大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵。
一、简介
Hadoop的平台搭建,设置为三种搭建方式,第一种是“单节点安装”,这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合初学者快速搭建;第二种是“伪分布式安装”,这种安装方式安装了Hadoop的核心组件,但是并没有真正展示出Hadoop的技术优势,不适用于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装方式安装了Hadoop的所有功能,适用于开发,提供了Hadoop的所有功能。
二、介绍Apache Hadoop 2.7.3
该系列文章使用Hadoop 2.7.3搭建的大数据平台,所以先简单介绍一下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是一个2.x.y发行版本中的一个次要版本,是基于2.7.2稳定版的一个维护版本,开发中不建议使用该版本,可以使用稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下:
1、common:
①、使用HTTP代理服务器时的身份验证改进。当使用代理服务器访问WebHDFS时,能发挥很好的作用。
②、一个新的Hadoop指标接收器,允许直接写入Graphite。
③、与Hadoop兼容文件系统(HCFS)相关的规范工作。
2、HDFS:
①、支持POSIX风格的文件系统扩展属性。
②、使用OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS网关接收到一些可支持性改进和错误修复。Hadoop端口映射程序不再需要运行网关,网关现在可以拒绝来自非特权端口的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进行了现代化改造。
3、yarn:
①、YARN的REST API现在支持写/修改操作。用户可以通过REST API提交和删除应用程序。
②、用于存储应用程序的通用和特定于应用程序的信息的YARN中的时间轴存储支持通过Kerberos进行身份验证。
④、Fair Scheduler支持动态分层用户队列,在任何指定的父队列下,在运行时动态创建用户队列。
三、先决条件
1、安装Hadoop之前需要做一些准备工作
①、支持的平台:我选用Linux操作系统centos7.2 64位
a. Linux:Hadoop是针对Linux系统研发的,能够很好的与Linux系统融合,借助Linux系统能够让Hadoop更加的稳定、健壮且性能更佳。
b. Windows:Hadoop也能安装在Windows操作系统上,不过,需要借助Cygwin工具,具体安装请参看https://wiki.apache.org/hadoop/Hadoop2OnWindows。
②、必须安装Java:Hadoop是利用java开发的开源软件,所以需要安装java。我使用的是1.8.0_131版本:

③、ssh:必须安装ssh,并且sshd必须正在运行才能使用管理远程Hadoop守护程序的Hadoop脚本。
2、下载Apache Hadoop2.7.3
①、下载地址:http://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/,打开之后如下所示:下载 hadoop-2.7.3.tar.gz
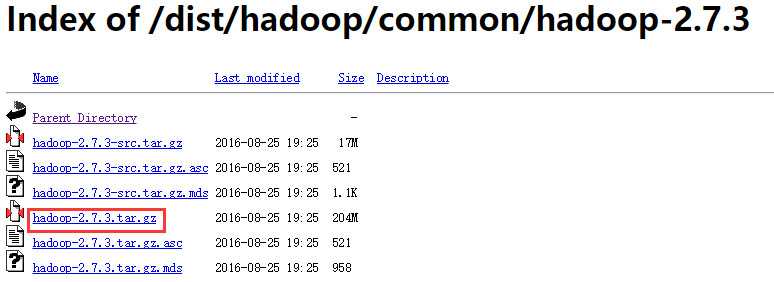
