriori && fpgrowth:频繁模式与关联规则挖掘 详细代码我放在github上:click me 一.实验说明 1.1 任务描述 1.2 数 ...
- 数据挖掘:关联规则的apriori算法在weka的源码分析
相对于机器学习,关联规则的apriori算法更偏向于数据挖掘. 1) 测试文档中调用weka的关联规则apriori算法,如下 try { File file = new File("F:\ ...
- 顶尖数据挖掘辅助教学套件(TipDM-T6)产品白皮书
顶尖数据挖掘辅助教学套件 (TipDM-T6) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: ht ...
- 顶尖大数据挖掘实战平台(TipDM-H8)产品白皮书
顶尖大数据挖掘实战平台 (TipDM-H8) 产 品 说 明 书 广州泰迪智能科技有限公司 版权所有 地址: 广州市经济技术开发区科学城232号 网址: http: ...
- 机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho
机器学习系统设计(Building Machine Learning Systems with Python)- Willi Richert Luis Pedro Coelho 总述 本书是 2014 ...
- R中常用数据挖掘算法包
数据挖掘主要分为4类,即预测.分类.聚类和关联,根据不同的挖掘目的选择相应的算法.下面对R语言中常用的数据挖掘包做一个汇总: 连续因变量的预测: stats包 lm函数,实现多元线性回归 stats包 ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
随机推荐
- win10 永久激活 命令行方式
现在我们可以看下当前系统的激活状态,查看方法"WIN+R"打开运行对话框,输入命令slmgr.vbs -xpr,点击确定,这样可以查看到当前系统的激活信息.大家可以发现,虽然小编系 ...
- MySql_5-7安装教程
MySql_5-7安装教程... --------------------------------- 安装过成参考的文档: 参考网址:http://jingyan.baidu.com/article/ ...
- SpringMVC简单配置
SpringMVC简单配置 一.eclipse安装Spring插件 打开help下的Install New Software 点击add,location中输入http://dist.springso ...
- POI处理Excel中的日期数据类型
在POI处理Excel中的日期类型的单元格时,如果仅仅是判断它是否为日期类型的话,最终会以NUMERIC类型来处理. 正确的处理方法是先判断单元格 的类型是否则NUMERIC类型, 然后再判断单元格是 ...
- 说说 DWRUtil
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcytp27 说说 DWRUtil 比如我们从服务器端获得了一个citylist的数 ...
- javascript中this的指向
作为一个前端小白在开发中对于this的指向问题有时候总是会模糊,于是花时间研究了一番. 首先this是JS的关键字,this是js函数在运行是生成的一个内部对象,生成的这个this只能在函数内部使用. ...
- tkinter第四章 输入框,校对
#最简单的输入框 import tkinter as tk root = tk.Tk() e = tk.Entry(root)#输入框的类 e.pack() e.delete(0,tk.END)#把输 ...
- cmake命令收集
cmake中一些预定义变量 PROJECT_SOURCE_DIR 工程的根目录 PROJECT_BINARY_DIR 运行cmake命令的目录,通常是${PROJECT_SOURCE_DIR}/bui ...
- 英语app分析
Andorid 版本 第一部分 调研, 评测 搜索了一下必应跑出来的是微软必应,在印象中微软的产品都是很可靠地.安装之后对它的 排版字体图片等不是很喜欢,感觉有道词典会更亲切一点. 必应 ...
- 【Beta】阶段 第四次Daily Scrum Meeting
每日任务 1.本次会议为第四次 Meeting会议: 2.本次会议在周四下午16:40,课间休息时间在陆大楼召开,召开本次会议为10分钟. 一.今日站立式会议照片 二.每个人的工作 (有work it ...