②、将下载好的 Hadoop tar 包放在 /root/software 下,利用tar -zxvf hadoop-2.7.3.tar.gz解压,解压之后将tar包移到其他目录下(不移也可以,反正我移了,后期操作的时候看着清爽点)
3、启动Hadoop
①、编辑hadoop-env.sh文件
进入解压好的hadoop文件夹,在etc/hadoop路径下(即全路径:/root/software/hadoop-2.7.3/etc/hadoop)找到hadoop-env.sh文件:

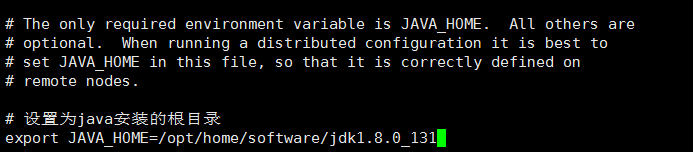
打开hadoop-env.sh文件,找到export JAVA_HOME=${JAVA_HOME},修改为java安装的根目录:
#设置为java安装的根目录
export JAVA_HOME=/opt/home/software/jdk1.8.0_131
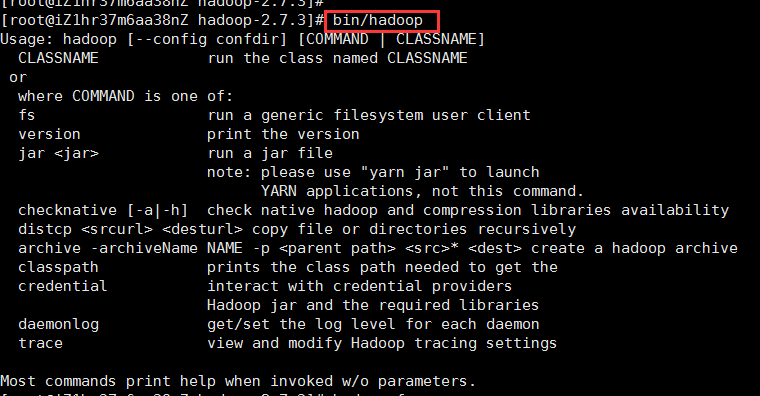
②、退回到hadoop目录下,即/root/software/hadoop-2.7.3路径下,使用命令bin/hadoop,若出现以下提示,则hadoop安装成功:
注:学习hadoop需要有一定的Linux基础和java基础,如没有相应基础的,看该博文会显得比较吃力。建议具有Linux和java基础再学习hadoop。
四、独立安装
hadoop有三种模式的安装,分别为独立安装、伪分布式安装、全分布式安装。独立安装是最简单安装,即将hadoop安装在一台机器上,这种方式适合学习、调试,也是伪分布式安装/全分布式安装的基础。在上述步骤中,如果你使用bin/hadoop出现了提示符,就代表我们已经以独立安装的方式将hadoop安装在我们的Linux系统上了。
五、伪分布式安装
上述已经介绍了独立模式的安装,且hadoop已经以独立模式安装成功,不过,hadoop独立模式并没有任何守护进程,所有程序都在同一个JVM上执行,在独立模式下测试和调试MapReduce程序很方便,但hadoop不仅仅如此。伪分布式安装是在独立安装的基础上进行相应的配置而成,所谓伪分布式安装就是在一台机器上模拟一个小规模的集群,相较于独立模式,伪分布式模式下可以使用yarn、HDFS等。真正全分布模式下运行的hadoop,是需要在多台机器(至少3台)上部署hadoop来达到集群的效果。
目前就只有一台机器,所以可以搭建伪分布模式的hadoop,接下来就介绍怎么以伪分布模式安装hadoop。
1、配置core-site.xml和hdfs-site.xml
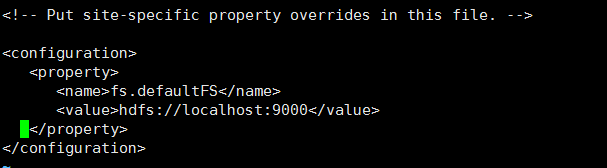
①、配置core-site.xml:该配置文件在etc/hadoop路径下,即/root/software/hadoop-2.7.3/etc/hadoop路径下,在<configuration>节点下添加如下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
如图:这是设置hadoop 默认文件系统的位置
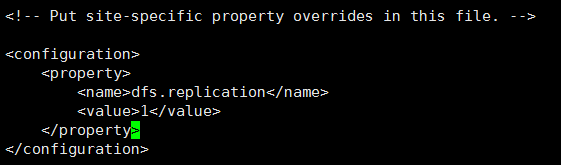
②、配置hdfs-site.xml:该配置文件在etc/hadoop路径下,即/root/software/hadoop-2.7.3/etc/hadoop路径下,在<configuration>节点下添加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
如图:这是设置存储到HDFS文件系统中的文件需要复制的份数,在全分布模式下,每上传一个文件到HDFS文件系统中,HDFS都会根据设置的复制份数把文件复制对应的份数并分散存储到不同的节点上,这种机制保证了HDFS文件的容灾性、容错性,一般在全分布模式下设置为3份,由于我们目前是伪分布模式,只有一个节点(一台机器),所以存储一份即可。
2、安装ssh
①、先检查一下Linux系统上是否安装了ssh,使用以下命令查看本地是否已经安装ssh:
ssh
如果安装ssh,会出现如下图所示:
②、检查ssh到本地是否需要密码,使用如下命令:如果不需要输入密码,则ssh配置成功,否则进入第③步。
ssh localhost
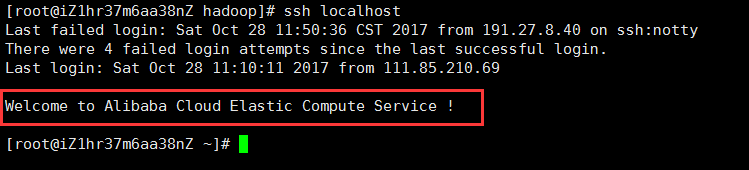
③、如果使用ssh localhost需要输入密码,执行以下命令配置ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
如上命令执行成功之后,再执行ssh localhost命令,如果不需要密码且出现以下提示,则ssh配置成功:
3、配置MapReduce
①、使用如下命令格式化文件系统:
bin/hdfs namenode -format
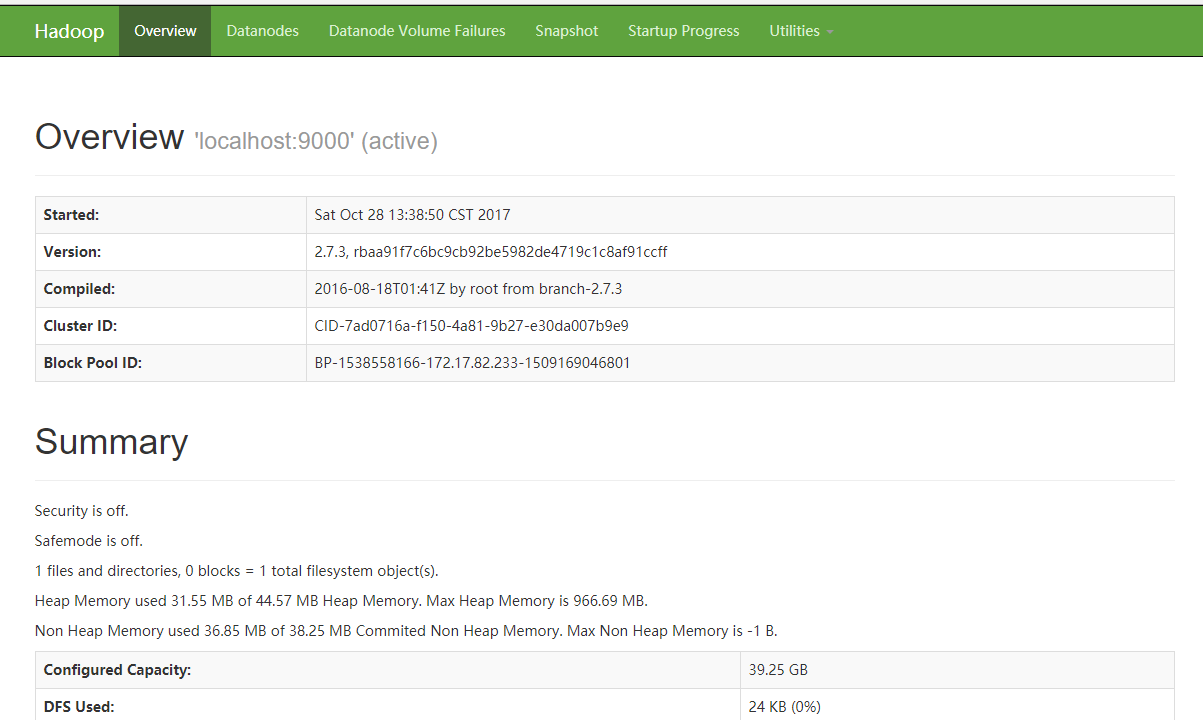
②、使用如下命令启动NameNode守护进程和DataNode守护进程:
sbin/start-dfs.sh
执行上述命令之后,在浏览器中输入http://IP:50070,IP是你安装hadoop机器的IP,出现如下图界面,代表MapReduce配置成功:
4、在单节点上配置yarn:以下的步骤在上述所有操作都执行成功的前提下进行。
①、配置mapred-site.xml:mapred-site.xml文件同样存放在/root/software/hadoop-2.7.3/etc/hadoop路径下,默认该路径下并不存在mapred-site.xml文件,而是存在mapred-site.xml.template文件,复制一份mapred-site.xml.template文件,并改名为mapred-site.xml即可,在<configuration>节点下添加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
②、配置yarn-site.xml:yarn-site.xml文件同样存放在/root/software/hadoop-2.7.3/etc/hadoop路径下,在<configuration>节点下添加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
③、使用如下命令启动ResourceManager守护程序和NodeManager守护程序
sbin/start-yarn.sh
④、在浏览器地址栏输入地址:http://101.200.40.240:8088,如果出现如下界面,代表配置单节点yarn成功:
至此,伪分布式hadoop安装成功,在接下来的博文中,会介绍hadoop的使用以及hadoop生态部分项目的使用。
大数据Hadoop学习之搭建Hadoop平台(2.1)的更多相关文章
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 【大数据系列】windows搭建hadoop开发环境
一.安装JDK配置环境变量 已经安装略过 二.安装eclipse 已经安装略过 三.安装Ant 1.下载http://ant.apache.org/bindownload.cgi 2.解压 3.配置A ...
- 大数据开发学习之构建Hadoop集群-(0)
有多种方式来获取hadoop集群,包括从其他人获取或是自行搭建专属集群,抑或是从Cloudera Manager 或apach ambari等管理工具来构建hadoop集群等,但是由自己搭建则可以了解 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据攻城狮之Hadoop伪分布式篇
对于初学大数据的萌新来说,初次接触Hadoop伪分布式搭建的同学可能是一脸萌笔的,那么这一次小编就手把手的教大家在centos7下搭建Hadoop伪分布式. 底层环境: VMware Workstat ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
随机推荐
- Java之路上,让我们Stand Up Again
在开始之前,先发表一下个人想法吧. 在读书的时候每天忙的不可开交,也就没有了所谓的自由,突然参加工作,传统的朝八晚五,标准的八小时工作制,每天都是两点一线,工作中涉及商业机密,公司的东西也不能带回家, ...
- 48、mysql补充
一 视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的 ...
- python for循环巧妙运用(迭代、列表生成式)
200 ? "200px" : this.width)!important;} --> 介绍 我们可以通过for循环来迭代list.tuple.dict.set.字符串,di ...
- Git安装和使用(谨记)
刚开始用git的小白适用,,转自http://www.cnblogs.com/qijunjun/p/7137207.html 实际项目开发中,我们经常会用一些版本控制器来托管自己的代码,今天就来总结下 ...
- lua中易混淆函数
lua中易混淆的函数 ipairs和pairs: ipairs只能顺序遍历table,遇到key不是数字就会退出 pairs可以遍历table中所有元素 ----------------------- ...
- jQueryUI Autocomplete插件使用入门教程(最新版)---------转载
前言: jQuery,无需多作介绍,相信各位读者都应该接触或使用过了.jQuery UI,简而言之,它是一个基于jQuery的前端UI框架.我们可以使用jQuery + jQuery UI非常简单方便 ...
- Docker(十二):Docker集群管理之Compose
1.Compose安装 curl -L https://github.com/docker/compose/releases/download/1.1.0/docker-compose-`uname ...
- Python学习(一):编写购物车
1.购物车流程图: 2.代码实现: #!/usr/bin/env python #coding=utf-8 ChoiceOne =''' 1.查看余额 2.购物 3.退出 ''' ChoiceTwo ...
- Redis分布式集群搭建
Redis集群架构图 上图蓝色为redis集群的节点. 节点之间通过ping命令来测试连接是否正常,节点之间没有主区分,连接到任何一个节点进行操作时,都可能会转发到其他节点. 1.Redis的容错机制 ...
- Java解析word,获取文档中图片位置
前言(背景介绍): Apache POI是Apache基金会下一个开源的项目,用来处理office系列的文档,能够创建和解析word.excel.ppt格式的文档. 其中对word文档的处理有两个技术 ...